Pruner¶
Basic Pruner¶
Level Pruner¶
- class nni.compression.pruning.LevelPruner(model: Module, config_list: List[Dict])[source]¶
- class nni.compression.pruning.LevelPruner(model: Module, config_list: List[Dict], evaluator: Evaluator | None = None, existed_wrappers: Dict[str, ModuleWrapper] | None = None)
This is a basic pruner, and in some papers it is called magnitude pruning or fine-grained pruning. It will mask the smallest magnitude weights in each specified layer by a saprsity ratio configured in the config list.
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
L1 Norm Pruner¶
- class nni.compression.pruning.L1NormPruner(model: Module, config_list: List[Dict])[source]¶
- class nni.compression.pruning.L1NormPruner(model: Module, config_list: List[Dict], evaluator: Evaluator | None = None, existed_wrappers: Dict[str, ModuleWrapper] | None = None)
L1 norm pruner computes the l1 norm of the layer weight on the first dimension, then prune the weight blocks on this dimension with smaller l1 norm values. i.e., compute the l1 norm of the filters in convolution layer as metric values, compute the l1 norm of the weight by rows in linear layer as metric values.
For more details, please refer to PRUNING FILTERS FOR EFFICIENT CONVNETS.
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
Examples
Please refer to examples/compression/pruning/norm_pruning.py.
L2 Norm Pruner¶
- class nni.compression.pruning.L2NormPruner(model: Module, config_list: List[Dict])[source]¶
- class nni.compression.pruning.L2NormPruner(model: Module, config_list: List[Dict], evaluator: Evaluator | None = None, existed_wrappers: Dict[str, ModuleWrapper] | None = None)
L2 norm pruner is a variant of L1 norm pruner. The only different between L2 norm pruner and L1 norm pruner is L2 norm pruner prunes the weight with the smallest L2 norm of the weights.
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
Examples
Please refer to examples/compression/pruning/norm_pruning.py.
FPGM Pruner¶
- class nni.compression.pruning.FPGMPruner(model: Module, config_list: List[Dict])[source]¶
- class nni.compression.pruning.FPGMPruner(model: Module, config_list: List[Dict], evaluator: Evaluator | None = None, existed_wrappers: Dict[str, ModuleWrapper] | None = None)
FPGM pruner prunes the blocks of the weight with the smallest geometric median. FPGM chooses the weight blocks with the most replaceable contribution.
For more details, please refer to Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration.
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
Examples
Please refer to examples/compression/pruning/norm_pruning.py.
Slim Pruner¶
- class nni.compression.pruning.SlimPruner(model: Module, config_list: List[Dict], evaluator: Evaluator, training_steps: int, regular_scale: float = 1.0)[source]¶
- class nni.compression.pruning.SlimPruner(model: Module, config_list: List[Dict], evaluator: Evaluator, training_steps: int, regular_scale: float = 1.0, existed_wrappers: Dict[str, ModuleWrapper] | None = None)
Slim pruner adds sparsity regularization on the scaling factors of batch normalization (BN) layers during training to identify unimportant channels. The channels with small scaling factor values will be pruned.
For more details, please refer to Learning Efficient Convolutional Networks through Network Slimming.
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
evaluator (Evaluator) –
NNI will use the evaluator to intervene in the model training process, so as to perform training-aware model compression. All training-aware model compression will use the evaluator as the entry for intervention training in the future. Usually you just need to wrap some classes with
nni.traceor package the training process as a function to initialize the evaluator. Please refer Compression Evaluator for a full tutorial on how to initialize aevaluator.The following are two simple examples, if you use native pytorch, please refer to TorchEvaluator, if you use pytorch_lightning, please refer to LightningEvaluator, if you use huggingface transformer trainer, please refer to TransformersEvaluator:
# LightningEvaluator example import pytorch_lightning lightning_trainer = nni.trace(pytorch_lightning.Trainer)(max_epochs=1, max_steps=50, logger=TensorBoardLogger(...)) lightning_data_module = nni.trace(pytorch_lightning.LightningDataModule)(...) from nni.compression import LightningEvaluator evaluator = LightningEvaluator(lightning_trainer, lightning_data_module) # TorchEvaluator example import torch import torch.nn.functional as F # The user customized `training_step` should follow this paramter signature, # the first is `batch`, the second is `model`, # and the return value of `training_step` should be loss, or tuple with the first element is loss, # or dict with key 'loss'. def training_step(batch, model, *args, **kwargs): input_data, target = batch result = model(input_data) return F.nll_loss(result, target) # The user customized `training_model` should follow this paramter signature, # (model, optimizer, `training_step`, lr_scheduler, max_steps, max_epochs, ...), # and note that `training_step`` should be defined out of `training_model`. def training_model(model, optimizer, training_step, lr_scheduler, max_steps, max_epochs, *args, **kwargs): # max_steps, max_epochs might be None, which means unlimited training time, # so here we need set a default termination condition (by default, total_epochs=10, total_steps=100000). total_epochs = max_epochs if max_epochs else 10 total_steps = max_steps if max_steps else 100000 current_step = 0 # init dataloader train_dataloader = ... for epoch in range(total_epochs): ... for batch in train_dataloader: optimizer.zero_grad() loss = training_step(batch, model) loss.backward() optimizer.step() current_step += 1 if current_step >= total_steps: return lr_scheduler.step() import nni traced_optimizer = nni.trace(torch.optim.SGD)(model.parameters(), lr=0.01) from nni.compression import TorchEvaluator evaluator = TorchEvaluator(training_func=training_model, optimziers=traced_optimizer, training_step=training_step) # TransformersEvaluator example from transformers.trainer import Trainer trainer = nni.trace(Trainer)(model=model, args=training_args) from nni.compression import TransformersEvaluator evaluator = TransformersEvaluator(trainer)
training_steps (int) – An integer to control steps of training the model and scale factors. Masks will be generated after
training_steps.regular_scale (float) –
regular_scalecontrols the scale factors’ penalty.
Examples
Please refer to examples/compression/pruning/slim_pruning.py.
Taylor FO Weight Pruner¶
- class nni.compression.pruning.TaylorPruner(model: Module, config_list: List[Dict], evaluator: Evaluator, training_steps: int)[source]¶
- class nni.compression.pruning.TaylorPruner(model: Module, config_list: List[Dict], evaluator: Evaluator, training_steps: int, existed_wrappers: Dict[str, ModuleWrapper])
Taylor pruner is a pruner which prunes on the first weight dimension, based on estimated importance calculated from the first order taylor expansion on weights to achieve a preset level of network sparsity. The estimated importance is defined as the paper Importance Estimation for Neural Network Pruning.
\(\widehat{\mathcal{I}}_{\mathcal{S}}^{(1)}(\mathbf{W}) \triangleq \sum_{s \in \mathcal{S}} \mathcal{I}_{s}^{(1)}(\mathbf{W})=\sum_{s \in \mathcal{S}}\left(g_{s} w_{s}\right)^{2}\)
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
evaluator (Evaluator) –
NNI will use the evaluator to intervene in the model training process, so as to perform training-aware model compression. All training-aware model compression will use the evaluator as the entry for intervention training in the future. Usually you just need to wrap some classes with
nni.traceor package the training process as a function to initialize the evaluator. Please refer Compression Evaluator for a full tutorial on how to initialize aevaluator.The following are two simple examples, if you use native pytorch, please refer to TorchEvaluator, if you use pytorch_lightning, please refer to LightningEvaluator, if you use huggingface transformer trainer, please refer to TransformersEvaluator:
# LightningEvaluator example import pytorch_lightning lightning_trainer = nni.trace(pytorch_lightning.Trainer)(max_epochs=1, max_steps=50, logger=TensorBoardLogger(...)) lightning_data_module = nni.trace(pytorch_lightning.LightningDataModule)(...) from nni.compression import LightningEvaluator evaluator = LightningEvaluator(lightning_trainer, lightning_data_module) # TorchEvaluator example import torch import torch.nn.functional as F # The user customized `training_step` should follow this paramter signature, # the first is `batch`, the second is `model`, # and the return value of `training_step` should be loss, or tuple with the first element is loss, # or dict with key 'loss'. def training_step(batch, model, *args, **kwargs): input_data, target = batch result = model(input_data) return F.nll_loss(result, target) # The user customized `training_model` should follow this paramter signature, # (model, optimizer, `training_step`, lr_scheduler, max_steps, max_epochs, ...), # and note that `training_step`` should be defined out of `training_model`. def training_model(model, optimizer, training_step, lr_scheduler, max_steps, max_epochs, *args, **kwargs): # max_steps, max_epochs might be None, which means unlimited training time, # so here we need set a default termination condition (by default, total_epochs=10, total_steps=100000). total_epochs = max_epochs if max_epochs else 10 total_steps = max_steps if max_steps else 100000 current_step = 0 # init dataloader train_dataloader = ... for epoch in range(total_epochs): ... for batch in train_dataloader: optimizer.zero_grad() loss = training_step(batch, model) loss.backward() optimizer.step() current_step += 1 if current_step >= total_steps: return lr_scheduler.step() import nni traced_optimizer = nni.trace(torch.optim.SGD)(model.parameters(), lr=0.01) from nni.compression import TorchEvaluator evaluator = TorchEvaluator(training_func=training_model, optimziers=traced_optimizer, training_step=training_step) # TransformersEvaluator example from transformers.trainer import Trainer trainer = nni.trace(Trainer)(model=model, args=training_args) from nni.compression import TransformersEvaluator evaluator = TransformersEvaluator(trainer)
training_steps (int) – The step number used to collect gradients, the masks will be generated after training_steps training.
Examples
Please refer to examples/compression/pruning/taylor_pruning.py.
Scheduled Pruners¶
Linear Pruner¶
- class nni.compression.pruning.LinearPruner(pruner, interval_steps, total_times, evaluator=None)[source]¶
The sparse ratio or sparse threshold in the bound pruner will increase in a linear way from 0. to final:
current_sparse = (1 - initial_ratio) * current_times / total_times * final_sparse
If min/max sparse ratio is also set in target setting, they will also synchronous increase in a linear way.
Note that this pruner can not be initialized by
LinearPruner.from_compressor(...).- Parameters:
pruner (Pruner) – The bound pruner.
interval_steps (int) – A integer number, for each
interval_stepstraining, the sparse goal will be updated.total_times (int) – A integer number, how many times to update the sparse goal in total.
evaluator (Evaluator | None) –
NNI will use the evaluator to intervene in the model training process, so as to perform training-aware model compression. All training-aware model compression will use the evaluator as the entry for intervention training in the future. Usually you just need to wrap some classes with
nni.traceor package the training process as a function to initialize the evaluator. Please refer Compression Evaluator for a full tutorial on how to initialize aevaluator.The following are two simple examples, if you use native pytorch, please refer to TorchEvaluator, if you use pytorch_lightning, please refer to LightningEvaluator, if you use huggingface transformer trainer, please refer to TransformersEvaluator:
# LightningEvaluator example import pytorch_lightning lightning_trainer = nni.trace(pytorch_lightning.Trainer)(max_epochs=1, max_steps=50, logger=TensorBoardLogger(...)) lightning_data_module = nni.trace(pytorch_lightning.LightningDataModule)(...) from nni.compression import LightningEvaluator evaluator = LightningEvaluator(lightning_trainer, lightning_data_module) # TorchEvaluator example import torch import torch.nn.functional as F # The user customized `training_step` should follow this paramter signature, # the first is `batch`, the second is `model`, # and the return value of `training_step` should be loss, or tuple with the first element is loss, # or dict with key 'loss'. def training_step(batch, model, *args, **kwargs): input_data, target = batch result = model(input_data) return F.nll_loss(result, target) # The user customized `training_model` should follow this paramter signature, # (model, optimizer, `training_step`, lr_scheduler, max_steps, max_epochs, ...), # and note that `training_step`` should be defined out of `training_model`. def training_model(model, optimizer, training_step, lr_scheduler, max_steps, max_epochs, *args, **kwargs): # max_steps, max_epochs might be None, which means unlimited training time, # so here we need set a default termination condition (by default, total_epochs=10, total_steps=100000). total_epochs = max_epochs if max_epochs else 10 total_steps = max_steps if max_steps else 100000 current_step = 0 # init dataloader train_dataloader = ... for epoch in range(total_epochs): ... for batch in train_dataloader: optimizer.zero_grad() loss = training_step(batch, model) loss.backward() optimizer.step() current_step += 1 if current_step >= total_steps: return lr_scheduler.step() import nni traced_optimizer = nni.trace(torch.optim.SGD)(model.parameters(), lr=0.01) from nni.compression import TorchEvaluator evaluator = TorchEvaluator(training_func=training_model, optimziers=traced_optimizer, training_step=training_step) # TransformersEvaluator example from transformers.trainer import Trainer trainer = nni.trace(Trainer)(model=model, args=training_args) from nni.compression import TransformersEvaluator evaluator = TransformersEvaluator(trainer)
Examples
Please refer to examples/compression/pruning/scheduled_pruning.py.
AGP Pruner¶
- class nni.compression.pruning.AGPPruner(pruner, interval_steps, total_times, evaluator=None)[source]¶
The sparse ratio or sparse threshold in the bound pruner will increase in a AGP way from 0. to final:
current_sparse = (1 - (1 - self._initial_ratio) * (1 - current_times / self.total_times) ** 3) * final_sparse
If min/max sparse ratio is also set in target setting, they will also synchronous increase in a AGP way.
Note that this pruner can not be initialized by
AGPPruner.from_compressor(...).- Parameters:
pruner (Pruner) – The bound pruner.
interval_steps (int) – A integer number, for each
interval_stepstraining, the sparse goal will be updated.total_times (int) – A integer number, how many times to update the sparse goal in total.
evaluator (Evaluator | None) –
NNI will use the evaluator to intervene in the model training process, so as to perform training-aware model compression. All training-aware model compression will use the evaluator as the entry for intervention training in the future. Usually you just need to wrap some classes with
nni.traceor package the training process as a function to initialize the evaluator. Please refer Compression Evaluator for a full tutorial on how to initialize aevaluator.The following are two simple examples, if you use native pytorch, please refer to TorchEvaluator, if you use pytorch_lightning, please refer to LightningEvaluator, if you use huggingface transformer trainer, please refer to TransformersEvaluator:
# LightningEvaluator example import pytorch_lightning lightning_trainer = nni.trace(pytorch_lightning.Trainer)(max_epochs=1, max_steps=50, logger=TensorBoardLogger(...)) lightning_data_module = nni.trace(pytorch_lightning.LightningDataModule)(...) from nni.compression import LightningEvaluator evaluator = LightningEvaluator(lightning_trainer, lightning_data_module) # TorchEvaluator example import torch import torch.nn.functional as F # The user customized `training_step` should follow this paramter signature, # the first is `batch`, the second is `model`, # and the return value of `training_step` should be loss, or tuple with the first element is loss, # or dict with key 'loss'. def training_step(batch, model, *args, **kwargs): input_data, target = batch result = model(input_data) return F.nll_loss(result, target) # The user customized `training_model` should follow this paramter signature, # (model, optimizer, `training_step`, lr_scheduler, max_steps, max_epochs, ...), # and note that `training_step`` should be defined out of `training_model`. def training_model(model, optimizer, training_step, lr_scheduler, max_steps, max_epochs, *args, **kwargs): # max_steps, max_epochs might be None, which means unlimited training time, # so here we need set a default termination condition (by default, total_epochs=10, total_steps=100000). total_epochs = max_epochs if max_epochs else 10 total_steps = max_steps if max_steps else 100000 current_step = 0 # init dataloader train_dataloader = ... for epoch in range(total_epochs): ... for batch in train_dataloader: optimizer.zero_grad() loss = training_step(batch, model) loss.backward() optimizer.step() current_step += 1 if current_step >= total_steps: return lr_scheduler.step() import nni traced_optimizer = nni.trace(torch.optim.SGD)(model.parameters(), lr=0.01) from nni.compression import TorchEvaluator evaluator = TorchEvaluator(training_func=training_model, optimziers=traced_optimizer, training_step=training_step) # TransformersEvaluator example from transformers.trainer import Trainer trainer = nni.trace(Trainer)(model=model, args=training_args) from nni.compression import TransformersEvaluator evaluator = TransformersEvaluator(trainer)
Examples
Please refer to examples/compression/pruning/scheduled_pruning.py.
Other Pruner¶
Movement Pruner¶
- class nni.compression.pruning.MovementPruner(model: Module, config_list: List[Dict], evaluator: Evaluator, warmup_step: int, cooldown_begin_step: int, regular_scale: float = 1.0)[source]¶
- class nni.compression.pruning.MovementPruner(model: Module, config_list: List[Dict], evaluator: Evaluator, warmup_step: int, cooldown_begin_step: int, regular_scale: float = 1.0, existed_wrappers: Dict[str, ModuleWrapper] | None = None)
Movement pruner is an implementation of movement pruning. This is a “fine-pruning” algorithm, which means the masks may change during each fine-tuning step. Each weight element will be scored by the opposite of the sum of the product of weight and its gradient during each step. This means the weight elements moving towards zero will accumulate negative scores, the weight elements moving away from zero will accumulate positive scores. The weight elements with low scores will be masked during inference.
The following figure from the paper shows the weight pruning by movement pruning.
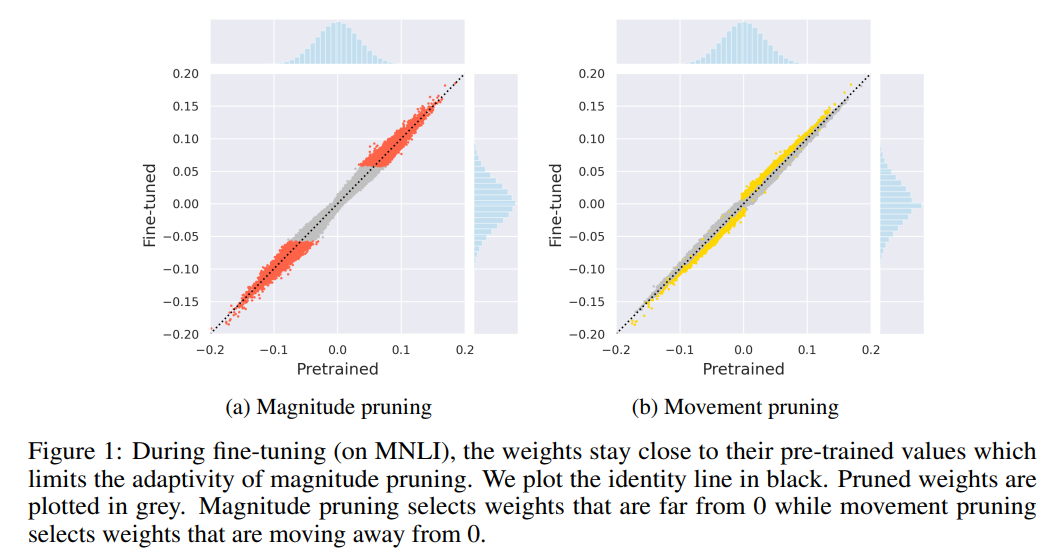
For more details, please refer to Movement Pruning: Adaptive Sparsity by Fine-Tuning.
- Parameters:
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) – A list of dict, each dict configure which module need to be pruned, and how to prune. Please refer Compression Config Specification for more information.
evaluator (Evaluator) –
NNI will use the evaluator to intervene in the model training process, so as to perform training-aware model compression. All training-aware model compression will use the evaluator as the entry for intervention training in the future. Usually you just need to wrap some classes with
nni.traceor package the training process as a function to initialize the evaluator. Please refer Compression Evaluator for a full tutorial on how to initialize aevaluator.The following are two simple examples, if you use native pytorch, please refer to TorchEvaluator, if you use pytorch_lightning, please refer to LightningEvaluator, if you use huggingface transformer trainer, please refer to TransformersEvaluator:
# LightningEvaluator example import pytorch_lightning lightning_trainer = nni.trace(pytorch_lightning.Trainer)(max_epochs=1, max_steps=50, logger=TensorBoardLogger(...)) lightning_data_module = nni.trace(pytorch_lightning.LightningDataModule)(...) from nni.compression import LightningEvaluator evaluator = LightningEvaluator(lightning_trainer, lightning_data_module) # TorchEvaluator example import torch import torch.nn.functional as F # The user customized `training_step` should follow this paramter signature, # the first is `batch`, the second is `model`, # and the return value of `training_step` should be loss, or tuple with the first element is loss, # or dict with key 'loss'. def training_step(batch, model, *args, **kwargs): input_data, target = batch result = model(input_data) return F.nll_loss(result, target) # The user customized `training_model` should follow this paramter signature, # (model, optimizer, `training_step`, lr_scheduler, max_steps, max_epochs, ...), # and note that `training_step`` should be defined out of `training_model`. def training_model(model, optimizer, training_step, lr_scheduler, max_steps, max_epochs, *args, **kwargs): # max_steps, max_epochs might be None, which means unlimited training time, # so here we need set a default termination condition (by default, total_epochs=10, total_steps=100000). total_epochs = max_epochs if max_epochs else 10 total_steps = max_steps if max_steps else 100000 current_step = 0 # init dataloader train_dataloader = ... for epoch in range(total_epochs): ... for batch in train_dataloader: optimizer.zero_grad() loss = training_step(batch, model) loss.backward() optimizer.step() current_step += 1 if current_step >= total_steps: return lr_scheduler.step() import nni traced_optimizer = nni.trace(torch.optim.SGD)(model.parameters(), lr=0.01) from nni.compression import TorchEvaluator evaluator = TorchEvaluator(training_func=training_model, optimziers=traced_optimizer, training_step=training_step) # TransformersEvaluator example from transformers.trainer import Trainer trainer = nni.trace(Trainer)(model=model, args=training_args) from nni.compression import TransformersEvaluator evaluator = TransformersEvaluator(trainer)
warmup_step (int) – The total optimizer.step() number before start pruning for warm up. Make sure
warmup_stepis smaller thancooldown_begin_step.cooldown_begin_step (int) –
The number of steps at which sparsity stops growing, note that the sparsity stop growing doesn’t mean masks not changed. The sparse ratio or sparse threshold after each optimizer.step() is:
final_sparse * (1 - (1 - (current_step - warm_up_step) / (cool_down_beginning_step - warm_up_step)) ** 3)
regular_scale (float) – A scale factor used to control the movement score regular loss. This factor only works on pruning target controlled by
sparse_threshold, the pruning target controlled bysparse_ratiowill not be regularized.
Examples
Please refer to examples/tutorials/new_pruning_bert_glue.py.
