Knowledge Distillation on NNI Compressor¶
KnowledgeDistill¶
Knowledge distillation support, in Distilling the Knowledge in a Neural Network, the compressed model is trained to mimic a pre-trained, larger model. This training setting is also referred to as “teacher-student”, where the large model is the teacher and the small model is the student.
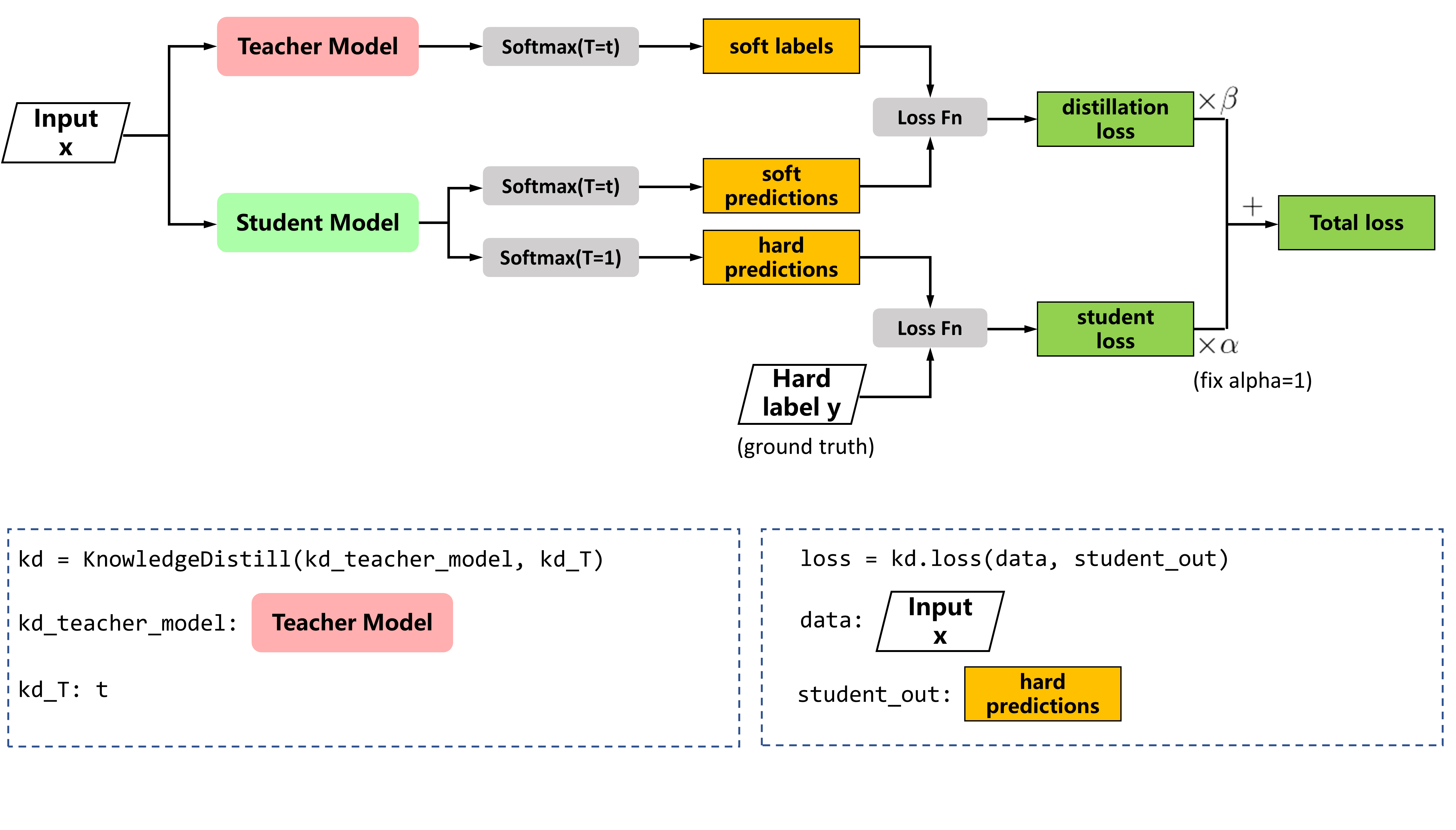
Usage¶
PyTorch code
from knowledge_distill.knowledge_distill import KnowledgeDistill
kd = KnowledgeDistill(kd_teacher_model, kd_T=5)
alpha = 1
beta = 0.8
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
# you only to add the following line to fine-tune with knowledge distillation
loss = alpha * loss + beta * kd.loss(data=data, student_out=output)
loss.backward()