Pruner¶
Basic Pruner¶
Level Pruner¶
- class nni.compression.pytorch.pruning.LevelPruner(model, config_list, mode='normal', balance_gran=None)[source]¶
This is a basic pruner, and in some papers called it magnitude pruning or fine-grained pruning. It will mask the smallest magnitude weights in each specified layer by a saprsity ratio configured in the config list.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Operation types to be pruned.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
mode (str) – ‘normal’ or ‘balance’. If setting ‘normal’ mode, target tensor will be pruned in the way of finegrained pruning. If setting ‘balance’ mode, a specal sparse pattern will chosen by pruner. Take linear operation an example, weight tensor will be split into sub block whose shape is aligned to balance_gran. Then finegrained pruning will be applied internal of sub block. This sparsity pattern have more chance to achieve better trade-off between model performance and hardware acceleration. Please refer to releated paper for further information Balanced Sparsity for Efficient DNN Inference on GPU.
balance_gran (list) –
Balance_gran is for special sparse pattern balanced sparsity, Default value is None which means pruning without awaring balance, namely normal finegrained pruning. If passing list of int, LevelPruner will prune the model in the granularity of multi-dimension block. Attention that the length of balance_gran should be smaller than tensor dimension. For instance, in Linear operation, length of balance_gran should be equal or smaller than two since dimension of pruning weight is two. If setting balbance_gran = [5, 5], sparsity = 0.6, pruner will divide pruning parameters into multiple block with tile size (5,5) and each bank has 5 * 5 values and 10 values would be kept after pruning. Finegrained pruning is applied in the granularity of block so that each block will kept same number of non-zero values after pruning. Such pruning method “balance” the non-zero value in tensor which create chance for better hardware acceleration.
- Note: If length of given balance_gran smaller than length of pruning tensor shape, it will be made up
in right align(such as example 1).
- example 1:
operation: Linear pruning tensor: weight pruning tensor shape: [32, 32] sparsity: 50% balance_gran: [4]
- pruning result: Weight tensor whose shape is [32, 32] will be split into 256 [1, 4] sub blocks.
Each sub block will be pruned 2 values.
- example 2:
operation: Linear pruning tensor: weight pruning tensor shape: [64, 64] sparsity: 25% balance_gran: [32, 32]
- pruning result: Weight tensor whose shape is [64, 64] will be split into 4 [32, 32] sub blocks.
Each sub block will be pruned 256 values.
Examples
>>> model = ... >>> from nni.compression.pytorch.pruning import LevelPruner >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }] >>> pruner = LevelPruner(model, config_list) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/level_pruning_torch.py
L1 Norm Pruner¶
- class nni.compression.pytorch.pruning.L1NormPruner(model, config_list, mode='normal', dummy_input=None)[source]¶
L1 norm pruner computes the l1 norm of the layer weight on the first dimension, then prune the weight blocks on this dimension with smaller l1 norm values. i.e., compute the l1 norm of the filters in convolution layer as metric values, compute the l1 norm of the weight by rows in linear layer as metric values.
For more details, please refer to PRUNING FILTERS FOR EFFICIENT CONVNETS.
In addition, L1 norm pruner also supports dependency-aware mode.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Conv2d and Linear are supported in L1NormPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
mode (str) – ‘normal’ or ‘dependency_aware’. If prune the model in a dependency-aware way, this pruner will prune the model according to the l1-norm of weights and the channel-dependency or group-dependency of the model. In this way, the pruner will force the conv layers that have dependencies to prune the same channels, so the speedup module can better harvest the speed benefit from the pruned model. Note that, if set ‘dependency_aware’ , the dummy_input cannot be None, because the pruner needs a dummy input to trace the dependency between the conv layers.
dummy_input (Optional[torch.Tensor]) – The dummy input to analyze the topology constraints. Note that, the dummy_input should on the same device with the model.
L2 Norm Pruner¶
- class nni.compression.pytorch.pruning.L2NormPruner(model, config_list, mode='normal', dummy_input=None)[source]¶
L2 norm pruner is a variant of L1 norm pruner. The only different between L2 norm pruner and L1 norm pruner is L2 norm pruner prunes the weight with the smallest L2 norm of the weights.
L2 norm pruner also supports dependency-aware mode.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Conv2d and Linear are supported in L2NormPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
mode (str) – ‘normal’ or ‘dependency_aware’. If prune the model in a dependency-aware way, this pruner will prune the model according to the l2-norm of weights and the channel-dependency or group-dependency of the model. In this way, the pruner will force the conv layers that have dependencies to prune the same channels, so the speedup module can better harvest the speed benefit from the pruned model. Note that, if set ‘dependency_aware’ , the dummy_input cannot be None, because the pruner needs a dummy input to trace the dependency between the conv layers.
dummy_input (Optional[torch.Tensor]) – The dummy input to analyze the topology constraints. Note that, the dummy_input should on the same device with the model.
Examples
>>> model = ... >>> from nni.compression.pytorch.pruning import L2NormPruner >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = L2NormPruner(model, config_list) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/norm_pruning_torch.py
FPGM Pruner¶
- class nni.compression.pytorch.pruning.FPGMPruner(model, config_list, mode='normal', dummy_input=None)[source]¶
FPGM pruner prunes the blocks of the weight on the first dimension with the smallest geometric median. FPGM chooses the weight blocks with the most replaceable contribution.
For more details, please refer to Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration.
FPGM pruner also supports dependency-aware mode.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Conv2d and Linear are supported in FPGMPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
mode (str) – ‘normal’ or ‘dependency_aware’. If prune the model in a dependency-aware way, this pruner will prune the model according to the FPGM of weights and the channel-dependency or group-dependency of the model. In this way, the pruner will force the conv layers that have dependencies to prune the same channels, so the speedup module can better harvest the speed benefit from the pruned model. Note that, if set ‘dependency_aware’ , the dummy_input cannot be None, because the pruner needs a dummy input to trace the dependency between the conv layers.
dummy_input (Optional[torch.Tensor]) – The dummy input to analyze the topology constraints. Note that, the dummy_input should on the same device with the model.
Examples
>>> model = ... >>> from nni.compression.pytorch.pruning import FPGMPruner >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = FPGMPruner(model, config_list) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/fpgm_pruning_torch.py
Slim Pruner¶
- class nni.compression.pytorch.pruning.SlimPruner(model, config_list, trainer, traced_optimizer, criterion, training_epochs, scale=0.0001, mode='global')[source]¶
Slim pruner adds sparsity regularization on the scaling factors of batch normalization (BN) layers during training to identify unimportant channels. The channels with small scaling factor values will be pruned.
For more details, please refer to Learning Efficient Convolutional Networks through Network Slimming.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
total_sparsity : This is to specify the total sparsity for all layers in this config, each layer may have different sparsity.
max_sparsity_per_layer : Always used with total_sparsity. Limit the max sparsity of each layer.
op_types : Only BatchNorm2d is supported in SlimPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
trainer (Callable[[Module, Optimizer, Callable], None]) –
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
Example:
def trainer(model: Module, optimizer: Optimizer, criterion: Callable[[Tensor, Tensor], Tensor]): training = model.training model.train(mode=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # If you don't want to update the model, you can skip `optimizer.step()`, and set train mode False. optimizer.step() model.train(mode=training)
traced_optimizer (nni.common.serializer.Traceable(torch.optim.Optimizer)) – The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters()).criterion (Callable[[Tensor, Tensor], Tensor]) – The criterion function used in trainer. Take model output and target value as input, and return the loss.
training_epochs (int) – The epoch number for training model to sparsify the BN weight.
scale (float) – Penalty parameter for sparsification, which could reduce overfitting.
mode (str) – ‘normal’ or ‘global’. If prune the model in a global way, all layer weights with same config will be considered uniformly. That means a single layer may not reach or exceed the sparsity setting in config, but the total pruned weights meet the sparsity setting.
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import SlimPruner >>> model = ... >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['BatchNorm2d'] }] >>> pruner = SlimPruner(model, config_list, trainer, traced_optimizer, criterion, training_epochs=1) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/slim_pruning_torch.py
Activation APoZ Rank Pruner¶
- class nni.compression.pytorch.pruning.ActivationAPoZRankPruner(model, config_list, trainer, traced_optimizer, criterion, training_batches, activation='relu', mode='normal', dummy_input=None)[source]¶
Activation APoZ rank pruner is a pruner which prunes on the first weight dimension, with the smallest importance criterion
APoZcalculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterionAPoZis explained in the paper Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures.The APoZ is defined as: \(APoZ_{c}^{(i)} = APoZ\left(O_{c}^{(i)}\right)=\frac{\sum_{k}^{N} \sum_{j}^{M} f\left(O_{c, j}^{(i)}(k)=0\right)}{N \times M}\)
Activation APoZ rank pruner also supports dependency-aware mode.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Conv2d and Linear are supported in ActivationAPoZRankPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
trainer (Callable[[Module, Optimizer, Callable], None]) –
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
Example:
def trainer(model: Module, optimizer: Optimizer, criterion: Callable[[Tensor, Tensor], Tensor]): training = model.training model.train(mode=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # If you don't want to update the model, you can skip `optimizer.step()`, and set train mode False. optimizer.step() model.train(mode=training)
traced_optimizer (nni.common.serializer.Traceable(torch.optim.Optimizer)) – The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters())..criterion (Callable[[Tensor, Tensor], Tensor]) – The criterion function used in trainer. Take model output and target value as input, and return the loss.
training_batches (int) – The batch number used to collect activations.
mode (str) – ‘normal’ or ‘dependency_aware’. If prune the model in a dependency-aware way, this pruner will prune the model according to the activation-based metrics and the channel-dependency or group-dependency of the model. In this way, the pruner will force the conv layers that have dependencies to prune the same channels, so the speedup module can better harvest the speed benefit from the pruned model. Note that, if set ‘dependency_aware’ , the dummy_input cannot be None, because the pruner needs a dummy input to trace the dependency between the conv layers.
dummy_input (Optional[torch.Tensor]) – The dummy input to analyze the topology constraints. Note that, the dummy_input should on the same device with the model.
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import ActivationAPoZRankPruner >>> model = ... >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = ActivationAPoZRankPruner(model, config_list, trainer, traced_optimizer, criterion, training_batches=20) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/activation_pruning_torch.py
Activation Mean Rank Pruner¶
- class nni.compression.pytorch.pruning.ActivationMeanRankPruner(model, config_list, trainer, traced_optimizer, criterion, training_batches, activation='relu', mode='normal', dummy_input=None)[source]¶
Activation mean rank pruner is a pruner which prunes on the first weight dimension, with the smallest importance criterion
mean activationcalculated from the output activations of convolution layers to achieve a preset level of network sparsity.The pruning criterion
mean activationis explained in section 2.2 of the paper Pruning Convolutional Neural Networks for Resource Efficient Inference.Activation mean rank pruner also supports dependency-aware mode.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Conv2d and Linear are supported in ActivationPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
trainer (Callable[[Module, Optimizer, Callable], None]) –
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
Example:
def trainer(model: Module, optimizer: Optimizer, criterion: Callable[[Tensor, Tensor], Tensor]): training = model.training model.train(mode=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # If you don't want to update the model, you can skip `optimizer.step()`, and set train mode False. optimizer.step() model.train(mode=training)
traced_optimizer (nni.common.serializer.Traceable(torch.optim.Optimizer)) – The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters())..criterion (Callable[[Tensor, Tensor], Tensor]) – The criterion function used in trainer. Take model output and target value as input, and return the loss.
training_batches (int) – The batch number used to collect activations.
mode (str) – ‘normal’ or ‘dependency_aware’. If prune the model in a dependency-aware way, this pruner will prune the model according to the activation-based metrics and the channel-dependency or group-dependency of the model. In this way, the pruner will force the conv layers that have dependencies to prune the same channels, so the speedup module can better harvest the speed benefit from the pruned model. Note that, if set ‘dependency_aware’ , the dummy_input cannot be None, because the pruner needs a dummy input to trace the dependency between the conv layers.
dummy_input (Optional[torch.Tensor]) – The dummy input to analyze the topology constraints. Note that, the dummy_input should on the same device with the model.
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import ActivationMeanRankPruner >>> model = ... >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = ActivationMeanRankPruner(model, config_list, trainer, traced_optimizer, criterion, training_batches=20) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/activation_pruning_torch.py
Taylor FO Weight Pruner¶
- class nni.compression.pytorch.pruning.TaylorFOWeightPruner(model, config_list, trainer, traced_optimizer, criterion, training_batches, mode='normal', dummy_input=None)[source]¶
Taylor FO weight pruner is a pruner which prunes on the first weight dimension, based on estimated importance calculated from the first order taylor expansion on weights to achieve a preset level of network sparsity. The estimated importance is defined as the paper Importance Estimation for Neural Network Pruning.
\(\widehat{\mathcal{I}}_{\mathcal{S}}^{(1)}(\mathbf{W}) \triangleq \sum_{s \in \mathcal{S}} \mathcal{I}_{s}^{(1)}(\mathbf{W})=\sum_{s \in \mathcal{S}}\left(g_{s} w_{s}\right)^{2}\)
Taylor FO weight pruner also supports dependency-aware mode.
What’s more, we provide a global-sort mode for this pruner which is aligned with paper implementation.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
total_sparsity : This is to specify the total sparsity for all layers in this config, each layer may have different sparsity.
max_sparsity_per_layer : Always used with total_sparsity. Limit the max sparsity of each layer.
op_types : Conv2d and Linear are supported in TaylorFOWeightPruner.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
trainer (Callable[[Module, Optimizer, Callable]) –
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
Example:
def trainer(model: Module, optimizer: Optimizer, criterion: Callable[[Tensor, Tensor], Tensor]): training = model.training model.train(mode=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # If you don't want to update the model, you can skip `optimizer.step()`, and set train mode False. optimizer.step() model.train(mode=training)
traced_optimizer (nni.common.serializer.Traceable(torch.optim.Optimizer)) – The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters()).criterion (Callable[[Tensor, Tensor], Tensor]) – The criterion function used in trainer. Take model output and target value as input, and return the loss.
training_batches (int) – The batch number used to collect activations.
mode (str) –
‘normal’, ‘dependency_aware’ or ‘global’.
If prune the model in a dependency-aware way, this pruner will prune the model according to the taylorFO and the channel-dependency or group-dependency of the model. In this way, the pruner will force the conv layers that have dependencies to prune the same channels, so the speedup module can better harvest the speed benefit from the pruned model. Note that, if set ‘dependency_aware’ , the dummy_input cannot be None, because the pruner needs a dummy input to trace the dependency between the conv layers.
If prune the model in a global way, all layer weights with same config will be considered uniformly. That means a single layer may not reach or exceed the sparsity setting in config, but the total pruned weights meet the sparsity setting.
dummy_input (Optional[torch.Tensor]) – The dummy input to analyze the topology constraints. Note that, the dummy_input should on the same device with the model.
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import TaylorFOWeightPruner >>> model = ... >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = TaylorFOWeightPruner(model, config_list, trainer, traced_optimizer, criterion, training_batches=20) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/taylorfo_pruning_torch.py
ADMM Pruner¶
- class nni.compression.pytorch.pruning.ADMMPruner(model, config_list, trainer, traced_optimizer, criterion, iterations, training_epochs, granularity='fine-grained')[source]¶
Alternating Direction Method of Multipliers (ADMM) is a mathematical optimization technique, by decomposing the original nonconvex problem into two subproblems that can be solved iteratively. In weight pruning problem, these two subproblems are solved via 1) gradient descent algorithm and 2) Euclidean projection respectively.
During the process of solving these two subproblems, the weights of the original model will be changed. Then a fine-grained pruning will be applied to prune the model according to the config list given.
This solution framework applies both to non-structured and different variations of structured pruning schemes.
For more details, please refer to A Systematic DNN Weight Pruning Framework using Alternating Direction Method of Multipliers.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
rho : Penalty parameters in ADMM algorithm.
op_types : Operation types to be pruned.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
trainer (Callable[[Module, Optimizer, Callable]) –
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
Example:
def trainer(model: Module, optimizer: Optimizer, criterion: Callable[[Tensor, Tensor], Tensor]): training = model.training model.train(mode=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # If you don't want to update the model, you can skip `optimizer.step()`, and set train mode False. optimizer.step() model.train(mode=training)
traced_optimizer (nni.common.serializer.Traceable(torch.optim.Optimizer)) – The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters()).criterion (Callable[[Tensor, Tensor], Tensor]) – The criterion function used in trainer. Take model output and target value as input, and return the loss.
iterations (int) – The total iteration number in admm pruning algorithm.
training_epochs (int) – The epoch number for training model in each iteration.
granularity (str) – ‘fine-grained’ or ‘coarse-grained’. If ‘coarse-grained’ is set, ADMM pruner will generate masks on output channels wise. In original admm pruning paper, author implemented a fine-grained admm pruning. In auto-compress paper, author used coarse-grained admm pruning.
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import ADMMPruner >>> model = ... >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = ADMMPruner(model, config_list, trainer, traced_optimizer, criterion, iterations=10, training_epochs=1) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/admm_pruning_torch.py
Scheduled Pruners¶
Linear Pruner¶
- class nni.compression.pytorch.pruning.LinearPruner(model, config_list, pruning_algorithm, total_iteration, log_dir='.', keep_intermediate_result=False, finetuner=None, speedup=False, dummy_input=None, evaluator=None, pruning_params={})[source]¶
Linear pruner is an iterative pruner, it will increase sparsity evenly from scratch during each iteration.
For example, the final sparsity is set as 0.5, and the iteration number is 5, then the sparsity used in each iteration are
[0, 0.1, 0.2, 0.3, 0.4, 0.5].- Parameters
model (Module) – The origin unwrapped pytorch model to be pruned.
config_list (List[Dict]) – The origin config list provided by the user.
pruning_algorithm (str) – Supported pruning algorithm [‘level’, ‘l1’, ‘l2’, ‘fpgm’, ‘slim’, ‘apoz’, ‘mean_activation’, ‘taylorfo’, ‘admm’]. This iterative pruner will use the chosen corresponding pruner to prune the model in each iteration.
total_iteration (int) – The total iteration number.
log_dir (str) – The log directory use to saving the result, you can find the best result under this folder.
keep_intermediate_result (bool) – If keeping the intermediate result, including intermediate model and masks during each iteration.
finetuner (Optional[Callable[[Module], None]]) – The finetuner handled all finetune logic, use a pytorch module as input. It will be called at the end of each iteration, usually for neutralizing the accuracy loss brought by the pruning in this iteration.
speedup (bool) – If set True, speedup the model at the end of each iteration to make the pruned model compact.
dummy_input (Optional[torch.Tensor]) – If speedup is True, dummy_input is required for tracing the model in speedup.
evaluator (Optional[Callable[[Module], float]]) – Evaluate the pruned model and give a score. If evaluator is None, the best result refers to the latest result.
pruning_params (Dict) – If the chosen pruning_algorithm has extra parameters, put them as a dict to pass in.
Examples
>>> from nni.compression.pytorch.pruning import LinearPruner >>> config_list = [{'sparsity': 0.8, 'op_types': ['Conv2d']}] >>> finetuner = ... >>> pruner = LinearPruner(model, config_list, pruning_algorithm='l1', total_iteration=10, finetuner=finetuner) >>> pruner.compress() >>> _, model, masks, _, _ = pruner.get_best_result()
For detailed example please refer to examples/model_compress/pruning/iterative_pruning_torch.py
AGP Pruner¶
- class nni.compression.pytorch.pruning.AGPPruner(model, config_list, pruning_algorithm, total_iteration, log_dir='.', keep_intermediate_result=False, finetuner=None, speedup=False, dummy_input=None, evaluator=None, pruning_params={})[source]¶
This is an iterative pruner, which the sparsity is increased from an initial sparsity value \(s_{i}\) (usually 0) to a final sparsity value \(s_{f}\) over a span of \(n\) pruning iterations, starting at training step \(t_{0}\) and with pruning frequency \(\Delta t\):
\(s_{t}=s_{f}+\left(s_{i}-s_{f}\right)\left(1-\frac{t-t_{0}}{n \Delta t}\right)^{3} \text { for } t \in\left\{t_{0}, t_{0}+\Delta t, \ldots, t_{0} + n \Delta t\right\}\)
For more details please refer to To prune, or not to prune: exploring the efficacy of pruning for model compression.
- Parameters
model (Module) – The origin unwrapped pytorch model to be pruned.
config_list (List[Dict]) – The origin config list provided by the user.
pruning_algorithm (str) – Supported pruning algorithm [‘level’, ‘l1’, ‘l2’, ‘fpgm’, ‘slim’, ‘apoz’, ‘mean_activation’, ‘taylorfo’, ‘admm’]. This iterative pruner will use the chosen corresponding pruner to prune the model in each iteration.
total_iteration (int) – The total iteration number.
log_dir (str) – The log directory use to saving the result, you can find the best result under this folder.
keep_intermediate_result (bool) – If keeping the intermediate result, including intermediate model and masks during each iteration.
finetuner (Optional[Callable[[Module], None]]) – The finetuner handled all finetune logic, use a pytorch module as input. It will be called at the end of each iteration, usually for neutralizing the accuracy loss brought by the pruning in this iteration.
speedup (bool) – If set True, speedup the model at the end of each iteration to make the pruned model compact.
dummy_input (Optional[torch.Tensor]) – If speedup is True, dummy_input is required for tracing the model in speedup.
evaluator (Optional[Callable[[Module], float]]) – Evaluate the pruned model and give a score. If evaluator is None, the best result refers to the latest result.
pruning_params (Dict) – If the chosen pruning_algorithm has extra parameters, put them as a dict to pass in.
Examples
>>> from nni.compression.pytorch.pruning import AGPPruner >>> config_list = [{'sparsity': 0.8, 'op_types': ['Conv2d']}] >>> finetuner = ... >>> pruner = AGPPruner(model, config_list, pruning_algorithm='l1', total_iteration=10, finetuner=finetuner) >>> pruner.compress() >>> _, model, masks, _, _ = pruner.get_best_result()
For detailed example please refer to examples/model_compress/pruning/iterative_pruning_torch.py
Lottery Ticket Pruner¶
- class nni.compression.pytorch.pruning.LotteryTicketPruner(model, config_list, pruning_algorithm, total_iteration, log_dir='.', keep_intermediate_result=False, finetuner=None, speedup=False, dummy_input=None, evaluator=None, reset_weight=True, pruning_params={})[source]¶
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, authors Jonathan Frankle and Michael Carbin,provides comprehensive measurement and analysis, and articulate the lottery ticket hypothesis: dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that – when trained in isolation – reach test accuracy comparable to the original network in a similar number of iterations.
In this paper, the authors use the following process to prune a model, called iterative prunning:
Randomly initialize a neural network f(x;theta_0) (where theta0 follows D{theta}).
Train the network for j iterations, arriving at parameters theta_j.
Prune p% of the parameters in theta_j, creating a mask m.
Reset the remaining parameters to their values in theta_0, creating the winning ticket f(x;m*theta_0).
Repeat step 2, 3, and 4.
If the configured final sparsity is P (e.g., 0.8) and there are n times iterative pruning, each iterative pruning prunes 1-(1-P)^(1/n) of the weights that survive the previous round.
- Parameters
model (Module) – The origin unwrapped pytorch model to be pruned.
config_list (List[Dict]) – The origin config list provided by the user.
pruning_algorithm (str) – Supported pruning algorithm [‘level’, ‘l1’, ‘l2’, ‘fpgm’, ‘slim’, ‘apoz’, ‘mean_activation’, ‘taylorfo’, ‘admm’]. This iterative pruner will use the chosen corresponding pruner to prune the model in each iteration.
total_iteration (int) – The total iteration number.
log_dir (str) – The log directory use to saving the result, you can find the best result under this folder.
keep_intermediate_result (bool) – If keeping the intermediate result, including intermediate model and masks during each iteration.
finetuner (Optional[Callable[[Module], None]]) – The finetuner handled all finetune logic, use a pytorch module as input. It will be called at the end of each iteration if reset_weight is False, will be called at the beginning of each iteration otherwise.
speedup (bool) – If set True, speedup the model at the end of each iteration to make the pruned model compact.
dummy_input (Optional[torch.Tensor]) – If speedup is True, dummy_input is required for tracing the model in speedup.
evaluator (Optional[Callable[[Module], float]]) – Evaluate the pruned model and give a score. If evaluator is None, the best result refers to the latest result.
reset_weight (bool) – If set True, the model weight will reset to the original model weight at the end of each iteration step.
pruning_params (Dict) – If the chosen pruning_algorithm has extra parameters, put them as a dict to pass in.
Examples
>>> from nni.compression.pytorch.pruning import LotteryTicketPruner >>> config_list = [{'sparsity': 0.8, 'op_types': ['Conv2d']}] >>> finetuner = ... >>> pruner = LotteryTicketPruner(model, config_list, pruning_algorithm='l1', total_iteration=10, finetuner=finetuner, reset_weight=True) >>> pruner.compress() >>> _, model, masks, _, _ = pruner.get_best_result()
For detailed example please refer to examples/model_compress/pruning/iterative_pruning_torch.py
Simulated Annealing Pruner¶
- class nni.compression.pytorch.pruning.SimulatedAnnealingPruner(model, config_list, evaluator, start_temperature=100, stop_temperature=20, cool_down_rate=0.9, perturbation_magnitude=0.35, pruning_algorithm='level', pruning_params={}, log_dir='.', keep_intermediate_result=False, finetuner=None, speedup=False, dummy_input=None)[source]¶
We implement a guided heuristic search method, Simulated Annealing (SA) algorithm. As mentioned in the paper, this method is enhanced on guided search based on prior experience. The enhanced SA technique is based on the observation that a DNN layer with more number of weights often has a higher degree of model compression with less impact on overall accuracy.
Randomly initialize a pruning rate distribution (sparsities).
While current_temperature < stop_temperature:
generate a perturbation to current distribution
Perform fast evaluation on the perturbated distribution
accept the perturbation according to the performance and probability, if not accepted, return to step 1
cool down, current_temperature <- current_temperature * cool_down_rate
For more details, please refer to AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates.
- Parameters
model (Optional[Module]) – The origin unwrapped pytorch model to be pruned.
config_list (Optional[List[Dict]]) – The origin config list provided by the user.
evaluator (Callable[[Module], float]) – Evaluate the pruned model and give a score.
start_temperature (float) – Start temperature of the simulated annealing process.
stop_temperature (float) – Stop temperature of the simulated annealing process.
cool_down_rate (float) – Cool down rate of the temperature.
perturbation_magnitude (float) – Initial perturbation magnitude to the sparsities. The magnitude decreases with current temperature.
pruning_algorithm (str) – Supported pruning algorithm [‘level’, ‘l1’, ‘l2’, ‘fpgm’, ‘slim’, ‘apoz’, ‘mean_activation’, ‘taylorfo’, ‘admm’]. This iterative pruner will use the chosen corresponding pruner to prune the model in each iteration.
pruning_params (Dict) – If the chosen pruning_algorithm has extra parameters, put them as a dict to pass in.
log_dir (Union[str, Path]) – The log directory use to saving the result, you can find the best result under this folder.
keep_intermediate_result (bool) – If keeping the intermediate result, including intermediate model and masks during each iteration.
finetuner (Optional[Callable[[Module], None]]) – The finetuner handled all finetune logic, use a pytorch module as input, will be called in each iteration.
speedup (bool) – If set True, speedup the model at the end of each iteration to make the pruned model compact.
dummy_input (Optional[torch.Tensor]) – If speedup is True, dummy_input is required for tracing the model in speedup.
Examples
>>> from nni.compression.pytorch.pruning import SimulatedAnnealingPruner >>> model = ... >>> config_list = [{'sparsity': 0.8, 'op_types': ['Conv2d']}] >>> evaluator = ... >>> finetuner = ... >>> pruner = SimulatedAnnealingPruner(model, config_list, pruning_algorithm='l1', evaluator=evaluator, cool_down_rate=0.9, finetuner=finetuner) >>> pruner.compress() >>> _, model, masks, _, _ = pruner.get_best_result()
For detailed example please refer to examples/model_compress/pruning/simulated_anealing_pruning_torch.py
Auto Compress Pruner¶
- class nni.compression.pytorch.pruning.AutoCompressPruner(model, config_list, total_iteration, admm_params, sa_params, log_dir='.', keep_intermediate_result=False, finetuner=None, speedup=False, dummy_input=None, evaluator=None)[source]¶
For total iteration number \(N\), AutoCompressPruner prune the model that survive the previous iteration for a fixed sparsity ratio (e.g., \(1-{(1-0.8)}^{(1/N)}\)) to achieve the overall sparsity (e.g., \(0.8\)):
1. Generate sparsities distribution using SimulatedAnnealingPruner 2. Perform ADMM-based pruning to generate pruning result for the next iteration.
For more details, please refer to AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates.
- Parameters
model (Module) – The origin unwrapped pytorch model to be pruned.
config_list (List[Dict]) – The origin config list provided by the user.
total_iteration (int) – The total iteration number.
evaluator (Callable[[Module], float]) – Evaluate the pruned model and give a score.
admm_params (Dict) –
The parameters passed to the ADMMPruner.
- trainerCallable[[Module, Optimizer, Callable].
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
- traced_optimizernni.common.serializer.Traceable(torch.optim.Optimizer)
The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters()).
- criterionCallable[[Tensor, Tensor], Tensor].
The criterion function used in trainer. Take model output and target value as input, and return the loss.
- iterationsint.
The total iteration number in admm pruning algorithm.
- training_epochsint.
The epoch number for training model in each iteration.
sa_params (Dict) –
The parameters passed to the SimulatedAnnealingPruner.
- evaluatorCallable[[Module], float]. Required.
Evaluate the pruned model and give a score.
- start_temperaturefloat. Default: 100.
Start temperature of the simulated annealing process.
- stop_temperaturefloat. Default: 20.
Stop temperature of the simulated annealing process.
- cool_down_ratefloat. Default: 0.9.
Cooldown rate of the temperature.
- perturbation_magnitudefloat. Default: 0.35.
Initial perturbation magnitude to the sparsities. The magnitude decreases with current temperature.
- pruning_algorithmstr. Default: ‘level’.
Supported pruning algorithm [‘level’, ‘l1’, ‘l2’, ‘fpgm’, ‘slim’, ‘apoz’, ‘mean_activation’, ‘taylorfo’, ‘admm’].
- pruning_paramsDict. Default: {}.
If the chosen pruning_algorithm has extra parameters, put them as a dict to pass in.
log_dir (str) – The log directory used to save the result, you can find the best result under this folder.
keep_intermediate_result (bool) – If keeping the intermediate result, including intermediate model and masks during each iteration.
finetuner (Optional[Callable[[Module], None]]) – The finetuner handles all finetune logic, takes a pytorch module as input. It will be called at the end of each iteration, usually for neutralizing the accuracy loss brought by the pruning in this iteration.
speedup (bool) – If set True, speedup the model at the end of each iteration to make the pruned model compact.
dummy_input (Optional[torch.Tensor]) – If speedup is True, dummy_input is required for tracing the model in speedup.
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import AutoCompressPruner >>> model = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> evaluator = ... >>> finetuner = ... >>> admm_params = { >>> 'trainer': trainer, >>> 'traced_optimizer': traced_optimizer, >>> 'criterion': criterion, >>> 'iterations': 10, >>> 'training_epochs': 1 >>> } >>> sa_params = { >>> 'evaluator': evaluator >>> } >>> pruner = AutoCompressPruner(model, config_list, 10, admm_params, sa_params, finetuner=finetuner) >>> pruner.compress() >>> _, model, masks, _, _ = pruner.get_best_result()
The full script can be found here.
AMC Pruner¶
- class nni.compression.pytorch.pruning.AMCPruner(total_episode, model, config_list, dummy_input, evaluator, pruning_algorithm='l1', log_dir='.', keep_intermediate_result=False, finetuner=None, ddpg_params={}, pruning_params={}, target='flops')[source]¶
AMC pruner leverages reinforcement learning to provide the model compression policy. According to the author, this learning-based compression policy outperforms conventional rule-based compression policy by having a higher compression ratio, better preserving the accuracy and freeing human labor.
For more details, please refer to AMC: AutoML for Model Compression and Acceleration on Mobile Devices.
Suggust config all total_sparsity in config_list a same value. AMC pruner will treat the first sparsity in config_list as the global sparsity.
- Parameters
total_episode (int) – The total episode number.
model (Module) – The model to be pruned.
config_list (List[Dict]) –
- Supported keys :
total_sparsity : This is to specify the total sparsity for all layers in this config, each layer may have different sparsity.
max_sparsity_per_layer : Always used with total_sparsity. Limit the max sparsity of each layer.
op_types : Operation type to be pruned.
op_names : Operation name to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
dummy_input (torch.Tensor) – dummy_input is required for speedup and tracing the model in RL environment.
evaluator (Callable[[Module], float]) – Evaluate the pruned model and give a score.
pruning_algorithm (str) – Supported pruning algorithm [‘l1’, ‘l2’, ‘fpgm’, ‘apoz’, ‘mean_activation’, ‘taylorfo’]. This iterative pruner will use the chosen corresponding pruner to prune the model in each iteration.
log_dir (str) – The log directory use to saving the result, you can find the best result under this folder.
keep_intermediate_result (bool) – If keeping the intermediate result, including intermediate model and masks during each iteration.
finetuner (Optional[Callable[[Module], None]]) – The finetuner handled all finetune logic, use a pytorch module as input, will be called in each iteration.
ddpg_params (Dict) – Configuration dict to configure the DDPG agent, any key unset will be set to default implicitly. - hidden1: hidden num of first fully connect layer. Default: 300 - hidden2: hidden num of second fully connect layer. Default: 300 - lr_c: learning rate for critic. Default: 1e-3 - lr_a: learning rate for actor. Default: 1e-4 - warmup: number of episodes without training but only filling the replay memory. During warmup episodes, random actions ares used for pruning. Default: 100 - discount: next Q value discount for deep Q value target. Default: 0.99 - bsize: minibatch size for training DDPG agent. Default: 64 - rmsize: memory size for each layer. Default: 100 - window_length: replay buffer window length. Default: 1 - tau: moving average for target network being used by soft_update. Default: 0.99 - init_delta: initial variance of truncated normal distribution. Default: 0.5 - delta_decay: delta decay during exploration. Default: 0.99 # parameters for training ddpg agent - max_episode_length: maximum episode length. Default: 1e9 - epsilon: linear decay of exploration policy. Default: 50000
pruning_params (Dict) – If the pruner corresponding to the chosen pruning_algorithm has extra parameters, put them as a dict to pass in.
target (str) – ‘flops’ or ‘params’. Note that the sparsity in other pruners always means the parameters sparse, but in AMC, you can choose flops sparse. This parameter is used to explain what the sparsity setting in config_list refers to.
Examples
>>> from nni.compression.pytorch.pruning import AMCPruner >>> config_list = [{'op_types': ['Conv2d'], 'total_sparsity': 0.5, 'max_sparsity_per_layer': 0.8}] >>> dummy_input = torch.rand(...).to(device) >>> evaluator = ... >>> finetuner = ... >>> pruner = AMCPruner(400, model, config_list, dummy_input, evaluator, finetuner=finetuner) >>> pruner.compress()
The full script can be found here.
Other Pruner¶
Movement Pruner¶
- class nni.compression.pytorch.pruning.MovementPruner(model, config_list, trainer, traced_optimizer, criterion, training_epochs, warm_up_step, cool_down_beginning_step)[source]¶
Movement pruner is an implementation of movement pruning. This is a “fine-pruning” algorithm, which means the masks may change during each fine-tuning step. Each weight element will be scored by the opposite of the sum of the product of weight and its gradient during each step. This means the weight elements moving towards zero will accumulate negative scores, the weight elements moving away from zero will accumulate positive scores. The weight elements with low scores will be masked during inference.
The following figure from the paper shows the weight pruning by movement pruning.
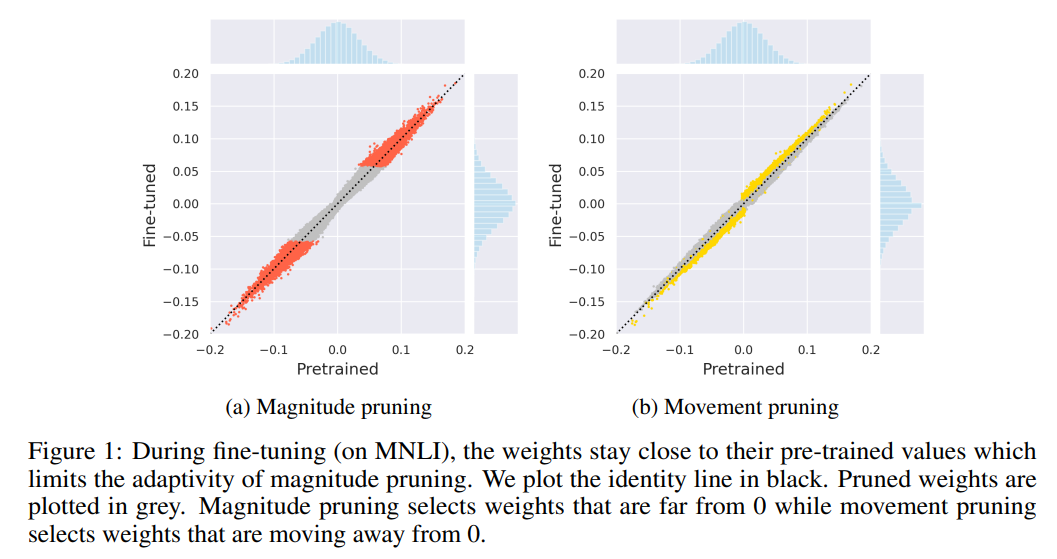
For more details, please refer to Movement Pruning: Adaptive Sparsity by Fine-Tuning.
- Parameters
model (torch.nn.Module) – Model to be pruned.
config_list (List[Dict]) –
- Supported keys:
sparsity : This is to specify the sparsity for each layer in this config to be compressed.
sparsity_per_layer : Equals to sparsity.
op_types : Operation types to be pruned.
op_names : Operation names to be pruned.
op_partial_names: Operation partial names to be pruned, will be autocompleted by NNI.
exclude : Set True then the layers setting by op_types and op_names will be excluded from pruning.
trainer (Callable[[Module, Optimizer, Callable]) –
A callable function used to train model or just inference. Take model, optimizer, criterion as input. The model will be trained or inferenced training_epochs epochs.
Example:
def trainer(model: Module, optimizer: Optimizer, criterion: Callable[[Tensor, Tensor], Tensor]): training = model.training model.train(mode=True) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # If you don't want to update the model, you can skip `optimizer.step()`, and set train mode False. optimizer.step() model.train(mode=training)
traced_optimizer (nni.common.serializer.Traceable(torch.optim.Optimizer)) – The traced optimizer instance which the optimizer class is wrapped by nni.trace. E.g.
traced_optimizer = nni.trace(torch.nn.Adam)(model.parameters()).criterion (Callable[[Tensor, Tensor], Tensor]) – The criterion function used in trainer. Take model output and target value as input, and return the loss.
training_epochs (int) – The total epoch number for training the model. Make sure the total optimizer.step() in training_epochs is bigger than cool_down_beginning_step.
warm_up_step (int) – The total optimizer.step() number before start pruning for warm up. Make sure warm_up_step is smaller than cool_down_beginning_step.
cool_down_beginning_step (int) – The number of steps at which sparsity stops growing, note that the sparsity stop growing doesn’t mean masks not changed. The sparsity after each optimizer.step() is: total_sparsity * (1 - (1 - (current_step - warm_up_step) / (cool_down_beginning_step - warm_up_step)) ** 3).
Examples
>>> import nni >>> from nni.compression.pytorch.pruning import MovementPruner >>> model = ... >>> # make sure you have used nni.trace to wrap the optimizer class before initialize >>> traced_optimizer = nni.trace(torch.optim.Adam)(model.parameters()) >>> trainer = ... >>> criterion = ... >>> config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }] >>> pruner = MovementPruner(model, config_list, trainer, traced_optimizer, criterion, 10, 3000, 27000) >>> masked_model, masks = pruner.compress()
For detailed example please refer to examples/model_compress/pruning/movement_pruning_glue.py
