Architecture Overview¶
NNI (Neural Network Intelligence) is a toolkit to help users design and tune machine learning models (e.g., hyperparameters), neural network architectures, or complex system’s parameters, in an efficient and automatic way. NNI has several appealing properties: ease-of-use, scalability, flexibility, and efficiency.
Ease-of-use: NNI can be easily installed through python pip. Only several lines need to be added to your code in order to use NNI’s power. You can use both the commandline tool and WebUI to work with your experiments.
Scalability: Tuning hyperparameters or the neural architecture often demands a large number of computational resources, while NNI is designed to fully leverage different computation resources, such as remote machines, training platforms (e.g., OpenPAI, Kubernetes). Hundreds of trials could run in parallel by depending on the capacity of your configured training platforms.
Flexibility: Besides rich built-in algorithms, NNI allows users to customize various hyperparameter tuning algorithms, neural architecture search algorithms, early stopping algorithms, etc. Users can also extend NNI with more training platforms, such as virtual machines, kubernetes service on the cloud. Moreover, NNI can connect to external environments to tune special applications/models on them.
Efficiency: We are intensively working on more efficient model tuning on both the system and algorithm level. For example, we leverage early feedback to speedup the tuning procedure.
The figure below shows high-level architecture of NNI.
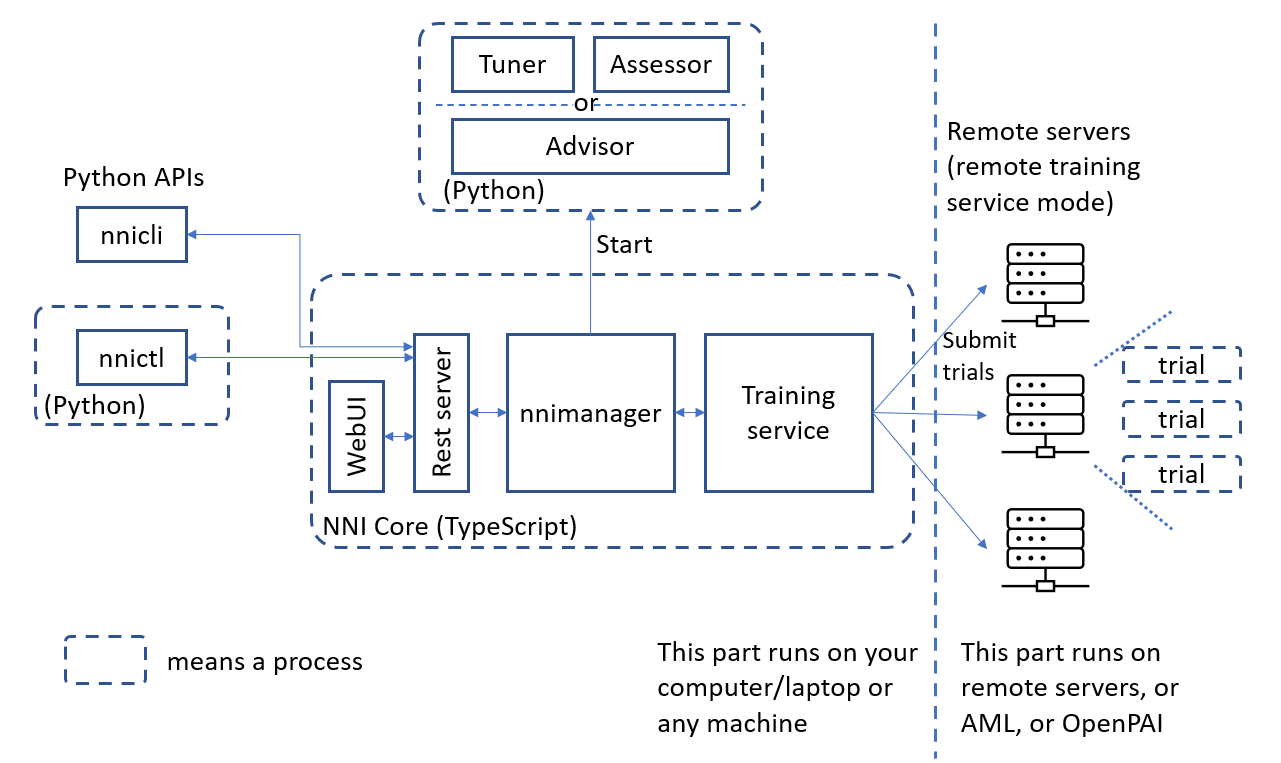
Key Concepts¶
Experiment: One task of, for example, finding out the best hyperparameters of a model, finding out the best neural network architecture, etc. It consists of trials and AutoML algorithms.
Search Space: The feasible region for tuning the model. For example, the value range of each hyperparameter.
Configuration: An instance from the search space, that is, each hyperparameter has a specific value.
Trial: An individual attempt at applying a new configuration (e.g., a set of hyperparameter values, a specific neural architecture, etc.). Trial code should be able to run with the provided configuration.
Tuner: An AutoML algorithm, which generates a new configuration for the next try. A new trial will run with this configuration.
Assessor: Analyze a trial’s intermediate results (e.g., periodically evaluated accuracy on test dataset) to tell whether this trial can be early stopped or not.
Training Platform: Where trials are executed. Depending on your experiment’s configuration, it could be your local machine, or remote servers, or large-scale training platform (e.g., OpenPAI, Kubernetes).
Basically, an experiment runs as follows: Tuner receives search space and generates configurations. These configurations will be submitted to training platforms, such as the local machine, remote machines, or training clusters. Their performances are reported back to Tuner. Then, new configurations are generated and submitted.
For each experiment, the user only needs to define a search space and update a few lines of code, and then leverage NNI built-in Tuner/Assessor and training platforms to search the best hyperparameters and/or neural architecture. There are basically 3 steps:
Step 1: Define search space
Step 2: Update model codes
Step 3: Define Experiment

For more details about how to run an experiment, please refer to Quickstart.
Core Features¶
NNI provides a key capacity to run multiple instances in parallel to find the best combinations of parameters. This feature can be used in various domains, like finding the best hyperparameters for a deep learning model or finding the best configuration for database and other complex systems with real data.
NNI also provides algorithm toolkits for machine learning and deep learning, especially neural architecture search (NAS) algorithms, model compression algorithms, and feature engineering algorithms.
Hyperparameter Tuning¶
This is a core and basic feature of NNI, we provide many popular automatic tuning algorithms (i.e., tuner) and early stop algorithms (i.e., assessor). You can follow Quickstart to tune your model (or system). Basically, there are the above three steps and then starting an NNI experiment.
General NAS Framework¶
This NAS framework is for users to easily specify candidate neural architectures, for example, one can specify multiple candidate operations (e.g., separable conv, dilated conv) for a single layer, and specify possible skip connections. NNI will find the best candidate automatically. On the other hand, the NAS framework provides a simple interface for another type of user (e.g., NAS algorithm researchers) to implement new NAS algorithms. A detailed description of NAS and its usage can be found here.
NNI has support for many one-shot NAS algorithms such as ENAS and DARTS through NNI trial SDK. To use these algorithms you do not have to start an NNI experiment. Instead, import an algorithm in your trial code and simply run your trial code. If you want to tune the hyperparameters in the algorithms or want to run multiple instances, you can choose a tuner and start an NNI experiment.
Other than one-shot NAS, NAS can also run in a classic mode where each candidate architecture runs as an independent trial job. In this mode, similar to hyperparameter tuning, users have to start an NNI experiment and choose a tuner for NAS.
Model Compression¶
NNI provides an easy-to-use model compression framework to compress deep neural networks, the compressed networks typically have much smaller model size and much faster inference speed without losing performance significantlly. Model compression on NNI includes pruning algorithms and quantization algorithms. NNI provides many pruning and quantization algorithms through NNI trial SDK. Users can directly use them in their trial code and run the trial code without starting an NNI experiment. Users can also use NNI model compression framework to customize their own pruning and quantization algorithms.
A detailed description of model compression and its usage can be found here.
Automatic Feature Engineering¶
Automatic feature engineering is for users to find the best features for their tasks. A detailed description of automatic feature engineering and its usage can be found here. It is supported through NNI trial SDK, which means you do not have to create an NNI experiment. Instead, simply import a built-in auto-feature-engineering algorithm in your trial code and directly run your trial code.
The auto-feature-engineering algorithms usually have a bunch of hyperparameters themselves. If you want to automatically tune those hyperparameters, you can leverage hyperparameter tuning of NNI, that is, choose a tuning algorithm (i.e., tuner) and start an NNI experiment for it.