Lottery Ticket Hypothesis on NNI¶
Introduction¶
The paper The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks is mainly a measurement and analysis paper, it delivers very interesting insights. To support it on NNI, we mainly implement the training approach for finding winning tickets.
In this paper, the authors use the following process to prune a model, called iterative prunning:
- Randomly initialize a neural network f(x;theta_0) (where theta_0 follows D_{theta}).
- Train the network for j iterations, arriving at parameters theta_j.
- Prune p% of the parameters in theta_j, creating a mask m.
- Reset the remaining parameters to their values in theta_0, creating the winning ticket f(x;m*theta_0).
- Repeat step 2, 3, and 4.
If the configured final sparsity is P (e.g., 0.8) and there are n times iterative pruning, each iterative pruning prunes 1-(1-P)^(1/n) of the weights that survive the previous round.
Reproduce Results¶
We try to reproduce the experiment result of the fully connected network on MNIST using the same configuration as in the paper. The code can be referred here. In this experiment, we prune 10 times, for each pruning we train the pruned model for 50 epochs.
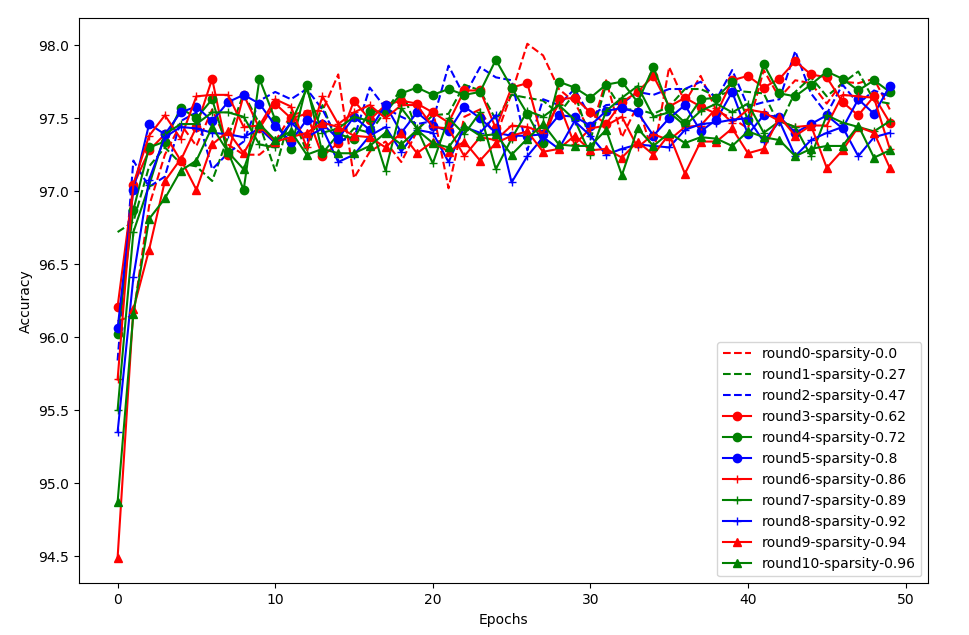
The above figure shows the result of the fully connected network. round0-sparsity-0.0 is the performance without pruning. Consistent with the paper, pruning around 80% also obtain similar performance compared to non-pruning, and converges a little faster. If pruning too much, e.g., larger than 94%, the accuracy becomes lower and convergence becomes a little slower. A little different from the paper, the trend of the data in the paper is relatively more clear.