One-shot Strategy (legacy)¶
Warning
This page will be removed in future releases.
DARTS¶
The paper DARTS: Differentiable Architecture Search addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. Their method is based on the continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent.
Authors’ code optimizes the network weights and architecture weights alternatively in mini-batches. They further explore the possibility that uses second order optimization (unroll) instead of first order, to improve the performance.
Implementation on NNI is based on the official implementation and a popular 3rd-party repo. DARTS on NNI is designed to be general for arbitrary search space. A CNN search space tailored for CIFAR10, same as the original paper, is implemented as a use case of DARTS.
- class nni.retiarii.oneshot.pytorch.DartsTrainer(model, loss, metrics, optimizer, num_epochs, dataset, grad_clip=5.0, learning_rate=0.0025, batch_size=64, workers=4, device=None, log_frequency=None, arc_learning_rate=0.0003, unrolled=False)[source]¶
DARTS trainer.
- Parameters
model (nn.Module) – PyTorch model to be trained.
loss (callable) – Receives logits and ground truth label, return a loss tensor.
metrics (callable) – Receives logits and ground truth label, return a dict of metrics.
optimizer (Optimizer) – The optimizer used for optimizing the model.
num_epochs (int) – Number of epochs planned for training.
dataset (Dataset) – Dataset for training. Will be split for training weights and architecture weights.
grad_clip (float) – Gradient clipping. Set to 0 to disable. Default: 5.
learning_rate (float) – Learning rate to optimize the model.
batch_size (int) – Batch size.
workers (int) – Workers for data loading.
device (torch.device) –
torch.device("cpu")ortorch.device("cuda").log_frequency (int) – Step count per logging.
arc_learning_rate (float) – Learning rate of architecture parameters.
unrolled (float) –
Trueif using second order optimization, else first order optimization.
Reproduction Results¶
The above-mentioned example is meant to reproduce the results in the paper, we do experiments with first and second order optimization. Due to the time limit, we retrain only the best architecture derived from the search phase and we repeat the experiment only once. Our results is currently on par with the results reported in paper. We will add more results later when ready.
In paper |
Reproduction |
|
|---|---|---|
First order (CIFAR10) |
3.00 +/- 0.14 |
2.78 |
Second order (CIFAR10) |
2.76 +/- 0.09 |
2.80 |
Examples¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/oneshot/darts
python3 search.py
# train the best architecture
python3 retrain.py --arc-checkpoint ./checkpoints/epoch_49.json
Limitations¶
DARTS doesn’t support DataParallel and needs to be customized in order to support DistributedDataParallel.
ENAS¶
The paper Efficient Neural Architecture Search via Parameter Sharing uses parameter sharing between child models to accelerate the NAS process. In ENAS, a controller learns to discover neural network architectures by searching for an optimal subgraph within a large computational graph. The controller is trained with policy gradient to select a subgraph that maximizes the expected reward on the validation set. Meanwhile the model corresponding to the selected subgraph is trained to minimize a canonical cross entropy loss.
Implementation on NNI is based on the official implementation in Tensorflow, including a general-purpose Reinforcement-learning controller and a trainer that trains target network and this controller alternatively. Following paper, we have also implemented macro and micro search space on CIFAR10 to demonstrate how to use these trainers. Since code to train from scratch on NNI is not ready yet, reproduction results are currently unavailable.
- class nni.retiarii.oneshot.pytorch.EnasTrainer(model, loss, metrics, reward_function, optimizer, num_epochs, dataset, batch_size=64, workers=4, device=None, log_frequency=None, grad_clip=5.0, entropy_weight=0.0001, skip_weight=0.8, baseline_decay=0.999, ctrl_lr=0.00035, ctrl_steps_aggregate=20, ctrl_kwargs=None)[source]¶
ENAS trainer.
- Parameters
model (nn.Module) – PyTorch model to be trained.
loss (callable) – Receives logits and ground truth label, return a loss tensor.
metrics (callable) – Receives logits and ground truth label, return a dict of metrics.
reward_function (callable) – Receives logits and ground truth label, return a tensor, which will be feeded to RL controller as reward.
optimizer (Optimizer) – The optimizer used for optimizing the model.
num_epochs (int) – Number of epochs planned for training.
dataset (Dataset) – Dataset for training. Will be split for training weights and architecture weights.
batch_size (int) – Batch size.
workers (int) – Workers for data loading.
device (torch.device) –
torch.device("cpu")ortorch.device("cuda").log_frequency (int) – Step count per logging.
grad_clip (float) – Gradient clipping. Set to 0 to disable. Default: 5.
entropy_weight (float) – Weight of sample entropy loss.
skip_weight (float) – Weight of skip penalty loss.
baseline_decay (float) – Decay factor of baseline. New baseline will be equal to
baseline_decay * baseline_old + reward * (1 - baseline_decay).ctrl_lr (float) – Learning rate for RL controller.
ctrl_steps_aggregate (int) – Number of steps that will be aggregated into one mini-batch for RL controller.
ctrl_steps (int) – Number of mini-batches for each epoch of RL controller learning.
ctrl_kwargs (dict) – Optional kwargs that will be passed to
ReinforceController.
Examples¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/oneshot/enas
# search in macro search space
python3 search.py --search-for macro
# search in micro search space
python3 search.py --search-for micro
# view more options for search
python3 search.py -h
FBNet¶
Note
This one-shot NAS is still implemented under NNI NAS 1.0, and will be migrated to Retiarii framework in near future.
For the mobile application of facial landmark, based on the basic architecture of PFLD model, we have applied the FBNet (Block-wise DNAS) to design an concise model with the trade-off between latency and accuracy. References are listed as below:
FBNet is a block-wise differentiable NAS method (Block-wise DNAS), where the best candidate building blocks can be chosen by using Gumbel Softmax random sampling and differentiable training. At each layer (or stage) to be searched, the diverse candidate blocks are side by side planned (just like the effectiveness of structural re-parameterization), leading to sufficient pre-training of the supernet. The pre-trained supernet is further sampled for finetuning of the subnet, to achieve better performance.
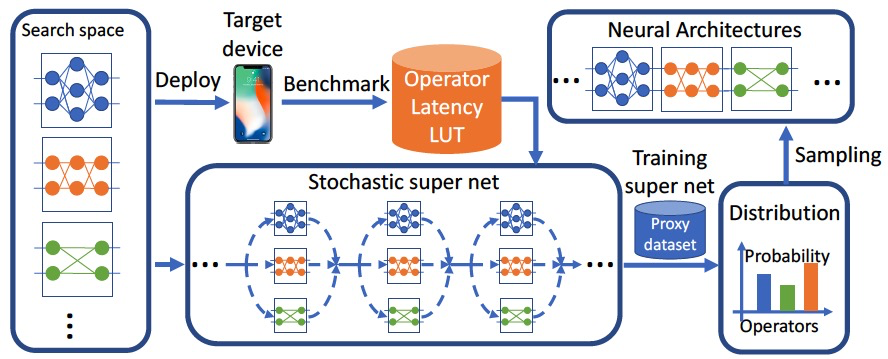
PFLD is a lightweight facial landmark model for realtime application. The architecture of PLFD is firstly simplified for acceleration, by using the stem block of PeleeNet, average pooling with depthwise convolution and eSE module.
To achieve better trade-off between latency and accuracy, the FBNet is further applied on the simplified PFLD for searching the best block at each specific layer. The search space is based on the FBNet space, and optimized for mobile deployment by using the average pooling with depthwise convolution and eSE module etc.
Experiments¶
To verify the effectiveness of FBNet applied on PFLD, we choose the open source dataset with 106 landmark points as the benchmark:
The baseline model is denoted as MobileNet-V3 PFLD (Reference baseline), and the searched model is denoted as Subnet. The experimental results are listed as below, where the latency is tested on Qualcomm 625 CPU (ARMv8):
Model |
Size |
Latency |
Validation NME |
|---|---|---|---|
MobileNet-V3 PFLD |
1.01MB |
10ms |
6.22% |
Subnet |
693KB |
1.60ms |
5.58% |
Example¶
Please run the following scripts at the example directory.
The Python dependencies used here are listed as below:
numpy==1.18.5
opencv-python==4.5.1.48
torch==1.6.0
torchvision==0.7.0
onnx==1.8.1
onnx-simplifier==0.3.5
onnxruntime==1.7.0
To run the tutorial, follow the steps below:
Data Preparation: Firstly, you should download the dataset 106points dataset to the path
./data/106points. The dataset includes the train-set and test-set:./data/106points/train_data/imgs ./data/106points/train_data/list.txt ./data/106points/test_data/imgs ./data/106points/test_data/list.txt
Search: Based on the architecture of simplified PFLD, the setting of multi-stage search space and hyper-parameters for searching should be firstly configured to construct the supernet. For example,
from lib.builder import search_space from lib.ops import PRIMITIVES from lib.supernet import PFLDInference, AuxiliaryNet from nni.algorithms.nas.pytorch.fbnet import LookUpTable, NASConfig # configuration of hyper-parameters # search_space defines the multi-stage search space nas_config = NASConfig( model_dir="./ckpt_save", nas_lr=0.01, mode="mul", alpha=0.25, beta=0.6, search_space=search_space, ) # lookup table to manage the information lookup_table = LookUpTable(config=nas_config, primitives=PRIMITIVES) # created supernet pfld_backbone = PFLDInference(lookup_table)
After creation of the supernet with the specification of search space and hyper-parameters, we can run below command to start searching and training of the supernet:
python train.py --dev_id ^0,1^ --snapshot ^./ckpt_save^ --data_root ^./data/106points^
The validation accuracy will be shown during training, and the model with best accuracy will be saved as
./ckpt_save/supernet/checkpoint_best.pth.Finetune: After pre-training of the supernet, we can run below command to sample the subnet and conduct the finetuning:
python retrain.py --dev_id ^0,1^ --snapshot ^./ckpt_save^ --data_root ^./data/106points^ \ --supernet ^./ckpt_save/supernet/checkpoint_best.pth^The validation accuracy will be shown during training, and the model with best accuracy will be saved as
./ckpt_save/subnet/checkpoint_best.pth.Export: After the finetuning of subnet, we can run below command to export the ONNX model:
python export.py --supernet ^./ckpt_save/supernet/checkpoint_best.pth^ \ --resume ^./ckpt_save/subnet/checkpoint_best.pth^ONNX model is saved as
./output/subnet.onnx, which can be further converted to the mobile inference engine by using MNN . The checkpoints of pre-trained supernet and subnet are offered as below:
SPOS¶
Proposed in Single Path One-Shot Neural Architecture Search with Uniform Sampling is a one-shot NAS method that addresses the difficulties in training One-Shot NAS models by constructing a simplified supernet trained with an uniform path sampling method, so that all underlying architectures (and their weights) get trained fully and equally. An evolutionary algorithm is then applied to efficiently search for the best-performing architectures without any fine tuning.
Implementation on NNI is based on official repo. We implement a trainer that trains the supernet and a evolution tuner that leverages the power of NNI framework that speeds up the evolutionary search phase.
- class nni.retiarii.oneshot.pytorch.SinglePathTrainer(model, loss, metrics, optimizer, num_epochs, dataset_train, dataset_valid, batch_size=64, workers=4, device=None, log_frequency=None)[source]¶
Single-path trainer. Samples a path every time and backpropagates on that path.
- Parameters
model (nn.Module) – Model with mutables.
loss (callable) – Called with logits and targets. Returns a loss tensor.
metrics (callable) – Returns a dict that maps metrics keys to metrics data.
optimizer (Optimizer) – Optimizer that optimizes the model.
num_epochs (int) – Number of epochs of training.
dataset_train (Dataset) – Dataset of training.
dataset_valid (Dataset) – Dataset of validation.
batch_size (int) – Batch size.
workers (int) – Number of threads for data preprocessing. Not used for this trainer. Maybe removed in future.
device (torch.device) – Device object. Either
torch.device("cuda")ortorch.device("cpu"). WhenNone, trainer will automatic detects GPU and selects GPU first.log_frequency (int) – Number of mini-batches to log metrics.
Examples¶
Here is a use case, which is the search space in paper. However, we applied latency limit instead of flops limit to perform the architecture search phase.
Requirements: Prepare ImageNet in the standard format (follow the script here). Linking it to data/imagenet will be more convenient. Download the checkpoint file from here (maintained by Megvii) if you don’t want to retrain the supernet. Put checkpoint-150000.pth.tar under data directory. After preparation, it’s expected to have the following code structure:
spos
├── architecture_final.json
├── blocks.py
├── data
│ ├── imagenet
│ │ ├── train
│ │ └── val
│ └── checkpoint-150000.pth.tar
├── network.py
├── readme.md
├── supernet.py
├── evaluation.py
├── search.py
└── utils.py
Then follow the 3 steps:
Train Supernet:
python supernet.py
This will export the checkpoint to
checkpointsdirectory, for the next step.Note
The data loading used in the official repo is slightly different from usual, as they use BGR tensor and keep the values between 0 and 255 intentionally to align with their own DL framework. The option
--spos-preprocessingwill simulate the behavior used originally and enable you to use the checkpoints pretrained.Evolution Search: Single Path One-Shot leverages evolution algorithm to search for the best architecture. In the paper, the search module, which is responsible for testing the sampled architecture, recalculates all the batch norm for a subset of training images, and evaluates the architecture on the full validation set. In this example, it will inherit the
state_dictof supernet from ./data/checkpoint-150000.pth.tar, and search the best architecture with the regularized evolution strategy. Search in the supernet with the following commandpython search.py
NNI support a latency filter to filter unsatisfied model from search phase. Latency is predicted by Microsoft nn-Meter (https://github.com/microsoft/nn-Meter). To apply the latency filter, users could run search.py with additional arguments
--latency-filter. Here is an example:python search.py --latency-filter cortexA76cpu_tflite21
Note that the latency filter is only supported for base execution engine.
The final architecture exported from every epoch of evolution can be found in
trialsunder the working directory of your tuner, which, by default, is$HOME/nni-experiments/your_experiment_id/trials.Train for Evaluation:
python evaluation.py
By default, it will use
architecture_final.json. This architecture is provided by the official repo (converted into NNI format). You can use any architecture (e.g., the architecture found in step 2) with--fixed-arcoption.
Known Limitations¶
Block search only. Channel search is not supported yet.
Current Reproduction Results¶
Reproduction is still undergoing. Due to the gap between official release and original paper, we compare our current results with official repo (our run) and paper.
Evolution phase is almost aligned with official repo. Our evolution algorithm shows a converging trend and reaches ~65% accuracy at the end of search. Nevertheless, this result is not on par with paper. For details, please refer to this issue.
Retrain phase is not aligned. Our retraining code, which uses the architecture released by the authors, reaches 72.14% accuracy, still having a gap towards 73.61% by official release and 74.3% reported in original paper.
ProxylessNAS¶
The paper ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware removes proxy, it directly learns the architectures for large-scale target tasks and target hardware platforms. They address high memory consumption issue of differentiable NAS and reduce the computational cost to the same level of regular training while still allowing a large candidate set. Please refer to the paper for the details.
- class nni.retiarii.oneshot.pytorch.ProxylessTrainer(model, loss, metrics, optimizer, num_epochs, dataset, warmup_epochs=0, batch_size=64, workers=4, device=None, log_frequency=None, arc_learning_rate=0.001, grad_reg_loss_type=None, grad_reg_loss_params=None, applied_hardware=None, dummy_input=(1, 3, 224, 224), ref_latency=65.0)[source]¶
Proxyless trainer.
- Parameters
model (nn.Module) – PyTorch model to be trained.
loss (callable) – Receives logits and ground truth label, return a loss tensor.
metrics (callable) – Receives logits and ground truth label, return a dict of metrics.
optimizer (Optimizer) – The optimizer used for optimizing the model.
num_epochs (int) – Number of epochs planned for training.
dataset (Dataset) – Dataset for training. Will be split for training weights and architecture weights.
warmup_epochs (int) – Number of epochs to warmup model parameters.
batch_size (int) – Batch size.
workers (int) – Workers for data loading.
device (torch.device) –
torch.device("cpu")ortorch.device("cuda").log_frequency (int) – Step count per logging.
arc_learning_rate (float) – Learning rate of architecture parameters.
grad_reg_loss_type (string) – Regularization type to add hardware related loss, allowed types include -
"mul#log":regularized_loss = (torch.log(expected_latency) / math.log(self.ref_latency)) ** beta-"add#linear":regularized_loss = reg_lambda * (expected_latency - self.ref_latency) / self.ref_latency- None: do not apply loss regularization.grad_reg_loss_params (dict) – Regularization params, allowed params include -
"alpha"and"beta"is required whengrad_reg_loss_type == "mul#log"-"lambda"is required whengrad_reg_loss_type == "add#linear"applied_hardware (string) – Applied hardware for to constraint the model’s latency. Latency is predicted by Microsoft nn-Meter (https://github.com/microsoft/nn-Meter).
dummy_input (tuple) – The dummy input shape when applied to the target hardware.
ref_latency (float) – Reference latency value in the applied hardware (ms).
To use ProxylessNAS training/searching approach, users need to specify search space in their model using NNI NAS interface, e.g., LayerChoice, InputChoice. After defining and instantiating the model, the following work can be leaved to ProxylessNasTrainer by instantiating the trainer and passing the model to it.
trainer = ProxylessTrainer(model,
loss=LabelSmoothingLoss(),
dataset=None,
optimizer=optimizer,
metrics=lambda output, target: accuracy(output, target, topk=(1, 5,)),
num_epochs=120,
log_frequency=10,
grad_reg_loss_type=args.grad_reg_loss_type,
grad_reg_loss_params=grad_reg_loss_params,
applied_hardware=args.applied_hardware, dummy_input=(1, 3, 224, 224),
ref_latency=args.reference_latency)
trainer.train()
trainer.export(args.arch_path)
The complete example code can be found here.
Implementation¶
The implementation on NNI is based on the offical implementation. The official implementation supports two training approaches: gradient descent and RL based. In our current implementation on NNI, gradient descent training approach is supported. The complete support of ProxylessNAS is ongoing.
The official implementation supports different targeted hardware, including ‘mobile’, ‘cpu’, ‘gpu8’, ‘flops’. In NNI repo, the hardware latency prediction is supported by Microsoft nn-Meter. nn-Meter is an accurate inference latency predictor for DNN models on diverse edge devices. nn-Meter support four hardwares up to now, including cortexA76cpu_tflite21, adreno640gpu_tflite21, adreno630gpu_tflite21, and myriadvpu_openvino2019r2. Users can find more information about nn-Meter on its website. More hardware will be supported in the future. Users could find more details about applying nn-Meter here.
Below we will describe implementation details. Like other one-shot NAS algorithms on NNI, ProxylessNAS is composed of two parts: search space and training approach. For users to flexibly define their own search space and use built-in ProxylessNAS training approach, please refer to example code for a reference.
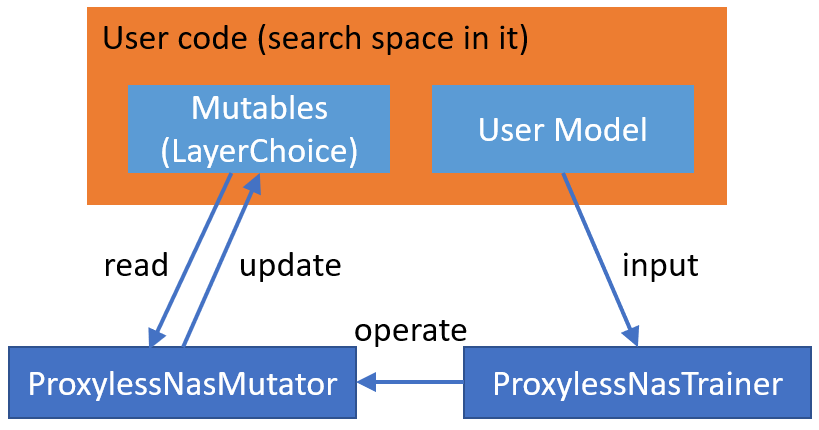
ProxylessNAS training approach is composed of ProxylessLayerChoice and ProxylessNasTrainer. ProxylessLayerChoice instantiates MixedOp for each mutable (i.e., LayerChoice), and manage architecture weights in MixedOp. For DataParallel, architecture weights should be included in user model. Specifically, in ProxylessNAS implementation, we add MixedOp to the corresponding mutable (i.e., LayerChoice) as a member variable. The ProxylessLayerChoice class also exposes two member functions, i.e., resample, finalize_grad, for the trainer to control the training of architecture weights.
Reproduction Results¶
To reproduce the result, we first run the search, we found that though it runs many epochs the chosen architecture converges at the first several epochs. This is probably induced by hyper-parameters or the implementation, we are working on it.
Customization¶
- class nni.retiarii.oneshot.BaseOneShotTrainer[source]¶
Build many (possibly all) architectures into a full graph, search (with train) and export the best.
One-shot trainer has a
fitfunction with no return value. Trainers should fit and search for the best architecture. Currently, all the inputs of trainer needs to be manually set before fit (including the search space, data loader to use training epochs, and etc.).It has an extra
exportfunction that exports an object representing the final searched architecture.
- nni.retiarii.oneshot.pytorch.utils.replace_layer_choice(root_module, init_fn, modules=None)[source]¶
Replace layer choice modules with modules that are initiated with init_fn.
- Parameters
root_module (nn.Module) – Root module to traverse.
init_fn (Callable) – Initializing function.
modules (dict, optional) – Update the replaced modules into the dict and check duplicate if provided.
- Returns
A list from layer choice keys (names) and replaced modules.
- Return type
list[tuple[str, nn.Module]]
- nni.retiarii.oneshot.pytorch.utils.replace_input_choice(root_module, init_fn, modules=None)[source]¶
Replace input choice modules with modules that are initiated with init_fn.
- Parameters
root_module (nn.Module) – Root module to traverse.
init_fn (Callable) – Initializing function.
modules (dict, optional) – Update the replaced modules into the dict and check duplicate if provided.
- Returns
A list from layer choice keys (names) and replaced modules.
- Return type
list[tuple[str, nn.Module]]