Guide: Using NAS on NNI¶
Contents
Note
The APIs are in an experimental stage. The current programing interface is subject to change.
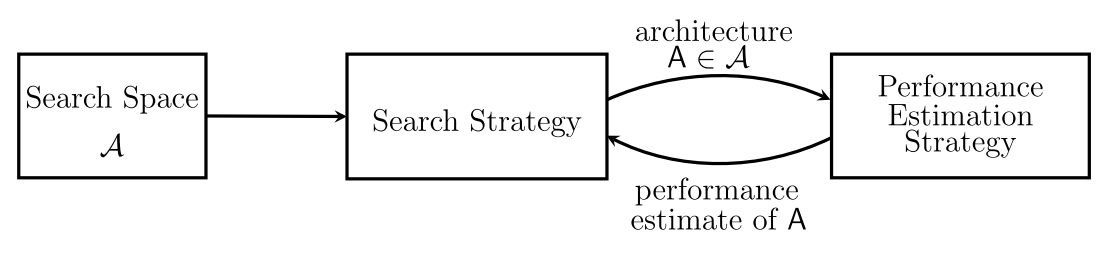
Modern Neural Architecture Search (NAS) methods usually incorporate three dimensions: search space, search strategy, and performance estimation strategy. Search space often contains a limited number of neural network architectures to explore, while the search strategy samples architectures from search space, gets estimations of their performance, and evolves itself. Ideally, the search strategy should find the best architecture in the search space and report it to users. After users obtain the “best architecture”, many methods use a “retrain step”, which trains the network with the same pipeline as any traditional model.
Implement a Search Space¶
Assuming we’ve got a baseline model, what should we do to be empowered with NAS? Take MNIST on PyTorch as an example, the code might look like this:
from nni.nas.pytorch import mutables
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = mutables.LayerChoice([
nn.Conv2d(1, 32, 3, 1),
nn.Conv2d(1, 32, 5, 3)
]) # try 3x3 kernel and 5x5 kernel
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# ... same as original ...
return output
The example above adds an option of choosing conv5x5 at conv1. The modification is as simple as declaring a LayerChoice with the original conv3x3 and a new conv5x5 as its parameter. That’s it! You don’t have to modify the forward function in any way. You can imagine conv1 as any other module without NAS.
So how about the possibilities of connections? This can be done using InputChoice. To allow for a skip connection on the MNIST example, we add another layer called conv3. In the following example, a possible connection from conv2 is added to the output of conv3.
from nni.nas.pytorch import mutables
class Net(nn.Module):
def __init__(self):
# ... same ...
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv3 = nn.Conv2d(64, 64, 1, 1)
# declaring that there is exactly one candidate to choose from
# search strategy will choose one or None
self.skipcon = mutables.InputChoice(n_candidates=1)
# ... same ...
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x0 = self.skipcon([x]) # choose one or none from [x]
x = self.conv3(x)
if x0 is not None: # skipconnection is open
x += x0
x = F.max_pool2d(x, 2)
# ... same ...
return output
Input choice can be thought of as a callable module that receives a list of tensors and outputs the concatenation/sum/mean of some of them (sum by default), or None if none is selected. Like layer choices, input choices should be initialized in __init__ and called in forward. We will see later that this is to allow search algorithms to identify these choices and do necessary preparations.
LayerChoice and InputChoice are both mutables. Mutable means “changeable”. As opposed to traditional deep learning layers/modules which have fixed operation types once defined, models with mutable are essentially a series of possible models.
Users can specify a key for each mutable. By default, NNI will assign one for you that is globally unique, but in case users want to share choices (for example, there are two LayerChoices with the same candidate operations and you want them to have the same choice, i.e., if first one chooses the i-th op, the second one also chooses the i-th op), they can give them the same key. The key marks the identity for this choice and will be used in the dumped checkpoint. So if you want to increase the readability of your exported architecture, manually assigning keys to each mutable would be a good idea. For advanced usage on mutables, see Mutables.
Use a Search Algorithm¶
Aside from using a search space, there are at least two other ways users can do search. One runs NAS distributedly, which can be as naive as enumerating all the architectures and training each one from scratch, or can involve leveraging more advanced technique, such as SMASH, ENAS, DARTS, FBNet, ProxylessNAS, SPOS, Single-Path NAS, Understanding One-shot and GDAS. Since training many different architectures is known to be expensive, another family of methods, called one-shot NAS, builds a supernet containing every candidate in the search space as its subnetwork, and in each step, a subnetwork or combination of several subnetworks is trained.
Currently, several one-shot NAS methods are supported on NNI. For example, DartsTrainer, which uses SGD to train architecture weights and model weights iteratively, and ENASTrainer, which uses a controller to train the model. New and more efficient NAS trainers keep emerging in research community and some will be implemented in future releases of NNI.
One-Shot NAS¶
Each one-shot NAS algorithm implements a trainer, for which users can find usage details in the description of each algorithm. Here is a simple example, demonstrating how users can use EnasTrainer.
# this is exactly same as traditional model training
model = Net()
dataset_train = CIFAR10(root="./data", train=True, download=True, transform=train_transform)
dataset_valid = CIFAR10(root="./data", train=False, download=True, transform=valid_transform)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), 0.05, momentum=0.9, weight_decay=1.0E-4)
# use NAS here
def top1_accuracy(output, target):
# this is the function that computes the reward, as required by ENAS algorithm
batch_size = target.size(0)
_, predicted = torch.max(output.data, 1)
return (predicted == target).sum().item() / batch_size
def metrics_fn(output, target):
# metrics function receives output and target and computes a dict of metrics
return {"acc1": reward_accuracy(output, target)}
from nni.nas.pytorch import enas
trainer = enas.EnasTrainer(model,
loss=criterion,
metrics=metrics_fn,
reward_function=top1_accuracy,
optimizer=optimizer,
batch_size=128
num_epochs=10, # 10 epochs
dataset_train=dataset_train,
dataset_valid=dataset_valid,
log_frequency=10) # print log every 10 steps
trainer.train() # training
trainer.export(file="model_dir/final_architecture.json") # export the final architecture to file
Users can directly run their training file through python3 train.py without nnictl. After training, users can export the best one of the found models through trainer.export().
Normally, the trainer exposes a few arguments that you can customize. For example, the loss function, the metrics function, the optimizer, and the datasets. These should satisfy most usages needs and we do our best to make sure our built-in trainers work on as many models, tasks, and datasets as possible. But there is no guarantee. For example, some trainers have the assumption that the task is a classification task; some trainers might have a different definition of “epoch” (e.g., an ENAS epoch = some child steps + some controller steps); most trainers do not have support for distributed training: they won’t wrap your model with DataParallel or DistributedDataParallel to do that. So after a few tryouts, if you want to actually use the trainers on your very customized applications, you might need to customize your trainer.
Furthermore, one-shot NAS can be visualized with our NAS UI. See more details.
Distributed NAS¶
Neural architecture search was originally executed by running each child model independently as a trial job. We also support this searching approach, and it naturally fits within the NNI hyper-parameter tuning framework, where Tuner generates child models for the next trial and trials run in the training service.
To use this mode, there is no need to change the search space expressed with the NNI NAS API (i.e., LayerChoice, InputChoice, MutableScope). After the model is initialized, apply the function get_and_apply_next_architecture on the model. One-shot NAS trainers are not used in this mode. Here is a simple example:
model = Net()
# get the chosen architecture from tuner and apply it on model
get_and_apply_next_architecture(model)
train(model) # your code for training the model
acc = test(model) # test the trained model
nni.report_final_result(acc) # report the performance of the chosen architecture
The search space should be generated and sent to Tuner. As with the NNI NAS API, the search space is embedded in the user code. Users can use “nnictl ss_gen” to generate the search space file. Then put the path of the generated search space in the field searchSpacePath of config.yml. The other fields in config.yml can be filled by referring this tutorial.
You can use the NNI tuners to do the search. Currently, only PPO Tuner supports NAS search spaces.
We support a standalone mode for easy debugging, where you can directly run the trial command without launching an NNI experiment. This is for checking whether your trial code can correctly run. The first candidate(s) are chosen for LayerChoice and InputChoice in this standalone mode.
A complete example can be found here.
Retrain with Exported Architecture¶
After the search phase, it’s time to train the found architecture. Unlike many open-source NAS algorithms who write a whole new model specifically for retraining. We found that the search model and retraining model are usually very similar, and therefore you can construct your final model with the exact same model code. For example
model = Net()
apply_fixed_architecture(model, "model_dir/final_architecture.json")
The JSON is simply a mapping from mutable keys to choices. Choices can be expressed in:
- A string: select the candidate with corresponding name.
- A number: select the candidate with corresponding index.
- A list of string: select the candidates with corresponding names.
- A list of number: select the candidates with corresponding indices.
- A list of boolean values: a multi-hot array.
For example,
{
"LayerChoice1": "conv5x5",
"LayerChoice2": 6,
"InputChoice3": ["layer1", "layer3"],
"InputChoice4": [1, 2],
"InputChoice5": [false, true, false, false, true]
}
After applying, the model is then fixed and ready for final training. The model works as a single model, and unused parameters and modules are pruned.
Also, refer to DARTS for code exemplifying retraining.