Supported Pruning Algorithms on NNI¶
We provide several pruning algorithms that support fine-grained weight pruning and structural filter pruning. Fine-grained Pruning generally results in unstructured models, which need specialized haredware or software to speed up the sparse network. Filter Pruning achieves acceleratation by removing the entire filter. We also provide an algorithm to control the pruning schedule.
Fine-grained Pruning
Filter Pruning
- Slim Pruner
- FPGM Pruner
- L1Filter Pruner
- L2Filter Pruner
- Activation APoZ Rank Filter Pruner
- Activation Mean Rank Filter Pruner
- Taylor FO On Weight Pruner
Pruning Schedule
- AGP Pruner
- NetAdapt Pruner
- SimulatedAnnealing Pruner
- AutoCompress Pruner
- AutoML for Model Compression Pruner
- Sensitivity Pruner
Others
Level Pruner¶
This is one basic one-shot pruner: you can set a target sparsity level (expressed as a fraction, 0.6 means we will prune 60% of the weight parameters).
We first sort the weights in the specified layer by their absolute values. And then mask to zero the smallest magnitude weights until the desired sparsity level is reached.
Usage¶
Tensorflow code
from nni.compression.tensorflow import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(model, config_list)
pruner.compress()
PyTorch code
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(model, config_list)
pruner.compress()
User configuration for Level Pruner¶
PyTorch¶
-
class
nni.compression.torch.LevelPruner(model, config_list, optimizer=None)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : This is to specify the sparsity operations to be compressed to.
- op_types : Operation types to prune.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
Tensorflow¶
Slim Pruner¶
This is an one-shot pruner, In ‘Learning Efficient Convolutional Networks through Network Slimming’, authors Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan and Changshui Zhang.
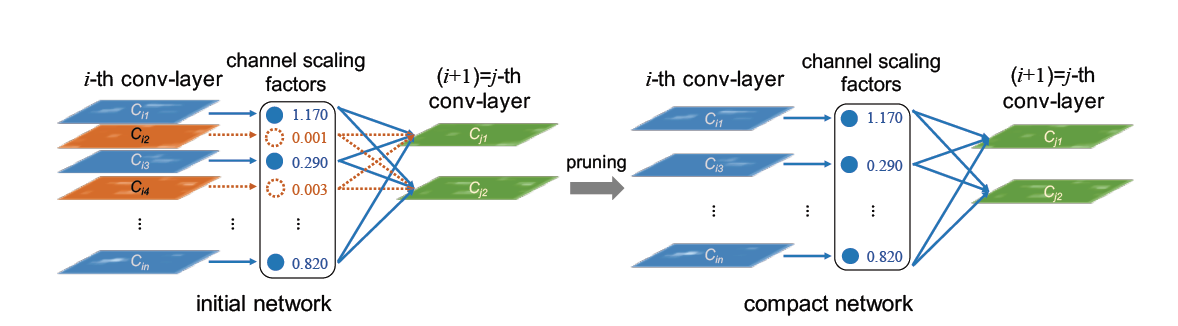
Slim Pruner prunes channels in the convolution layers by masking corresponding scaling factors in the later BN layers, L1 regularization on the scaling factors should be applied in batch normalization (BN) layers while training, scaling factors of BN layers are globally ranked while pruning, so the sparse model can be automatically found given sparsity.
Usage¶
PyTorch code
from nni.compression.torch import SlimPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['BatchNorm2d'] }]
pruner = SlimPruner(model, config_list)
pruner.compress()
User configuration for Slim Pruner¶
PyTorch¶
-
class
nni.compression.torch.SlimPruner(model, config_list, optimizer=None)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : This is to specify the sparsity operations to be compressed to.
- op_types : Only BatchNorm2d is supported in Slim Pruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
Reproduced Experiment¶
We implemented one of the experiments in ‘Learning Efficient Convolutional Networks through Network Slimming’, we pruned $70%$ channels in the VGGNet for CIFAR-10 in the paper, in which $88.5%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
|---|---|---|---|
| VGGNet | 6.34/6.40 | 20.04M | |
| Pruned-VGGNet | 6.20/6.26 | 2.03M | 88.5% |
The experiments code can be found at examples/model_compress
FPGM Pruner¶
This is an one-shot pruner, FPGM Pruner is an implementation of paper Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration
FPGMPruner prune filters with the smallest geometric median.
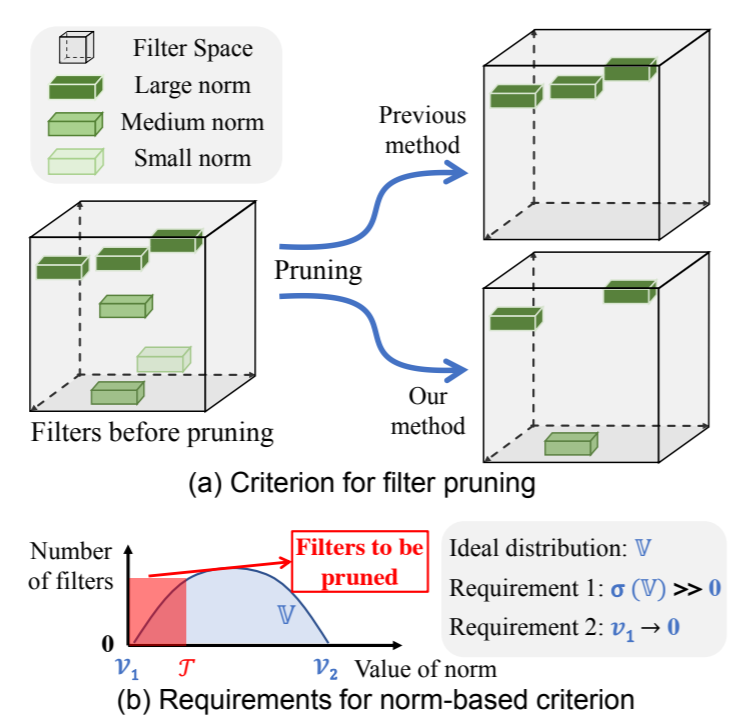
Previous works utilized “smaller-norm-less-important” criterion to prune filters with smaller norm values in a convolutional neural network. In this paper, we analyze this norm-based criterion and point out that its effectiveness depends on two requirements that are not always met: (1) the norm deviation of the filters should be large; (2) the minimum norm of the filters should be small. To solve this problem, we propose a novel filter pruning method, namely Filter Pruning via Geometric Median (FPGM), to compress the model regardless of those two requirements. Unlike previous methods, FPGM compresses CNN models by pruning filters with redundancy, rather than those with “relatively less” importance.
Usage¶
PyTorch code
from nni.compression.torch import FPGMPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = FPGMPruner(model, config_list)
pruner.compress()
User configuration for FPGM Pruner¶
PyTorch¶
-
class
nni.compression.torch.FPGMPruner(model, config_list, optimizer=None)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : This is to specify the sparsity operations to be compressed to.
- op_types : Only Conv2d is supported in FPGM Pruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
L1Filter Pruner¶
This is an one-shot pruner, In ‘PRUNING FILTERS FOR EFFICIENT CONVNETS’, authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.
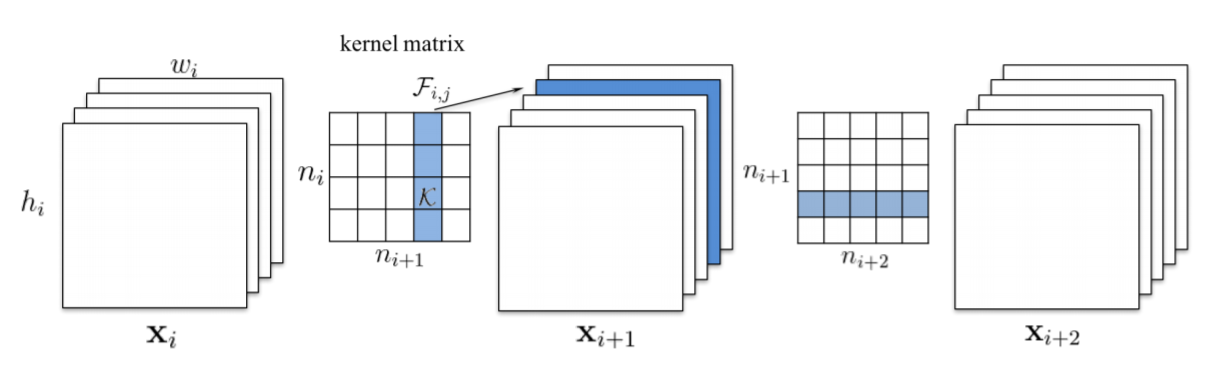
L1Filter Pruner prunes filters in the convolution layers
The procedure of pruning m filters from the ith convolutional layer is as follows:
- For each filter
, calculate the sum of its absolute kernel weights
- Sort the filters by
.
- Prune
filters with the smallest sum values and their corresponding feature maps. The kernels in the next convolutional layer corresponding to the pruned feature maps are also removed.
- A new kernel matrix is created for both the
th and
th layers, and the remaining kernel weights are copied to the new model.
Usage¶
PyTorch code
from nni.compression.torch import L1FilterPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }]
pruner = L1FilterPruner(model, config_list)
pruner.compress()
User configuration for L1Filter Pruner¶
PyTorch¶
-
class
nni.compression.torch.L1FilterPruner(model, config_list, optimizer=None)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : This is to specify the sparsity operations to be compressed to.
- op_types : Only Conv2d is supported in L1FilterPruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
Reproduced Experiment¶
We implemented one of the experiments in ‘PRUNING FILTERS FOR EFFICIENT CONVNETS’ with L1FilterPruner, we pruned VGG-16 for CIFAR-10 to VGG-16-pruned-A in the paper, in which $64%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
|---|---|---|---|
| VGG-16 | 6.75/6.49 | 1.5x10^7 | |
| VGG-16-pruned-A | 6.60/6.47 | 5.4x10^6 | 64.0% |
The experiments code can be found at examples/model_compress
L2Filter Pruner¶
This is a structured pruning algorithm that prunes the filters with the smallest L2 norm of the weights. It is implemented as a one-shot pruner.
Usage¶
PyTorch code
from nni.compression.torch import L2FilterPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }]
pruner = L2FilterPruner(model, config_list)
pruner.compress()
User configuration for L2Filter Pruner¶
PyTorch¶
-
class
nni.compression.torch.L2FilterPruner(model, config_list, optimizer=None)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : This is to specify the sparsity operations to be compressed to.
- op_types : Only Conv2d is supported in L2FilterPruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
ActivationAPoZRankFilter Pruner¶
ActivationAPoZRankFilter Pruner is a pruner which prunes the filters with the smallest importance criterion APoZ calculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterion APoZ is explained in the paper Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures.
The APoZ is defined as:
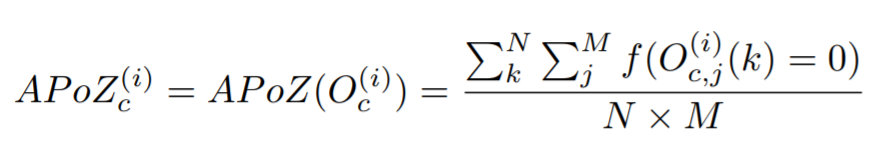
Usage¶
PyTorch code
from nni.compression.torch import ActivationAPoZRankFilterPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = ActivationAPoZRankFilterPruner(model, config_list, statistics_batch_num=1)
pruner.compress()
Note: ActivationAPoZRankFilterPruner is used to prune convolutional layers within deep neural networks, therefore the op_types field supports only convolutional layers.
You can view example for more information.
User configuration for ActivationAPoZRankFilter Pruner¶
PyTorch¶
-
class
nni.compression.torch.ActivationAPoZRankFilterPruner(model, config_list, optimizer=None, activation='relu', statistics_batch_num=1)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : How much percentage of convolutional filters are to be pruned.
- op_types : Only Conv2d is supported in ActivationAPoZRankFilterPruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
ActivationMeanRankFilter Pruner¶
ActivationMeanRankFilterPruner is a pruner which prunes the filters with the smallest importance criterion mean activation calculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterion mean activation is explained in section 2.2 of the paperPruning Convolutional Neural Networks for Resource Efficient Inference. Other pruning criteria mentioned in this paper will be supported in future release.
Usage¶
PyTorch code
from nni.compression.torch import ActivationMeanRankFilterPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = ActivationMeanRankFilterPruner(model, config_list, statistics_batch_num=1)
pruner.compress()
Note: ActivationMeanRankFilterPruner is used to prune convolutional layers within deep neural networks, therefore the op_types field supports only convolutional layers.
You can view example for more information.
User configuration for ActivationMeanRankFilterPruner¶
PyTorch¶
-
class
nni.compression.torch.ActivationMeanRankFilterPruner(model, config_list, optimizer=None, activation='relu', statistics_batch_num=1)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : How much percentage of convolutional filters are to be pruned.
- op_types : Only Conv2d is supported in ActivationMeanRankFilterPruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
TaylorFOWeightFilter Pruner¶
TaylorFOWeightFilter Pruner is a pruner which prunes convolutional layers based on estimated importance calculated from the first order taylor expansion on weights to achieve a preset level of network sparsity. The estimated importance of filters is defined as the paper Importance Estimation for Neural Network Pruning. Other pruning criteria mentioned in this paper will be supported in future release.
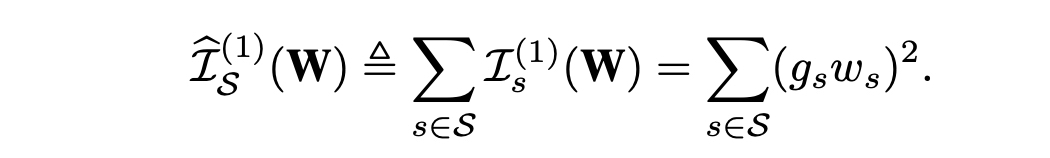
Usage¶
PyTorch code
from nni.compression.torch import TaylorFOWeightFilterPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = TaylorFOWeightFilterPruner(model, config_list, statistics_batch_num=1)
pruner.compress()
User configuration for TaylorFOWeightFilter Pruner¶
PyTorch¶
-
class
nni.compression.torch.TaylorFOWeightFilterPruner(model, config_list, optimizer=None, statistics_batch_num=1)[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned
- config_list (list) –
- Supported keys:
- sparsity : How much percentage of convolutional filters are to be pruned.
- op_types : Currently only Conv2d is supported in TaylorFOWeightFilterPruner.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model
AGP Pruner¶
This is an iterative pruner, In To prune, or not to prune: exploring the efficacy of pruning for model compression, authors Michael Zhu and Suyog Gupta provide an algorithm to prune the weight gradually.
We introduce a new automated gradual pruning algorithm in which the sparsity is increased from an initial sparsity value si (usually 0) to a final sparsity value sf over a span of n pruning steps, starting at training step t0 and with pruning frequency ∆t:
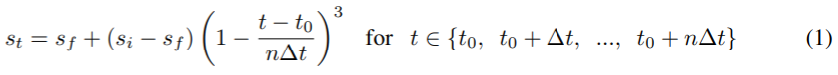
The binary weight masks are updated every ∆t steps as the network is trained to gradually increase the sparsity of the network while allowing the network training steps to recover from any pruning-induced loss in accuracy. In our experience, varying the pruning frequency ∆t between 100 and 1000 training steps had a negligible impact on the final model quality. Once the model achieves the target sparsity sf , the weight masks are no longer updated. The intuition behind this sparsity function in equation (1).
Usage¶
You can prune all weight from 0% to 80% sparsity in 10 epoch with the code below.
PyTorch code
from nni.compression.torch import AGPPruner
config_list = [{
'initial_sparsity': 0,
'final_sparsity': 0.8,
'start_epoch': 0,
'end_epoch': 10,
'frequency': 1,
'op_types': ['default']
}]
# load a pretrained model or train a model before using a pruner
# model = MyModel()
# model.load_state_dict(torch.load('mycheckpoint.pth'))
# AGP pruner prunes model while fine tuning the model by adding a hook on
# optimizer.step(), so an optimizer is required to prune the model.
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
pruner = AGPPruner(model, config_list, optimizer, pruning_algorithm='level')
pruner.compress()
AGP pruner uses LevelPruner algorithms to prune the weight by default, however you can set pruning_algorithm parameter to other values to use other pruning algorithms:
level: LevelPrunerslim: SlimPrunerl1: L1FilterPrunerl2: L2FilterPrunerfpgm: FPGMPrunertaylorfo: TaylorFOWeightFilterPrunerapoz: ActivationAPoZRankFilterPrunermean_activation: ActivationMeanRankFilterPruner
You should add code below to update epoch number when you finish one epoch in your training code.
PyTorch code
pruner.update_epoch(epoch)
You can view example for more information.
User configuration for AGP Pruner¶
PyTorch¶
-
class
nni.compression.torch.AGPPruner(model, config_list, optimizer, pruning_algorithm='level')[source]¶ Parameters: - model (torch.nn.Module) – Model to be pruned.
- config_list (listlist) –
- Supported keys:
- initial_sparsity: This is to specify the sparsity when compressor starts to compress.
- final_sparsity: This is to specify the sparsity when compressor finishes to compress.
- start_epoch: This is to specify the epoch number when compressor starts to compress, default start from epoch 0.
- end_epoch: This is to specify the epoch number when compressor finishes to compress.
- frequency: This is to specify every frequency number epochs compressor compress once, default frequency=1.
- optimizer (torch.optim.Optimizer) – Optimizer used to train model.
- pruning_algorithm (str) – Algorithms being used to prune model, choose from [‘level’, ‘slim’, ‘l1’, ‘l2’, ‘fpgm’, ‘taylorfo’, ‘apoz’, ‘mean_activation’], by default level
NetAdapt Pruner¶
NetAdapt allows a user to automatically simplify a pretrained network to meet the resource budget. Given the overall sparsity, NetAdapt will automatically generate the sparsities distribution among different layers by iterative pruning.
For more details, please refer to NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications.

Usage¶
PyTorch code
from nni.compression.torch import NetAdaptPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = NetAdaptPruner(model, config_list, short_term_fine_tuner=short_term_fine_tuner, evaluator=evaluator,base_algo='l1', experiment_data_dir='./')
pruner.compress()
You can view example for more information.
User configuration for NetAdapt Pruner¶
PyTorch¶
-
class
nni.compression.torch.NetAdaptPruner(model, config_list, short_term_fine_tuner, evaluator, optimize_mode='maximize', base_algo='l1', sparsity_per_iteration=0.05, experiment_data_dir='./')[source]¶ A Pytorch implementation of NetAdapt compression algorithm.
Parameters: - model (pytorch model) – The model to be pruned.
- config_list (list) –
- Supported keys:
- sparsity : The target overall sparsity.
- op_types : The operation type to prune.
- short_term_fine_tuner (function) –
function to short-term fine tune the masked model. This function should include model as the only parameter, and fine tune the model for a short term after each pruning iteration. Example:
def short_term_fine_tuner(model, epoch=3): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") train_loader = ... criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.01) model.train() for _ in range(epoch): for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() optimizer.step()
- evaluator (function) –
function to evaluate the masked model. This function should include model as the only parameter, and returns a scalar value. Example:
def evaluator(model): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") val_loader = ... model.eval() correct = 0 with torch.no_grad(): for data, target in val_loader: data, target = data.to(device), target.to(device) output = model(data) # get the index of the max log-probability pred = output.argmax(dim=1, keepdim=True) correct += pred.eq(target.view_as(pred)).sum().item() accuracy = correct / len(val_loader.dataset) return accuracy
- optimize_mode (str) – optimize mode, maximize or minimize, by default maximize.
- base_algo (str) – Base pruning algorithm. level, l1 or l2, by default l1. Given the sparsity distribution among the ops, the assigned base_algo is used to decide which filters/channels/weights to prune.
- sparsity_per_iteration (float) – sparsity to prune in each iteration.
- experiment_data_dir (str) – PATH to save experiment data, including the config_list generated for the base pruning algorithm and the performance of the pruned model.
SimulatedAnnealing Pruner¶
We implement a guided heuristic search method, Simulated Annealing (SA) algorithm, with enhancement on guided search based on prior experience. The enhanced SA technique is based on the observation that a DNN layer with more number of weights often has a higher degree of model compression with less impact on overall accuracy.
- Randomly initialize a pruning rate distribution (sparsities).
- While current_temperature < stop_temperature:
- generate a perturbation to current distribution
- Perform fast evaluation on the perturbated distribution
- accept the perturbation according to the performance and probability, if not accepted, return to step 1
- cool down, current_temperature <- current_temperature * cool_down_rate
For more details, please refer to AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates.
Usage¶
PyTorch code
from nni.compression.torch import SimulatedAnnealingPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = SimulatedAnnealingPruner(model, config_list, evaluator=evaluator, base_algo='l1', cool_down_rate=0.9, experiment_data_dir='./')
pruner.compress()
You can view example for more information.
User configuration for SimulatedAnnealing Pruner¶
PyTorch¶
-
class
nni.compression.torch.SimulatedAnnealingPruner(model, config_list, evaluator, optimize_mode='maximize', base_algo='l1', start_temperature=100, stop_temperature=20, cool_down_rate=0.9, perturbation_magnitude=0.35, experiment_data_dir='./')[source]¶ A Pytorch implementation of Simulated Annealing compression algorithm.
Parameters: - model (pytorch model) – The model to be pruned.
- config_list (list) –
- Supported keys:
- sparsity : The target overall sparsity.
- op_types : The operation type to prune.
- evaluator (function) –
Function to evaluate the pruned model. This function should include model as the only parameter, and returns a scalar value. Example:
def evaluator(model): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") val_loader = ... model.eval() correct = 0 with torch.no_grad(): for data, target in val_loader: data, target = data.to(device), target.to(device) output = model(data) # get the index of the max log-probability pred = output.argmax(dim=1, keepdim=True) correct += pred.eq(target.view_as(pred)).sum().item() accuracy = correct / len(val_loader.dataset) return accuracy
- optimize_mode (str) – Optimize mode, maximize or minimize, by default maximize.
- base_algo (str) – Base pruning algorithm. level, l1 or l2, by default l1. Given the sparsity distribution among the ops, the assigned base_algo is used to decide which filters/channels/weights to prune.
- start_temperature (float) – Start temperature of the simulated annealing process.
- stop_temperature (float) – Stop temperature of the simulated annealing process.
- cool_down_rate (float) – Cool down rate of the temperature.
- perturbation_magnitude (float) – Initial perturbation magnitude to the sparsities. The magnitude decreases with current temperature.
- experiment_data_dir (string) – PATH to save experiment data, including the config_list generated for the base pruning algorithm, the performance of the pruned model and the pruning history.
AutoCompress Pruner¶
For each round, AutoCompressPruner prune the model for the same sparsity to achive the overall sparsity:
1. Generate sparsities distribution using SimulatedAnnealingPruner
2. Perform ADMM-based structured pruning to generate pruning result for the next round.
Here we use speedup to perform real pruning.
For more details, please refer to AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates.
Usage¶
PyTorch code
from nni.compression.torch import ADMMPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = AutoCompressPruner(
model, config_list, trainer=trainer, evaluator=evaluator,
dummy_input=dummy_input, num_iterations=3, optimize_mode='maximize', base_algo='l1',
cool_down_rate=0.9, admm_num_iterations=30, admm_training_epochs=5, experiment_data_dir='./')
pruner.compress()
You can view example for more information.
User configuration for AutoCompress Pruner¶
PyTorch¶
-
class
nni.compression.torch.AutoCompressPruner(model, config_list, trainer, evaluator, dummy_input, num_iterations=3, optimize_mode='maximize', base_algo='l1', start_temperature=100, stop_temperature=20, cool_down_rate=0.9, perturbation_magnitude=0.35, admm_num_iterations=30, admm_training_epochs=5, row=0.0001, experiment_data_dir='./')[source]¶ A Pytorch implementation of AutoCompress pruning algorithm.
Parameters: - model (pytorch model) – The model to be pruned.
- config_list (list) –
- Supported keys:
- sparsity : The target overall sparsity.
- op_types : The operation type to prune.
- trainer (function) –
Function used for the first subproblem of ADMM Pruner. Users should write this function as a normal function to train the Pytorch model and include model, optimizer, criterion, epoch, callback as function arguments. Here callback acts as an L2 regulizer as presented in the formula (7) of the original paper. The logic of callback is implemented inside the Pruner, users are just required to insert callback() between loss.backward() and optimizer.step(). Example:
def trainer(model, criterion, optimizer, epoch, callback): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") train_loader = ... model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # callback should be inserted between loss.backward() and optimizer.step() if callback: callback() optimizer.step()
- evaluator (function) –
function to evaluate the pruned model. This function should include model as the only parameter, and returns a scalar value. Example:
def evaluator(model): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") val_loader = ... model.eval() correct = 0 with torch.no_grad(): for data, target in val_loader: data, target = data.to(device), target.to(device) output = model(data) # get the index of the max log-probability pred = output.argmax(dim=1, keepdim=True) correct += pred.eq(target.view_as(pred)).sum().item() accuracy = correct / len(val_loader.dataset) return accuracy
- dummy_input (pytorch tensor) – The dummy input for
`jit.trace`, users should put it on right device before pass in. - num_iterations (int) – Number of overall iterations.
- optimize_mode (str) – optimize mode, maximize or minimize, by default maximize.
- base_algo (str) – Base pruning algorithm. level, l1 or l2, by default l1. Given the sparsity distribution among the ops, the assigned base_algo is used to decide which filters/channels/weights to prune.
- start_temperature (float) – Start temperature of the simulated annealing process.
- stop_temperature (float) – Stop temperature of the simulated annealing process.
- cool_down_rate (float) – Cool down rate of the temperature.
- perturbation_magnitude (float) – Initial perturbation magnitude to the sparsities. The magnitude decreases with current temperature.
- admm_num_iterations (int) – Number of iterations of ADMM Pruner.
- admm_training_epochs (int) – Training epochs of the first optimization subproblem of ADMMPruner.
- row (float) – Penalty parameters for ADMM training.
- experiment_data_dir (string) – PATH to store temporary experiment data.
AutoML for Model Compression Pruner¶
AutoML for Model Compression Pruner (AMCPruner) leverages reinforcement learning to provide the model compression policy. This learning-based compression policy outperforms conventional rule-based compression policy by having higher compression ratio, better preserving the accuracy and freeing human labor.
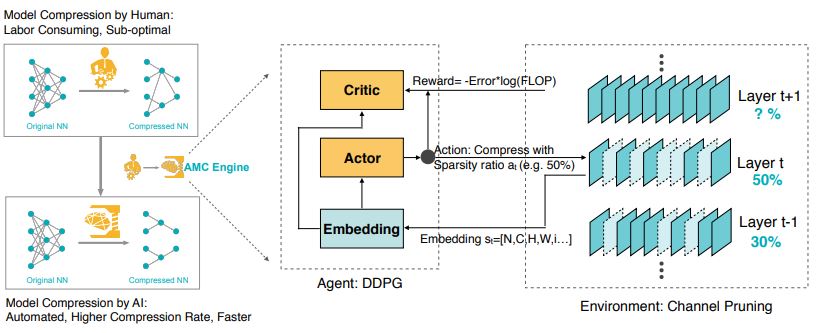
For more details, please refer to AMC: AutoML for Model Compression and Acceleration on Mobile Devices.
Usage¶
PyTorch code
from nni.compression.torch import AMCPruner
config_list = [{
'op_types': ['Conv2d', 'Linear']
}]
pruner = AMCPruner(model, config_list, evaluator, val_loader, flops_ratio=0.5)
pruner.compress()
You can view example for more information.
User configuration for AutoCompress Pruner¶
PyTorch¶
-
class
nni.compression.torch.AMCPruner(model, config_list, evaluator, val_loader, suffix=None, job='train_export', export_path=None, searched_model_path=None, model_type='mobilenet', dataset='cifar10', flops_ratio=0.5, lbound=0.2, rbound=1.0, reward='acc_reward', n_calibration_batches=60, n_points_per_layer=10, channel_round=8, hidden1=300, hidden2=300, lr_c=0.001, lr_a=0.0001, warmup=100, discount=1.0, bsize=64, rmsize=100, window_length=1, tau=0.01, init_delta=0.5, delta_decay=0.99, max_episode_length=1000000000.0, output_dir='./logs', debug=False, train_episode=800, epsilon=50000, seed=None)[source]¶ A pytorch implementation of AMC: AutoML for Model Compression and Acceleration on Mobile Devices. (https://arxiv.org/pdf/1802.03494.pdf)
Parameters: - model – nn.Module The model to be pruned.
- config_list – list Configuration list to configure layer pruning. Supported keys: - op_types: operation type to be pruned - op_names: operation name to be pruned
- evaluator – function function to evaluate the pruned model. The prototype of the function: >>> def evaluator(val_loader, model): >>> … >>> return acc
- val_loader – torch.utils.data.DataLoader Data loader of validation dataset.
- suffix – str suffix to help you remember what experiment you ran. Default: None.
- job – str train_export: search best pruned model and export after search. export_only: export a searched model, searched_model_path and export_path must be specified.
- searched_model_path – str when job == export_only, use searched_model_path to specify the path of the searched model.
- export_path – str path for exporting models
- parameters for pruning environment (#) –
- model_type – str model type to prune, currently ‘mobilenet’ and ‘mobilenetv2’ are supported. Default: mobilenet
- flops_ratio – float preserve flops ratio. Default: 0.5
- lbound – float minimum weight preserve ratio for each layer. Default: 0.2
- rbound – float maximum weight preserve ratio for each layer. Default: 1.0
- reward – function reward function type: - acc_reward: accuracy * 0.01 - acc_flops_reward: - (100 - accuracy) * 0.01 * np.log(flops) Default: acc_reward
- parameters for channel pruning (#) –
- n_calibration_batches – int number of batches to extract layer information. Default: 60
- n_points_per_layer – int number of feature points per layer. Default: 10
- channel_round – int round channel to multiple of channel_round. Default: 8
- parameters for ddpg agent (#) –
- hidden1 – int hidden num of first fully connect layer. Default: 300
- hidden2 – int hidden num of second fully connect layer. Default: 300
- lr_c – float learning rate for critic. Default: 1e-3
- lr_a – float learning rate for actor. Default: 1e-4
- warmup – int number of episodes without training but only filling the replay memory. During warmup episodes, random actions ares used for pruning. Default: 100
- discount – float next Q value discount for deep Q value target. Default: 0.99
- bsize – int minibatch size for training DDPG agent. Default: 64
- rmsize – int memory size for each layer. Default: 100
- window_length – int replay buffer window length. Default: 1
- tau – float moving average for target network being used by soft_update. Default: 0.99
- noise (#) –
- init_delta – float initial variance of truncated normal distribution
- delta_decay – float delta decay during exploration
- parameters for training ddpg agent (#) –
- max_episode_length – int maximum episode length
- output_dir – str output directory to save log files and model files. Default: ./logs
- debug – boolean debug mode
- train_episode – int train iters each timestep. Default: 800
- epsilon – int linear decay of exploration policy. Default: 50000
- seed – int random seed to set for reproduce experiment. Default: None
ADMM Pruner¶
Alternating Direction Method of Multipliers (ADMM) is a mathematical optimization technique, by decomposing the original nonconvex problem into two subproblems that can be solved iteratively. In weight pruning problem, these two subproblems are solved via 1) gradient descent algorithm and 2) Euclidean projection respectively.
During the process of solving these two subproblems, the weights of the original model will be changed. An one-shot pruner will then be applied to prune the model according to the config list given.
This solution framework applies both to non-structured and different variations of structured pruning schemes.
For more details, please refer to A Systematic DNN Weight Pruning Framework using Alternating Direction Method of Multipliers.
Usage¶
PyTorch code
from nni.compression.torch import ADMMPruner
config_list = [{
'sparsity': 0.8,
'op_types': ['Conv2d'],
'op_names': ['conv1']
}, {
'sparsity': 0.92,
'op_types': ['Conv2d'],
'op_names': ['conv2']
}]
pruner = ADMMPruner(model, config_list, trainer=trainer, num_iterations=30, epochs=5)
pruner.compress()
You can view example for more information.
User configuration for ADMM Pruner¶
PyTorch¶
-
class
nni.compression.torch.ADMMPruner(model, config_list, trainer, num_iterations=30, training_epochs=5, row=0.0001, base_algo='l1')[source]¶ A Pytorch implementation of ADMM Pruner algorithm.
Parameters: - model (torch.nn.Module) – Model to be pruned.
- config_list (list) – List on pruning configs.
- trainer (function) –
Function used for the first subproblem. Users should write this function as a normal function to train the Pytorch model and include model, optimizer, criterion, epoch, callback as function arguments. Here callback acts as an L2 regulizer as presented in the formula (7) of the original paper. The logic of callback is implemented inside the Pruner, users are just required to insert callback() between loss.backward() and optimizer.step(). Example:
def trainer(model, criterion, optimizer, epoch, callback): device = torch.device("cuda" if torch.cuda.is_available() else "cpu") train_loader = ... model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = criterion(output, target) loss.backward() # callback should be inserted between loss.backward() and optimizer.step() if callback: callback() optimizer.step()
- num_iterations (int) – Total number of iterations.
- training_epochs (int) – Training epochs of the first subproblem.
- row (float) – Penalty parameters for ADMM training.
- base_algo (str) – Base pruning algorithm. level, l1 or l2, by default l1. Given the sparsity distribution among the ops, the assigned base_algo is used to decide which filters/channels/weights to prune.
Lottery Ticket Hypothesis¶
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, authors Jonathan Frankle and Michael Carbin,provides comprehensive measurement and analysis, and articulate the lottery ticket hypothesis: dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that – when trained in isolation – reach test accuracy comparable to the original network in a similar number of iterations.
In this paper, the authors use the following process to prune a model, called iterative prunning:
- Randomly initialize a neural network f(x;theta_0) (where theta_0 follows D_{theta}).
- Train the network for j iterations, arriving at parameters theta_j.
- Prune p% of the parameters in theta_j, creating a mask m.
- Reset the remaining parameters to their values in theta_0, creating the winning ticket f(x;m*theta_0).
- Repeat step 2, 3, and 4.
If the configured final sparsity is P (e.g., 0.8) and there are n times iterative pruning, each iterative pruning prunes 1-(1-P)^(1/n) of the weights that survive the previous round.
Usage¶
PyTorch code
from nni.compression.torch import LotteryTicketPruner
config_list = [{
'prune_iterations': 5,
'sparsity': 0.8,
'op_types': ['default']
}]
pruner = LotteryTicketPruner(model, config_list, optimizer)
pruner.compress()
for _ in pruner.get_prune_iterations():
pruner.prune_iteration_start()
for epoch in range(epoch_num):
...
The above configuration means that there are 5 times of iterative pruning. As the 5 times iterative pruning are executed in the same run, LotteryTicketPruner needs model and optimizer (Note that should add lr_scheduler if used) to reset their states every time a new prune iteration starts. Please use get_prune_iterations to get the pruning iterations, and invoke prune_iteration_start at the beginning of each iteration. epoch_num is better to be large enough for model convergence, because the hypothesis is that the performance (accuracy) got in latter rounds with high sparsity could be comparable with that got in the first round.
Tensorflow version will be supported later.
User configuration for LotteryTicket Pruner¶
PyTorch¶
-
class
nni.compression.torch.LotteryTicketPruner(model, config_list, optimizer=None, lr_scheduler=None, reset_weights=True)[source]¶ Parameters: - model (pytorch model) – The model to be pruned
- config_list (list) –
- Supported keys:
- prune_iterations : The number of rounds for the iterative pruning.
- sparsity : The final sparsity when the compression is done.
- optimizer (pytorch optimizer) – The optimizer for the model
- lr_scheduler (pytorch lr scheduler) – The lr scheduler for the model if used
- reset_weights (bool) – Whether reset weights and optimizer at the beginning of each round.
Reproduced Experiment¶
We try to reproduce the experiment result of the fully connected network on MNIST using the same configuration as in the paper. The code can be referred here. In this experiment, we prune 10 times, for each pruning we train the pruned model for 50 epochs.
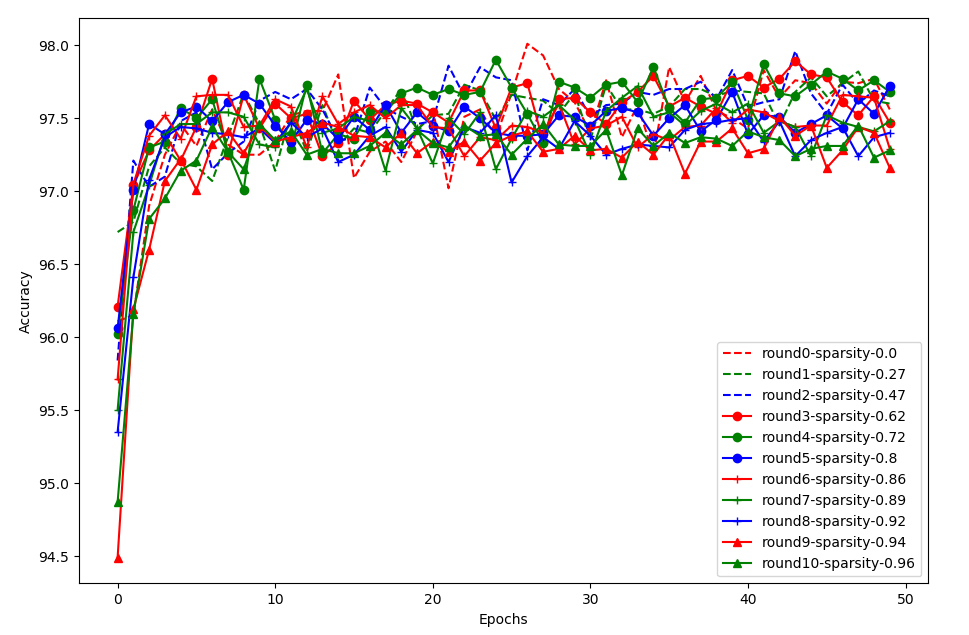
The above figure shows the result of the fully connected network. round0-sparsity-0.0 is the performance without pruning. Consistent with the paper, pruning around 80% also obtain similar performance compared to non-pruning, and converges a little faster. If pruning too much, e.g., larger than 94%, the accuracy becomes lower and convergence becomes a little slower. A little different from the paper, the trend of the data in the paper is relatively more clear.
Sensitivity Pruner¶
For each round, SensitivityPruner prunes the model based on the sensitivity to the accuracy of each layer until meeting the final configured sparsity of the whole model: 1. Analyze the sensitivity of each layer in the current state of the model. 2. Prune each layer according to the sensitivity.
For more details, please refer to Learning both Weights and Connections for Efficient Neural Networks .
Usage¶
PyTorch code
from nni.compression.torch import SensitivityPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = SensitivityPruner(model, config_list, finetuner=fine_tuner, evaluator=evaluator)
# eval_args and finetune_args are the parameters passed to the evaluator and finetuner respectively
pruner.compress(eval_args=[model], finetune_args=[model])
User configuration for Sensitivity Pruner¶
PyTorch¶
-
class
nni.compression.torch.SensitivityPruner(model, config_list, evaluator, finetuner=None, base_algo='l1', sparsity_proportion_calc=None, sparsity_per_iter=0.1, acc_drop_threshold=0.05, checkpoint_dir=None)[source]¶ This function prune the model based on the sensitivity for each layer.
Parameters: - model (torch.nn.Module) – model to be compressed
- evaluator (function) – validation function for the model. This function should return the accuracy of the validation dataset. The input parameters of evaluator can be specified in the parameter eval_args and ‘eval_kwargs’ of the compress function if needed. Example: >>> def evaluator(model): >>> device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”) >>> val_loader = … >>> model.eval() >>> correct = 0 >>> with torch.no_grad(): >>> for data, target in val_loader: >>> data, target = data.to(device), target.to(device) >>> output = model(data) >>> # get the index of the max log-probability >>> pred = output.argmax(dim=1, keepdim=True) >>> correct += pred.eq(target.view_as(pred)).sum().item() >>> accuracy = correct / len(val_loader.dataset) >>> return accuracy
- finetuner (function) – finetune function for the model. This parameter is not essential, if is not None, the sensitivity pruner will finetune the model after pruning in each iteration. The input parameters of finetuner can be specified in the parameter of compress called finetune_args and finetune_kwargs if needed. Example: >>> def finetuner(model, epoch=3): >>> device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”) >>> train_loader = … >>> criterion = torch.nn.CrossEntropyLoss() >>> optimizer = torch.optim.SGD(model.parameters(), lr=0.01) >>> model.train() >>> for _ in range(epoch): >>> for _, (data, target) in enumerate(train_loader): >>> data, target = data.to(device), target.to(device) >>> optimizer.zero_grad() >>> output = model(data) >>> loss = criterion(output, target) >>> loss.backward() >>> optimizer.step()
- base_algo (str) – base pruning algorithm. level, l1 or l2, by default l1.
- sparsity_proportion_calc (function) – This function generate the sparsity proportion between the conv layers according to the sensitivity analysis results. We provide a default function to quantify the sparsity proportion according to the sensitivity analysis results. Users can also customize this function according to their needs. The input of this function is a dict, for example : {‘conv1’ : {0.1: 0.9, 0.2 : 0.8}, ‘conv2’ : {0.1: 0.9, 0.2 : 0.8}}, in which, ‘conv1’ and is the name of the conv layer, and 0.1:0.9 means when the sparsity of conv1 is 0.1 (10%), the model’s val accuracy equals to 0.9.
- sparsity_per_iter (float) – The sparsity of the model that the pruner try to prune in each iteration.
- acc_drop_threshold (float) – The hyperparameter used to quantifiy the sensitivity for each layer.
- checkpoint_dir (str) – The dir path to save the checkpoints during the pruning.