Tuning Tensor Operators on NNI¶
Overview¶
Abundant applications raise the demands of training and inference deep neural networks (DNNs) efficiently on diverse hardware platforms ranging from cloud servers to embedded devices. Moreover, computational graph-level optimization of deep neural network, like tensor operator fusion, may introduce new tensor operators. Thus, manually optimized tensor operators provided by hardware-specific libraries have limitations in terms of supporting new hardware platforms or supporting new operators, so automatically optimizing tensor operators on diverse hardware platforms is essential for large-scale deployment and application of deep learning technologies in the real-world problems.
Tensor operator optimization is substantially a combinatorial optimization problem. The objective function is the performance of a tensor operator on specific hardware platform, which should be maximized with respect to the hyper-parameters of corresponding device code, such as how to tile a matrix or whether to unroll a loop. Unlike many typical problems of this type, such as travelling salesman problem, the objective function of tensor operator optimization is a black box and expensive to sample. One has to compile a device code with a specific configuration and run it on real hardware to get the corresponding performance metric. Therefore, a desired method for optimizing tensor operators should find the best configuration with as few samples as possible.
The expensive objective function makes solving tensor operator optimization problem with traditional combinatorial optimization methods, for example, simulated annealing and evolutionary algorithms, almost impossible. Although these algorithms inherently support combinatorial search spaces, they do not take sample-efficiency into account, thus thousands of or even more samples are usually needed, which is unacceptable when tuning tensor operators in product environments. On the other hand, sequential model based optimization (SMBO) methods are proved sample-efficient for optimizing black-box functions with continuous search spaces. However, when optimizing ones with combinatorial search spaces, SMBO methods are not as sample-efficient as their continuous counterparts, because there is lack of prior assumptions about the objective functions, such as continuity and differentiability in the case of continuous search spaces. For example, if one could assume an objective function with a continuous search space is infinitely differentiable, a Gaussian process with a radial basis function (RBF) kernel could be used to model the objective function. In this way, a sample provides not only a single value at a point but also the local properties of the objective function in its neighborhood or even global properties, which results in a high sample-efficiency. In contrast, SMBO methods for combinatorial optimization suffer poor sample-efficiency due to the lack of proper prior assumptions and surrogate models which can leverage them.
OpEvo is recently proposed for solving this challenging problem. It efficiently explores the search spaces of tensor operators by introducing a topology-aware mutation operation based on q-random walk distribution to leverage the topological structures over the search spaces. Following this example, you can use OpEvo to tune three representative types of tensor operators selected from two popular neural networks, BERT and AlexNet. Three comparison baselines, AutoTVM, G-BFS and N-A2C, are also provided. Please refer to OpEvo: An Evolutionary Method for Tensor Operator Optimization for detailed explanation about these algorithms.
Environment Setup¶
We prepared a dockerfile for setting up experiment environments. Before starting, please make sure the Docker daemon is running and the driver of your GPU accelerator is properly installed. Enter into the example folder examples/trials/systems/opevo and run below command to build and instantiate a Docker image from the dockerfile.
# if you are using Nvidia GPU
make cuda-env
# if you are using AMD GPU
make rocm-env
Run Experiments:¶
Three representative kinds of tensor operators, matrix multiplication, batched matrix multiplication and 2D convolution, are chosen from BERT and AlexNet, and tuned with NNI. The Trial code for all tensor operators is /root/compiler_auto_tune_stable.py, and Search Space files and config files for each tuning algorithm locate in /root/experiments/, which are categorized by tensor operators. Here /root refers to the root of the container.
For tuning the operators of matrix multiplication, please run below commands from /root:
# (N, K) x (K, M) represents a matrix of shape (N, K) multiplies a matrix of shape (K, M)
# (512, 1024) x (1024, 1024)
# tuning with OpEvo
nnictl create --config experiments/mm/N512K1024M1024/config_opevo.yml
# tuning with G-BFS
nnictl create --config experiments/mm/N512K1024M1024/config_gbfs.yml
# tuning with N-A2C
nnictl create --config experiments/mm/N512K1024M1024/config_na2c.yml
# tuning with AutoTVM
OP=matmul STEP=512 N=512 M=1024 K=1024 P=NN ./run.s
# (512, 1024) x (1024, 4096)
# tuning with OpEvo
nnictl create --config experiments/mm/N512K1024M4096/config_opevo.yml
# tuning with G-BFS
nnictl create --config experiments/mm/N512K1024M4096/config_gbfs.yml
# tuning with N-A2C
nnictl create --config experiments/mm/N512K1024M4096/config_na2c.yml
# tuning with AutoTVM
OP=matmul STEP=512 N=512 M=1024 K=4096 P=NN ./run.sh
# (512, 4096) x (4096, 1024)
# tuning with OpEvo
nnictl create --config experiments/mm/N512K4096M1024/config_opevo.yml
# tuning with G-BFS
nnictl create --config experiments/mm/N512K4096M1024/config_gbfs.yml
# tuning with N-A2C
nnictl create --config experiments/mm/N512K4096M1024/config_na2c.yml
# tuning with AutoTVM
OP=matmul STEP=512 N=512 M=4096 K=1024 P=NN ./run.sh
For tuning the operators of batched matrix multiplication, please run below commands from /root:
# batched matrix with batch size 960 and shape of matrix (128, 128) multiplies batched matrix with batch size 960 and shape of matrix (128, 64)
# tuning with OpEvo
nnictl create --config experiments/bmm/B960N128K128M64PNN/config_opevo.yml
# tuning with AutoTVM
OP=batch_matmul STEP=512 B=960 N=128 K=128 M=64 P=NN ./run.sh
# batched matrix with batch size 960 and shape of matrix (128, 128) is transposed first and then multiplies batched matrix with batch size 960 and shape of matrix (128, 64)
# tuning with OpEvo
nnictl create --config experiments/bmm/B960N128K128M64PTN/config_opevo.yml
# tuning with AutoTVM
OP=batch_matmul STEP=512 B=960 N=128 K=128 M=64 P=TN ./run.sh
# batched matrix with batch size 960 and shape of matrix (128, 64) is transposed first and then right multiplies batched matrix with batch size 960 and shape of matrix (128, 64).
# tuning with OpEvo
nnictl create --config experiments/bmm/B960N128K64M128PNT/config_opevo.yml
# tuning with AutoTVM
OP=batch_matmul STEP=512 B=960 N=128 K=64 M=128 P=NT ./run.sh
For tuning the operators of 2D convolution, please run below commands from /root:
# image tensor of shape (512, 3, 227, 227) convolves with kernel tensor of shape (64, 3, 11, 11) with stride 4 and padding 0
# tuning with OpEvo
nnictl create --config experiments/conv/N512C3HW227F64K11ST4PD0/config_opevo.yml
# tuning with AutoTVM
OP=convfwd_direct STEP=512 N=512 C=3 H=227 W=227 F=64 K=11 ST=4 PD=0 ./run.sh
# image tensor of shape (512, 64, 27, 27) convolves with kernel tensor of shape (192, 64, 5, 5) with stride 1 and padding 2
# tuning with OpEvo
nnictl create --config experiments/conv/N512C64HW27F192K5ST1PD2/config_opevo.yml
# tuning with AutoTVM
OP=convfwd_direct STEP=512 N=512 C=64 H=27 W=27 F=192 K=5 ST=1 PD=2 ./run.sh
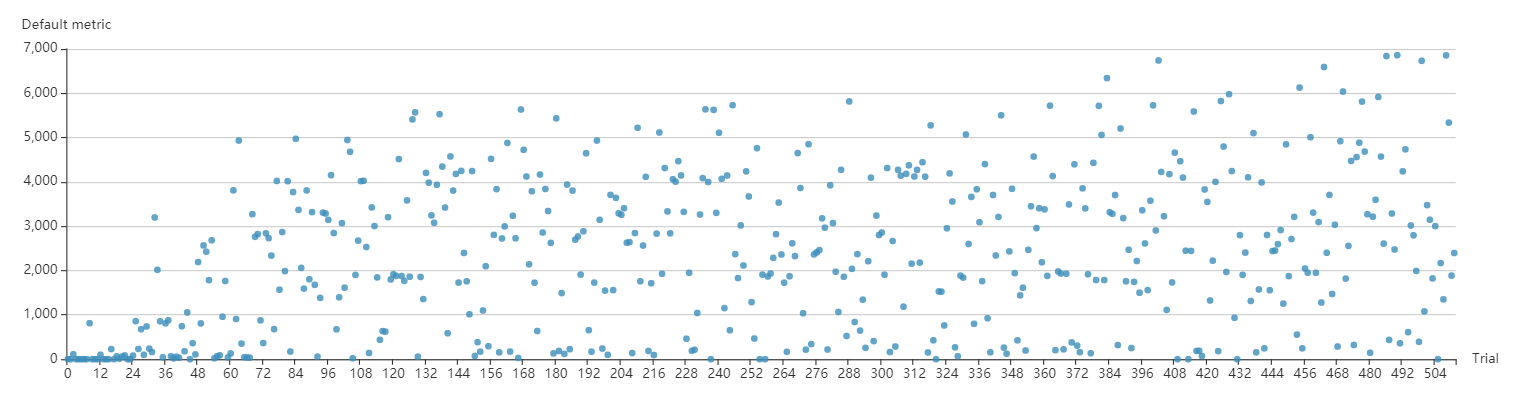
Please note that G-BFS and N-A2C are only designed for tuning tiling schemes of multiplication of matrices with only power of 2 rows and columns, so they are not compatible with other types of configuration spaces, thus not eligible to tune the operators of batched matrix multiplication and 2D convolution. Here, AutoTVM is implemented by its authors in the TVM project, so the tuning results are printed on the screen rather than reported to NNI manager. The port 8080 of the container is bind to the host on the same port, so one can access the NNI Web UI through host_ip_addr:8080 and monitor tuning process as below screenshot.
Citing OpEvo¶
If you feel OpEvo is helpful, please consider citing the paper as follows:
@misc{gao2020opevo,
title={OpEvo: An Evolutionary Method for Tensor Operator Optimization},
author={Xiaotian Gao and Cui Wei and Lintao Zhang and Mao Yang},
year={2020},
eprint={2006.05664},
archivePrefix={arXiv},
primaryClass={cs.LG}
}