Neural Network Intelligence¶
Overview¶
NNI (Neural Network Intelligence) is a toolkit to help users design and tune machine learning models (e.g., hyperparameters), neural network architectures, or complex system’s parameters, in an efficient and automatic way. NNI has several appealing properties: ease-of-use, scalability, flexibility, and efficiency.
- Ease-of-use: NNI can be easily installed through python pip. Only several lines need to be added to your code in order to use NNI’s power. You can use both the commandline tool and WebUI to work with your experiments.
- Scalability: Tuning hyperparameters or the neural architecture often demands a large number of computational resources, while NNI is designed to fully leverage different computation resources, such as remote machines, training platforms (e.g., OpenPAI, Kubernetes). Hundreds of trials could run in parallel by depending on the capacity of your configured training platforms.
- Flexibility: Besides rich built-in algorithms, NNI allows users to customize various hyperparameter tuning algorithms, neural architecture search algorithms, early stopping algorithms, etc. Users can also extend NNI with more training platforms, such as virtual machines, kubernetes service on the cloud. Moreover, NNI can connect to external environments to tune special applications/models on them.
- Efficiency: We are intensively working on more efficient model tuning on both the system and algorithm level. For example, we leverage early feedback to speedup the tuning procedure.
The figure below shows high-level architecture of NNI.

Key Concepts¶
- Experiment: One task of, for example, finding out the best hyperparameters of a model, finding out the best neural network architecture, etc. It consists of trials and AutoML algorithms.
- Search Space: The feasible region for tuning the model. For example, the value range of each hyperparameter.
- Configuration: An instance from the search space, that is, each hyperparameter has a specific value.
- Trial: An individual attempt at applying a new configuration (e.g., a set of hyperparameter values, a specific neural architecture, etc.). Trial code should be able to run with the provided configuration.
- Tuner: An AutoML algorithm, which generates a new configuration for the next try. A new trial will run with this configuration.
- Assessor: Analyze a trial’s intermediate results (e.g., periodically evaluated accuracy on test dataset) to tell whether this trial can be early stopped or not.
- Training Platform: Where trials are executed. Depending on your experiment’s configuration, it could be your local machine, or remote servers, or large-scale training platform (e.g., OpenPAI, Kubernetes).
Basically, an experiment runs as follows: Tuner receives search space and generates configurations. These configurations will be submitted to training platforms, such as the local machine, remote machines, or training clusters. Their performances are reported back to Tuner. Then, new configurations are generated and submitted.
For each experiment, the user only needs to define a search space and update a few lines of code, and then leverage NNI built-in Tuner/Assessor and training platforms to search the best hyperparameters and/or neural architecture. There are basically 3 steps:
Step 1: Define search space
Step 2: Update model codes
Step 3: Define Experiment

For more details about how to run an experiment, please refer to Get Started.
Core Features¶
NNI provides a key capacity to run multiple instances in parallel to find the best combinations of parameters. This feature can be used in various domains, like finding the best hyperparameters for a deep learning model or finding the best configuration for database and other complex systems with real data.
NNI also provides algorithm toolkits for machine learning and deep learning, especially neural architecture search (NAS) algorithms, model compression algorithms, and feature engineering algorithms.
Hyperparameter Tuning¶
This is a core and basic feature of NNI, we provide many popular automatic tuning algorithms (i.e., tuner) and early stop algorithms (i.e., assessor). You can follow Quick Start to tune your model (or system). Basically, there are the above three steps and then starting an NNI experiment.
General NAS Framework¶
This NAS framework is for users to easily specify candidate neural architectures, for example, one can specify multiple candidate operations (e.g., separable conv, dilated conv) for a single layer, and specify possible skip connections. NNI will find the best candidate automatically. On the other hand, the NAS framework provides a simple interface for another type of user (e.g., NAS algorithm researchers) to implement new NAS algorithms. A detailed description of NAS and its usage can be found here.
NNI has support for many one-shot NAS algorithms such as ENAS and DARTS through NNI trial SDK. To use these algorithms you do not have to start an NNI experiment. Instead, import an algorithm in your trial code and simply run your trial code. If you want to tune the hyperparameters in the algorithms or want to run multiple instances, you can choose a tuner and start an NNI experiment.
Other than one-shot NAS, NAS can also run in a classic mode where each candidate architecture runs as an independent trial job. In this mode, similar to hyperparameter tuning, users have to start an NNI experiment and choose a tuner for NAS.
Model Compression¶
Model Compression on NNI includes pruning algorithms and quantization algorithms. These algorithms are provided through NNI trial SDK. Users can directly use them in their trial code and run the trial code without starting an NNI experiment. A detailed description of model compression and its usage can be found here.
There are different types of hyperparameters in model compression. One type is the hyperparameters in input configuration (e.g., sparsity, quantization bits) to a compression algorithm. The other type is the hyperparameters in compression algorithms. Here, Hyperparameter tuning of NNI can help a lot in finding the best compressed model automatically. A simple example can be found here.
Automatic Feature Engineering¶
Automatic feature engineering is for users to find the best features for their tasks. A detailed description of automatic feature engineering and its usage can be found here. It is supported through NNI trial SDK, which means you do not have to create an NNI experiment. Instead, simply import a built-in auto-feature-engineering algorithm in your trial code and directly run your trial code.
The auto-feature-engineering algorithms usually have a bunch of hyperparameters themselves. If you want to automatically tune those hyperparameters, you can leverage hyperparameter tuning of NNI, that is, choose a tuning algorithm (i.e., tuner) and start an NNI experiment for it.
Learn More¶
- Get started
- How to adapt your trial code on NNI?
- What are tuners supported by NNI?
- How to customize your own tuner?
- What are assessors supported by NNI?
- How to customize your own assessor?
- How to run an experiment on local?
- How to run an experiment on multiple machines?
- How to run an experiment on OpenPAI?
- Examples
- Neural Architecture Search on NNI
- Automatic model compression on NNI
- Automatic feature engineering on NNI
Installation¶
Currently we support installation on Linux, Mac and Windows. We also allow you to use docker.
Install on Linux & Mac¶
Installation¶
Installation on Linux and macOS follow the same instructions, given below.
Install NNI through source code¶
If you are interested in special or the latest code versions, you can install NNI through source code.
Prerequisites: python 64-bit >=3.5, git, wget
git clone -b v1.6 https://github.com/Microsoft/nni.git
cd nni
./install.sh
Verify installation¶
The following example is built on TensorFlow 1.x. Make sure TensorFlow 1.x is used when running it.
Download the examples via cloning the source code.
git clone -b v1.6 https://github.com/Microsoft/nni.git
Run the MNIST example.
nnictl create --config nni/examples/trials/mnist-tfv1/config.yml
Wait for the message
INFO: Successfully started experiment!in the command line. This message indicates that your experiment has been successfully started. You can explore the experiment using theWeb UI url.
INFO: Starting restful server...
INFO: Successfully started Restful server!
INFO: Setting local config...
INFO: Successfully set local config!
INFO: Starting experiment...
INFO: Successfully started experiment!
-----------------------------------------------------------------------
The experiment id is egchD4qy
The Web UI urls are: http://223.255.255.1:8080 http://127.0.0.1:8080
-----------------------------------------------------------------------
You can use these commands to get more information about the experiment
-----------------------------------------------------------------------
commands description
1. nnictl experiment show show the information of experiments
2. nnictl trial ls list all of trial jobs
3. nnictl top monitor the status of running experiments
4. nnictl log stderr show stderr log content
5. nnictl log stdout show stdout log content
6. nnictl stop stop an experiment
7. nnictl trial kill kill a trial job by id
8. nnictl --help get help information about nnictl
-----------------------------------------------------------------------
- Open the
Web UI urlin your browser, you can view detailed information about the experiment and all the submitted trial jobs as shown below. Here are more Web UI pages.
 overview
overview
 detail
detail
System requirements¶
Due to potential programming changes, the minimum system requirements of NNI may change over time.
Linux¶
| Recommended | Minimum | |
|---|---|---|
| Operating System | Ubuntu 16.04 or above | |
| CPU | Intel® Core™ i5 or AMD Phenom™ II X3 or better | Intel® Core™ i3 or AMD Phenom™ X3 8650 |
| GPU | NVIDIA® GeForce® GTX 660 or better | NVIDIA® GeForce® GTX 460 |
| Memory | 6 GB RAM | 4 GB RAM |
| Storage | 30 GB available hare drive space | |
| Internet | Boardband internet connection | |
| Resolution | 1024 x 768 minimum display resolution |
macOS¶
| Recommended | Minimum | |
|---|---|---|
| Operating System | macOS 10.14.1 or above | |
| CPU | Intel® Core™ i7-4770 or better | Intel® Core™ i5-760 or better |
| GPU | AMD Radeon™ R9 M395X or better | NVIDIA® GeForce® GT 750M or AMD Radeon™ R9 M290 or better |
| Memory | 8 GB RAM | 4 GB RAM |
| Storage | 70GB available space SSD | 70GB available space 7200 RPM HDD |
| Internet | Boardband internet connection | |
| Resolution | 1024 x 768 minimum display resolution |
Further reading¶
- Overview
- Use command line tool nnictl
- Use NNIBoard
- Define search space
- Config an experiment
- How to run an experiment on local (with multiple GPUs)?
- How to run an experiment on multiple machines?
- How to run an experiment on OpenPAI?
- How to run an experiment on Kubernetes through Kubeflow?
- How to run an experiment on Kubernetes through FrameworkController?
Install on Windows¶
Prerequires¶
Python 3.5 (or above) 64-bit. Anaconda or Miniconda is highly recommended to manage multiple Python environments on Windows.
If it’s a newly installed Python environment, it needs to install Microsoft C++ Build Tools to support build NNI dependencies like
scikit-learn.pip install cython wheel
git for verifying installation.
Install NNI¶
In most cases, you can install and upgrade NNI from pip package. It’s easy and fast.
If you are interested in special or the latest code versions, you can install NNI through source code.
If you want to contribute to NNI, refer to setup development environment.
From pip package
python -m pip install --upgrade nni
From source code
git clone -b v1.6 https://github.com/Microsoft/nni.git cd nni powershell -ExecutionPolicy Bypass -file install.ps1
Verify installation¶
The following example is built on TensorFlow 1.x. Make sure TensorFlow 1.x is used when running it.
Clone examples within source code.
git clone -b v1.6 https://github.com/Microsoft/nni.git
Run the MNIST example.
nnictl create --config nni\examples\trials\mnist-tfv1\config_windows.yml
Note: If you are familiar with other frameworks, you can choose corresponding example under
examples\trials. It needs to change trial commandpython3topythonin each example YAML, since default installation haspython.exe, notpython3.exeexecutable.Wait for the message
INFO: Successfully started experiment!in the command line. This message indicates that your experiment has been successfully started. You can explore the experiment using theWeb UI url.
INFO: Starting restful server...
INFO: Successfully started Restful server!
INFO: Setting local config...
INFO: Successfully set local config!
INFO: Starting experiment...
INFO: Successfully started experiment!
-----------------------------------------------------------------------
The experiment id is egchD4qy
The Web UI urls are: http://223.255.255.1:8080 http://127.0.0.1:8080
-----------------------------------------------------------------------
You can use these commands to get more information about the experiment
-----------------------------------------------------------------------
commands description
1. nnictl experiment show show the information of experiments
2. nnictl trial ls list all of trial jobs
3. nnictl top monitor the status of running experiments
4. nnictl log stderr show stderr log content
5. nnictl log stdout show stdout log content
6. nnictl stop stop an experiment
7. nnictl trial kill kill a trial job by id
8. nnictl --help get help information about nnictl
-----------------------------------------------------------------------
- Open the
Web UI urlin your browser, you can view detailed information about the experiment and all the submitted trial jobs as shown below. Here are more Web UI pages.
overview
detail
System requirements¶
Below are the minimum system requirements for NNI on Windows, Windows 10.1809 is well tested and recommend. Due to potential programming changes, the minimum system requirements for NNI may change over time.
| Recommended | Minimum | |
|---|---|---|
| Operating System | Windows 10 1809 or above | |
| CPU | Intel® Core™ i5 or AMD Phenom™ II X3 or better | Intel® Core™ i3 or AMD Phenom™ X3 8650 |
| GPU | NVIDIA® GeForce® GTX 660 or better | NVIDIA® GeForce® GTX 460 |
| Memory | 6 GB RAM | 4 GB RAM |
| Storage | 30 GB available hare drive space | |
| Internet | Boardband internet connection | |
| Resolution | 1024 x 768 minimum display resolution |
FAQ¶
simplejson failed when installing NNI¶
Make sure a C++ 14.0 compiler is installed.
building ‘simplejson._speedups’ extension error: [WinError 3] The system cannot find the path specified
Trial failed with missing DLL in command line or PowerShell¶
This error is caused by missing LIBIFCOREMD.DLL and LIBMMD.DLL and failure to install SciPy. Using Anaconda or Miniconda with Python(64-bit) can solve it.
ImportError: DLL load failed
Trial failed on webUI¶
Please check the trial log file stderr for more details.
If there is a stderr file, please check it. Two possible cases are:
- forgetting to change the trial command
python3topythonin each experiment YAML. - forgetting to install experiment dependencies such as TensorFlow, Keras and so on.
Fail to use BOHB on Windows¶
Make sure a C++ 14.0 compiler is installed when trying to run nnictl package install --name=BOHB to install the dependencies.
Not supported tuner on Windows¶
SMAC is not supported currently; for the specific reason refer to this GitHub issue.
Use Windows as a remote worker¶
Refer to Remote Machine mode.
Further reading¶
- Overview
- Use command line tool nnictl
- Use NNIBoard
- Define search space
- Config an experiment
- How to run an experiment on local (with multiple GPUs)?
- How to run an experiment on multiple machines?
- How to run an experiment on OpenPAI?
- How to run an experiment on Kubernetes through Kubeflow?
- How to run an experiment on Kubernetes through FrameworkController?
How to Use Docker in NNI¶
Overview¶
Docker is a tool to make it easier for users to deploy and run applications based on their own operating system by starting containers. Docker is not a virtual machine, it does not create a virtual operating system, but it allows different applications to use the same OS kernel and isolate different applications by container.
Users can start NNI experiments using Docker. NNI also provides an official Docker image msranni/nni on Docker Hub.
Using Docker in local machine¶
Step 1: Installation of Docker¶
Before you start using Docker for NNI experiments, you should install Docker on your local machine. See here.
Step 2: Start a Docker container¶
If you have installed the Docker package in your local machine, you can start a Docker container instance to run NNI examples. You should notice that because NNI will start a web UI process in a container and continue to listen to a port, you need to specify the port mapping between your host machine and Docker container to give access to web UI outside the container. By visiting the host IP address and port, you can redirect to the web UI process started in Docker container and visit web UI content.
For example, you could start a new Docker container from the following command:
docker run -i -t -p [hostPort]:[containerPort] [image]
-i: Start a Docker in an interactive mode.
-t: Docker assign the container an input terminal.
-p: Port mapping, map host port to a container port.
For more information about Docker commands, please refer to this.
Note:
NNI only supports Ubuntu and MacOS systems in local mode for the moment, please use correct Docker image type. If you want to use gpu in a Docker container, please use nvidia-docker.
Step 3: Run NNI in a Docker container¶
If you start a Docker image using NNI’s official image msranni/nni, you can directly start NNI experiments by using the nnictl command. Our official image has NNI’s running environment and basic python and deep learning frameworks preinstalled.
If you start your own Docker image, you may need to install the NNI package first; please refer to NNI installation.
If you want to run NNI’s official examples, you may need to clone the NNI repo in GitHub using
git clone https://github.com/Microsoft/nni.git
then you can enter nni/examples/trials to start an experiment.
After you prepare NNI’s environment, you can start a new experiment using the nnictl command. See here.
Using Docker on a remote platform¶
NNI supports starting experiments in remoteTrainingService, and running trial jobs on remote machines. As Docker can start an independent Ubuntu system as an SSH server, a Docker container can be used as the remote machine in NNI’s remote mode.
Step 1: Setting a Docker environment¶
You should install the Docker software on your remote machine first, please refer to this.
To make sure your Docker container can be connected by NNI experiments, you should build your own Docker image to set an SSH server or use images with an SSH configuration. If you want to use a Docker container as an SSH server, you should configure the SSH password login or private key login; please refer to this.
Note:
NNI's official image msranni/nni does not support SSH servers for the time being; you should build your own Docker image with an SSH configuration or use other images as a remote server.
Step 2: Start a Docker container on a remote machine¶
An SSH server needs a port; you need to expose Docker’s SSH port to NNI as the connection port. For example, if you set your container’s SSH port as A, you should map the container’s port A to your remote host machine’s other port B, NNI will connect port B as an SSH port, and your host machine will map the connection from port B to port A then NNI could connect to your Docker container.
For example, you could start your Docker container using the following commands:
docker run -dit -p [hostPort]:[containerPort] [image]
The containerPort is the SSH port used in your Docker container and the hostPort is your host machine’s port exposed to NNI. You can set your NNI’s config file to connect to hostPort and the connection will be transmitted to your Docker container.
For more information about Docker commands, please refer to this.
Note:
If you use your own Docker image as a remote server, please make sure that this image has a basic python environment and an NNI SDK runtime environment. If you want to use a GPU in a Docker container, please use nvidia-docker.
Step 3: Run NNI experiments¶
You can set your config file as a remote platform and set the machineList configuration to connect to your Docker SSH server; refer to this. Note that you should set the correct port, username, and passWd or sshKeyPath of your host machine.
port: The host machine’s port, mapping to Docker’s SSH port.
username: The username of the Docker container.
passWd: The password of the Docker container.
sshKeyPath: The path of the private key of the Docker container.
After the configuration of the config file, you could start an experiment, refer to this.
QuickStart¶
Installation¶
We currently support Linux, macOS, and Windows. Ubuntu 16.04 or higher, macOS 10.14.1, and Windows 10.1809 are tested and supported. Simply run the following pip install in an environment that has python >= 3.5.
Linux and macOS¶
python3 -m pip install --upgrade nni
Windows¶
python -m pip install --upgrade nni
Note
For Linux and macOS, --user can be added if you want to install NNI in your home directory; this does not require any special privileges.
Note
If there is an error like Segmentation fault, please refer to the FAQ.
Note
For the system requirements of NNI, please refer to Install NNI on Linux & Mac or Windows.
“Hello World” example on MNIST¶
NNI is a toolkit to help users run automated machine learning experiments. It can automatically do the cyclic process of getting hyperparameters, running trials, testing results, and tuning hyperparameters. Here, we’ll show how to use NNI to help you find the optimal hyperparameters for a MNIST model.
Here is an example script to train a CNN on the MNIST dataset without NNI:
def run_trial(params):
# Input data
mnist = input_data.read_data_sets(params['data_dir'], one_hot=True)
# Build network
mnist_network = MnistNetwork(channel_1_num=params['channel_1_num'],
channel_2_num=params['channel_2_num'],
conv_size=params['conv_size'],
hidden_size=params['hidden_size'],
pool_size=params['pool_size'],
learning_rate=params['learning_rate'])
mnist_network.build_network()
test_acc = 0.0
with tf.Session() as sess:
# Train network
mnist_network.train(sess, mnist)
# Evaluate network
test_acc = mnist_network.evaluate(mnist)
if __name__ == '__main__':
params = {'data_dir': '/tmp/tensorflow/mnist/input_data',
'dropout_rate': 0.5,
'channel_1_num': 32,
'channel_2_num': 64,
'conv_size': 5,
'pool_size': 2,
'hidden_size': 1024,
'learning_rate': 1e-4,
'batch_num': 2000,
'batch_size': 32}
run_trial(params)
If you want to see the full implementation, please refer to examples/trials/mnist-tfv1/mnist_before.py.
The above code can only try one set of parameters at a time; if we want to tune learning rate, we need to manually modify the hyperparameter and start the trial again and again.
NNI is born to help the user do tuning jobs; the NNI working process is presented below:
input: search space, trial code, config file
output: one optimal hyperparameter configuration
1: For t = 0, 1, 2, ..., maxTrialNum,
2: hyperparameter = chose a set of parameter from search space
3: final result = run_trial_and_evaluate(hyperparameter)
4: report final result to NNI
5: If reach the upper limit time,
6: Stop the experiment
7: return hyperparameter value with best final result
If you want to use NNI to automatically train your model and find the optimal hyper-parameters, you need to do three changes based on your code:
Three steps to start an experiment¶
Step 1: Write a Search Space file in JSON, including the name and the distribution (discrete-valued or continuous-valued) of all the hyperparameters you need to search.
- params = {'data_dir': '/tmp/tensorflow/mnist/input_data', 'dropout_rate': 0.5, 'channel_1_num': 32, 'channel_2_num': 64,
- 'conv_size': 5, 'pool_size': 2, 'hidden_size': 1024, 'learning_rate': 1e-4, 'batch_num': 2000, 'batch_size': 32}
+ {
+ "dropout_rate":{"_type":"uniform","_value":[0.5, 0.9]},
+ "conv_size":{"_type":"choice","_value":[2,3,5,7]},
+ "hidden_size":{"_type":"choice","_value":[124, 512, 1024]},
+ "batch_size": {"_type":"choice", "_value": [1, 4, 8, 16, 32]},
+ "learning_rate":{"_type":"choice","_value":[0.0001, 0.001, 0.01, 0.1]}
+ }
Example: search_space.json
Step 2: Modify your Trial file to get the hyperparameter set from NNI and report the final result to NNI.
+ import nni
def run_trial(params):
mnist = input_data.read_data_sets(params['data_dir'], one_hot=True)
mnist_network = MnistNetwork(channel_1_num=params['channel_1_num'], channel_2_num=params['channel_2_num'], conv_size=params['conv_size'], hidden_size=params['hidden_size'], pool_size=params['pool_size'], learning_rate=params['learning_rate'])
mnist_network.build_network()
with tf.Session() as sess:
mnist_network.train(sess, mnist)
test_acc = mnist_network.evaluate(mnist)
+ nni.report_final_result(test_acc)
if __name__ == '__main__':
- params = {'data_dir': '/tmp/tensorflow/mnist/input_data', 'dropout_rate': 0.5, 'channel_1_num': 32, 'channel_2_num': 64,
- 'conv_size': 5, 'pool_size': 2, 'hidden_size': 1024, 'learning_rate': 1e-4, 'batch_num': 2000, 'batch_size': 32}
+ params = nni.get_next_parameter()
run_trial(params)
Example: mnist.py
Step 3: Define a config file in YAML which declares the path to the search space and trial files. It also gives other information such as the tuning algorithm, max trial number, and max duration arguments.
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
trainingServicePlatform: local
# The path to Search Space
searchSpacePath: search_space.json
useAnnotation: false
tuner:
builtinTunerName: TPE
# The path and the running command of trial
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 0
Note
If you are planning to use remote machines or clusters as your training service, to avoid too much pressure on network, we limit the number of files to 2000 and total size to 300MB. If your codeDir contains too many files, you can choose which files and subfolders should be excluded by adding a .nniignore file that works like a .gitignore file. For more details on how to write this file, see the git documentation.
Example: config.yml .nniignore
All the code above is already prepared and stored in examples/trials/mnist-tfv1/.
Linux and macOS¶
Run the config.yml file from your command line to start an MNIST experiment.
nnictl create --config nni/examples/trials/mnist-tfv1/config.yml
Windows¶
Run the config_windows.yml file from your command line to start an MNIST experiment.
nnictl create --config nni\examples\trials\mnist-tfv1\config_windows.yml
Note
If you’re using NNI on Windows, you probably need to change python3 to python in the config.yml file or use the config_windows.yml file to start the experiment.
Note
nnictl is a command line tool that can be used to control experiments, such as start/stop/resume an experiment, start/stop NNIBoard, etc. Click here for more usage of nnictl.
Wait for the message INFO: Successfully started experiment! in the command line. This message indicates that your experiment has been successfully started. And this is what we expect to get:
INFO: Starting restful server...
INFO: Successfully started Restful server!
INFO: Setting local config...
INFO: Successfully set local config!
INFO: Starting experiment...
INFO: Successfully started experiment!
-----------------------------------------------------------------------
The experiment id is egchD4qy
The Web UI urls are: [Your IP]:8080
-----------------------------------------------------------------------
You can use these commands to get more information about the experiment
-----------------------------------------------------------------------
commands description
1. nnictl experiment show show the information of experiments
2. nnictl trial ls list all of trial jobs
3. nnictl top monitor the status of running experiments
4. nnictl log stderr show stderr log content
5. nnictl log stdout show stdout log content
6. nnictl stop stop an experiment
7. nnictl trial kill kill a trial job by id
8. nnictl --help get help information about nnictl
-----------------------------------------------------------------------
If you prepared trial, search space, and config according to the above steps and successfully created an NNI job, NNI will automatically tune the optimal hyper-parameters and run different hyper-parameter sets for each trial according to the requirements you set. You can clearly see its progress through the NNI WebUI.
WebUI¶
After you start your experiment in NNI successfully, you can find a message in the command-line interface that tells you the Web UI url like this:
The Web UI urls are: [Your IP]:8080
Open the Web UI url (Here it’s: [Your IP]:8080) in your browser; you can view detailed information about the experiment and all the submitted trial jobs as shown below. If you cannot open the WebUI link in your terminal, please refer to the FAQ.
View summary page¶
Click the “Overview” tab.
Information about this experiment will be shown in the WebUI, including the experiment trial profile and search space message. NNI also supports downloading this information and the parameters through the Download button. You can download the experiment results anytime while the experiment is running, or you can wait until the end of the execution, etc.

The top 10 trials will be listed on the Overview page. You can browse all the trials on the “Trials Detail” page.

View trials detail page¶
Click the “Default Metric” tab to see the point graph of all trials. Hover to see specific default metrics and search space messages.

Click the “Hyper Parameter” tab to see the parallel graph.
- You can select the percentage to see the top trials.
- Choose two axis to swap their positions.

Click the “Trial Duration” tab to see the bar graph.

Below is the status of all trials. Specifically:
- Trial detail: trial’s id, duration, start time, end time, status, accuracy, and search space file.
- If you run on the OpenPAI platform, you can also see the hdfsLogPath.
- Kill: you can kill a job that has the
Runningstatus. - Support: Used to search for a specific trial.

- Intermediate Result Graph

Auto (Hyper-parameter) Tuning¶
Auto tuning is one of the key features provided by NNI; a main application scenario being hyper-parameter tuning. Tuning specifically applies to trial code. We provide a lot of popular auto tuning algorithms (called Tuner), and some early stop algorithms (called Assessor). NNI supports running trials on various training platforms, for example, on a local machine, on several servers in a distributed manner, or on platforms such as OpenPAI, Kubernetes, etc.
Other key features of NNI, such as model compression, feature engineering, can also be further enhanced by auto tuning, which we’ll described when introducing those features.
NNI has high extensibility, advanced users can customize their own Tuner, Assessor, and Training Service according to their needs.
Write a Trial Run on NNI¶
A Trial in NNI is an individual attempt at applying a configuration (e.g., a set of hyper-parameters) to a model.
To define an NNI trial, you need to first define the set of parameters (i.e., search space) and then update the model. NNI provides two approaches for you to define a trial: NNI API and NNI Python annotation. You could also refer to here for more trial examples.
NNI API¶
Step 1 - Prepare a SearchSpace parameters file.¶
An example is shown below:
{
"dropout_rate":{"_type":"uniform","_value":[0.1,0.5]},
"conv_size":{"_type":"choice","_value":[2,3,5,7]},
"hidden_size":{"_type":"choice","_value":[124, 512, 1024]},
"learning_rate":{"_type":"uniform","_value":[0.0001, 0.1]}
}
Refer to SearchSpaceSpec.md to learn more about search spaces. Tuner will generate configurations from this search space, that is, choosing a value for each hyperparameter from the range.
Step 2 - Update model code¶
Import NNI
Include
import nniin your trial code to use NNI APIs.Get configuration from Tuner
RECEIVED_PARAMS = nni.get_next_parameter()
RECEIVED_PARAMS is an object, for example:
{"conv_size": 2, "hidden_size": 124, "learning_rate": 0.0307, "dropout_rate": 0.2029}.
- Report metric data periodically (optional)
nni.report_intermediate_result(metrics)
metrics can be any python object. If users use the NNI built-in tuner/assessor, metrics can only have two formats: 1) a number e.g., float, int, or 2) a dict object that has a key named default whose value is a number. These metrics are reported to assessor. Often, metrics includes the periodically evaluated loss or accuracy.
- Report performance of the configuration
nni.report_final_result(metrics)
metrics can also be any python object. If users use the NNI built-in tuner/assessor, metrics follows the same format rule as that in report_intermediate_result, the number indicates the model’s performance, for example, the model’s accuracy, loss etc. These metrics are reported to tuner.
Step 3 - Enable NNI API¶
To enable NNI API mode, you need to set useAnnotation to false and provide the path of the SearchSpace file was defined in step 1:
useAnnotation: false
searchSpacePath: /path/to/your/search_space.json
You can refer to here for more information about how to set up experiment configurations.
*Please refer to here for more APIs (e.g., nni.get_sequence_id()) provided by NNI.
NNI Python Annotation¶
An alternative to writing a trial is to use NNI’s syntax for python. NNI annotations are simple, similar to comments. You don’t have to make structural changes to your existing code. With a few lines of NNI annotation, you will be able to:
- annotate the variables you want to tune
- specify the range in which you want to tune the variables
- annotate which variable you want to report as an intermediate result to
assessor - annotate which variable you want to report as the final result (e.g. model accuracy) to
tuner.
Again, take MNIST as an example, it only requires 2 steps to write a trial with NNI Annotation.
Step 1 - Update codes with annotations¶
The following is a TensorFlow code snippet for NNI Annotation where the highlighted four lines are annotations that:
- tune batch_size and dropout_rate
- report test_acc every 100 steps
- lastly report test_acc as the final result.
It’s worth noting that, as these newly added codes are merely annotations, you can still run your code as usual in environments without NNI installed.
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
+ """@nni.variable(nni.choice(50, 250, 500), name=batch_size)"""
batch_size = 128
for i in range(10000):
batch = mnist.train.next_batch(batch_size)
+ """@nni.variable(nni.choice(0.1, 0.5), name=dropout_rate)"""
dropout_rate = 0.5
mnist_network.train_step.run(feed_dict={mnist_network.images: batch[0],
mnist_network.labels: batch[1],
mnist_network.keep_prob: dropout_rate})
if i % 100 == 0:
test_acc = mnist_network.accuracy.eval(
feed_dict={mnist_network.images: mnist.test.images,
mnist_network.labels: mnist.test.labels,
mnist_network.keep_prob: 1.0})
+ """@nni.report_intermediate_result(test_acc)"""
test_acc = mnist_network.accuracy.eval(
feed_dict={mnist_network.images: mnist.test.images,
mnist_network.labels: mnist.test.labels,
mnist_network.keep_prob: 1.0})
+ """@nni.report_final_result(test_acc)"""
NOTE:
@nni.variablewill affect its following line which should be an assignment statement whose left-hand side must be the same as the keywordnamein the@nni.variablestatement.@nni.report_intermediate_result/@nni.report_final_resultwill send the data to assessor/tuner at that line.
For more information about annotation syntax and its usage, please refer to Annotation.
Step 2 - Enable NNI Annotation¶
In the YAML configure file, you need to set useAnnotation to true to enable NNI annotation:
useAnnotation: true
Standalone mode for debugging¶
NNI supports a standalone mode for trial code to run without starting an NNI experiment. This is for finding out bugs in trial code more conveniently. NNI annotation natively supports standalone mode, as the added NNI related lines are comments. For NNI trial APIs, the APIs have changed behaviors in standalone mode, some APIs return dummy values, and some APIs do not really report values. Please refer to the following table for the full list of these APIs.
# NOTE: please assign default values to the hyperparameters in your trial code
nni.get_next_parameter # return {}
nni.report_final_result # have log printed on stdout, but does not report
nni.report_intermediate_result # have log printed on stdout, but does not report
nni.get_experiment_id # return "STANDALONE"
nni.get_trial_id # return "STANDALONE"
nni.get_sequence_id # return 0
You can try standalone mode with the mnist example. Simply run python3 mnist.py under the code directory. The trial code should successfully run with the default hyperparameter values.
For more information on debugging, please refer to How to Debug
Where are my trials?¶
Local Mode¶
In NNI, every trial has a dedicated directory for them to output their own data. In each trial, an environment variable called NNI_OUTPUT_DIR is exported. Under this directory, you can find each trial’s code, data, and other logs. In addition, each trial’s log (including stdout) will be re-directed to a file named trial.log under that directory.
If NNI Annotation is used, the trial’s converted code is in another temporary directory. You can check that in a file named run.sh under the directory indicated by NNI_OUTPUT_DIR. The second line (i.e., the cd command) of this file will change directory to the actual directory where code is located. Below is an example of run.sh:
#!/bin/bash
cd /tmp/user_name/nni/annotation/tmpzj0h72x6 #This is the actual directory
export NNI_PLATFORM=local
export NNI_SYS_DIR=/home/user_name/nni/experiments/$experiment_id$/trials/$trial_id$
export NNI_TRIAL_JOB_ID=nrbb2
export NNI_OUTPUT_DIR=/home/user_name/nni/experiments/$eperiment_id$/trials/$trial_id$
export NNI_TRIAL_SEQ_ID=1
export MULTI_PHASE=false
export CUDA_VISIBLE_DEVICES=
eval python3 mnist.py 2>/home/user_name/nni/experiments/$experiment_id$/trials/$trial_id$/stderr
echo $? `date +%s%3N` >/home/user_name/nni/experiments/$experiment_id$/trials/$trial_id$/.nni/state
Other Modes¶
When running trials on other platforms like remote machine or PAI, the environment variable NNI_OUTPUT_DIR only refers to the output directory of the trial, while the trial code and run.sh might not be there. However, the trial.log will be transmitted back to the local machine in the trial’s directory, which defaults to ~/nni/experiments/$experiment_id$/trials/$trial_id$/
For more information, please refer to HowToDebug.
Builtin-Tuners¶
NNI provides an easy way to adopt an approach to set up parameter tuning algorithms, we call them Tuner.
Tuner receives metrics from Trial to evaluate the performance of a specific parameters/architecture configuration. Tuner sends the next hyper-parameter or architecture configuration to Trial.
Built-in Tuners for Hyperparameter Tuning¶
NNI provides state-of-the-art tuning algorithms as part of our built-in tuners and makes them easy to use. Below is the brief summary of NNI’s current built-in tuners:
Note: Click the Tuner’s name to get the Tuner’s installation requirements, suggested scenario, and an example configuration. A link for a detailed description of each algorithm is located at the end of the suggested scenario for each tuner. Here is an article comparing different Tuners on several problems.
Currently, we support the following algorithms:
| Tuner | Brief Introduction of Algorithm |
|---|---|
| TPE | The Tree-structured Parzen Estimator (TPE) is a sequential model-based optimization (SMBO) approach. SMBO methods sequentially construct models to approximate the performance of hyperparameters based on historical measurements, and then subsequently choose new hyperparameters to test based on this model. Reference Paper |
| Random Search | In Random Search for Hyper-Parameter Optimization show that Random Search might be surprisingly simple and effective. We suggest that we could use Random Search as the baseline when we have no knowledge about the prior distribution of hyper-parameters. Reference Paper |
| Anneal | This simple annealing algorithm begins by sampling from the prior, but tends over time to sample from points closer and closer to the best ones observed. This algorithm is a simple variation on the random search that leverages smoothness in the response surface. The annealing rate is not adaptive. |
| Naïve Evolution | Naïve Evolution comes from Large-Scale Evolution of Image Classifiers. It randomly initializes a population-based on search space. For each generation, it chooses better ones and does some mutation (e.g., change a hyperparameter, add/remove one layer) on them to get the next generation. Naïve Evolution requires many trials to work, but it's very simple and easy to expand new features. Reference paper |
| SMAC | SMAC is based on Sequential Model-Based Optimization (SMBO). It adapts the most prominent previously used model class (Gaussian stochastic process models) and introduces the model class of random forests to SMBO, in order to handle categorical parameters. The SMAC supported by NNI is a wrapper on the SMAC3 GitHub repo. Notice, SMAC needs to be installed by nnictl package command. Reference Paper, GitHub Repo |
| Batch tuner | Batch tuner allows users to simply provide several configurations (i.e., choices of hyper-parameters) for their trial code. After finishing all the configurations, the experiment is done. Batch tuner only supports the type choice in search space spec. |
| Grid Search | Grid Search performs an exhaustive searching through a manually specified subset of the hyperparameter space defined in the searchspace file. Note that the only acceptable types of search space are choice, quniform, randint. |
| Hyperband | Hyperband tries to use limited resources to explore as many configurations as possible and returns the most promising ones as a final result. The basic idea is to generate many configurations and run them for a small number of trials. The half least-promising configurations are thrown out, the remaining are further trained along with a selection of new configurations. The size of these populations is sensitive to resource constraints (e.g. allotted search time). Reference Paper |
| Network Morphism | Network Morphism provides functions to automatically search for deep learning architectures. It generates child networks that inherit the knowledge from their parent network which it is a morph from. This includes changes in depth, width, and skip-connections. Next, it estimates the value of a child network using historic architecture and metric pairs. Then it selects the most promising one to train. Reference Paper |
| Metis Tuner | Metis offers the following benefits when it comes to tuning parameters: While most tools only predict the optimal configuration, Metis gives you two outputs: (a) current prediction of optimal configuration, and (b) suggestion for the next trial. No more guesswork. While most tools assume training datasets do not have noisy data, Metis actually tells you if you need to re-sample a particular hyper-parameter. Reference Paper |
| BOHB | BOHB is a follow-up work to Hyperband. It targets the weakness of Hyperband that new configurations are generated randomly without leveraging finished trials. For the name BOHB, HB means Hyperband, BO means Bayesian Optimization. BOHB leverages finished trials by building multiple TPE models, a proportion of new configurations are generated through these models. Reference Paper |
| GP Tuner | Gaussian Process Tuner is a sequential model-based optimization (SMBO) approach with Gaussian Process as the surrogate. Reference Paper, Github Repo |
| PPO Tuner | PPO Tuner is a Reinforcement Learning tuner based on PPO algorithm. Reference Paper |
| PBT Tuner | PBT Tuner is a simple asynchronous optimization algorithm which effectively utilizes a fixed computational budget to jointly optimize a population of models and their hyperparameters to maximize performance. Reference Paper |
Usage of Built-in Tuners¶
Using a built-in tuner provided by the NNI SDK requires one to declare the builtinTunerName and classArgs in the config.yml file. In this part, we will introduce each tuner along with information about usage and suggested scenarios, classArg requirements, and an example configuration.
Note: Please follow the format when you write your config.yml file. Some built-in tuners need to be installed using nnictl package, like SMAC.
TPE¶
Built-in Tuner Name: TPE
Suggested scenario
TPE, as a black-box optimization, can be used in various scenarios and shows good performance in general. Especially when you have limited computation resources and can only try a small number of trials. From a large amount of experiments, we found that TPE is far better than Random Search. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
Note: We have optimized the parallelism of TPE for large-scale trial concurrency. For the principle of optimization or turn-on optimization, please refer to TPE document.
Example Configuration:
# config.yml
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
Random Search¶
Built-in Tuner Name: Random
Suggested scenario
Random search is suggested when each trial does not take very long (e.g., each trial can be completed very quickly, or early stopped by the assessor), and you have enough computational resources. It’s also useful if you want to uniformly explore the search space. Random Search can be considered a baseline search algorithm. Detailed Description
Example Configuration:
# config.yml
tuner:
builtinTunerName: Random
Anneal¶
Built-in Tuner Name: Anneal
Suggested scenario
Anneal is suggested when each trial does not take very long and you have enough computation resources (very similar to Random Search). It’s also useful when the variables in the search space can be sample from some prior distribution. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
Example Configuration:
# config.yml
tuner:
builtinTunerName: Anneal
classArgs:
optimize_mode: maximize
Naïve Evolution¶
Built-in Tuner Name: Evolution
Suggested scenario
Its computational resource requirements are relatively high. Specifically, it requires a large initial population to avoid falling into a local optimum. If your trial is short or leverages assessor, this tuner is a good choice. It is also suggested when your trial code supports weight transfer; that is, the trial could inherit the converged weights from its parent(s). This can greatly speed up the training process. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
- population_size (int value (should > 0), optional, default = 20) - the initial size of the population (trial num) in the evolution tuner. It’s suggested that
population_sizebe much larger thanconcurrencyso users can get the most out of the algorithm (and at leastconcurrency, or the tuner will fail on its first generation of parameters).
Example Configuration:
# config.yml
tuner:
builtinTunerName: Evolution
classArgs:
optimize_mode: maximize
population_size: 100
SMAC¶
Built-in Tuner Name: SMAC
Please note that SMAC doesn’t support running on Windows currently. For the specific reason, please refer to this GitHub issue.
Installation
SMAC needs to be installed by following command before the first usage. As a reminder, swig is required for SMAC: for Ubuntu swig can be installed with apt.
nnictl package install --name=SMAC
Suggested scenario
Similar to TPE, SMAC is also a black-box tuner that can be tried in various scenarios and is suggested when computational resources are limited. It is optimized for discrete hyperparameters, thus, it’s suggested when most of your hyperparameters are discrete. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
- config_dedup (True or False, optional, default = False) - If True, the tuner will not generate a configuration that has been already generated. If False, a configuration may be generated twice, but it is rare for a relatively large search space.
Example Configuration:
# config.yml
tuner:
builtinTunerName: SMAC
classArgs:
optimize_mode: maximize
Batch Tuner¶
Built-in Tuner Name: BatchTuner
Suggested scenario
If the configurations you want to try have been decided beforehand, you can list them in search space file (using choice) and run them using batch tuner. Detailed Description
Example Configuration:
# config.yml
tuner:
builtinTunerName: BatchTuner
Note that the search space for BatchTuner should look like:
{
"combine_params":
{
"_type" : "choice",
"_value" : [{"optimizer": "Adam", "learning_rate": 0.00001},
{"optimizer": "Adam", "learning_rate": 0.0001},
{"optimizer": "Adam", "learning_rate": 0.001},
{"optimizer": "SGD", "learning_rate": 0.01},
{"optimizer": "SGD", "learning_rate": 0.005},
{"optimizer": "SGD", "learning_rate": 0.0002}]
}
}
The search space file should include the high-level key combine_params. The type of params in the search space must be choice and the values must include all the combined params values.
Grid Search¶
Built-in Tuner Name: Grid Search
Suggested scenario
Note that the only acceptable types within the search space are choice, quniform, and randint.
This is suggested when the search space is small. It’s suggested when it is feasible to exhaustively sweep the whole search space. Detailed Description
Example Configuration:
# config.yml
tuner:
builtinTunerName: GridSearch
Hyperband¶
Built-in Advisor Name: Hyperband
Suggested scenario
This is suggested when you have limited computational resources but have a relatively large search space. It performs well in scenarios where intermediate results can indicate good or bad final results to some extent. For example, when models that are more accurate early on in training are also more accurate later on. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
- R (int, optional, default = 60) - the maximum budget given to a trial (could be the number of mini-batches or epochs). Each trial should use TRIAL_BUDGET to control how long they run.
- eta (int, optional, default = 3) -
(eta-1)/etais the proportion of discarded trials.
Example Configuration:
# config.yml
advisor:
builtinAdvisorName: Hyperband
classArgs:
optimize_mode: maximize
R: 60
eta: 3
Network Morphism¶
Built-in Tuner Name: NetworkMorphism
Installation
NetworkMorphism requires PyTorch and Keras, so users should install them first. The corresponding requirements file is here.
Suggested scenario
This is suggested when you want to apply deep learning methods to your task but you have no idea how to choose or design a network. You may modify this example to fit your own dataset and your own data augmentation method. Also you can change the batch size, learning rate, or optimizer. Currently, this tuner only supports the computer vision domain. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
- task ((‘cv’), optional, default = ‘cv’) - The domain of the experiment. For now, this tuner only supports the computer vision (CV) domain.
- input_width (int, optional, default = 32) - input image width
- input_channel (int, optional, default = 3) - input image channel
- n_output_node (int, optional, default = 10) - number of classes
Example Configuration:
# config.yml
tuner:
builtinTunerName: NetworkMorphism
classArgs:
optimize_mode: maximize
task: cv
input_width: 32
input_channel: 3
n_output_node: 10
Metis Tuner¶
Built-in Tuner Name: MetisTuner
Note that the only acceptable types of search space types are quniform, uniform, randint, and numerical choice. Only numerical values are supported since the values will be used to evaluate the ‘distance’ between different points.
Suggested scenario
Similar to TPE and SMAC, Metis is a black-box tuner. If your system takes a long time to finish each trial, Metis is more favorable than other approaches such as random search. Furthermore, Metis provides guidance on subsequent trials. Here is an example on the use of Metis. Users only need to send the final result, such as accuracy, to the tuner by calling the NNI SDK. Detailed Description
classArgs Requirements:
- optimize_mode (‘maximize’ or ‘minimize’, optional, default = ‘maximize’) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
Example Configuration:
# config.yml
tuner:
builtinTunerName: MetisTuner
classArgs:
optimize_mode: maximize
BOHB Advisor¶
Built-in Tuner Name: BOHB
Installation
BOHB advisor requires ConfigSpace package. ConfigSpace can be installed using the following command.
nnictl package install --name=BOHB
Suggested scenario
Similar to Hyperband, BOHB is suggested when you have limited computational resources but have a relatively large search space. It performs well in scenarios where intermediate results can indicate good or bad final results to some extent. In this case, it may converge to a better configuration than Hyperband due to its usage of Bayesian optimization. Detailed Description
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, tuners will try to maximize metrics. If ‘minimize’, tuner will try to minimize metrics.
- min_budget (int, optional, default = 1) - The smallest budget to assign to a trial job, (budget can be the number of mini-batches or epochs). Needs to be positive.
- max_budget (int, optional, default = 3) - The largest budget to assign to a trial job, (budget can be the number of mini-batches or epochs). Needs to be larger than min_budget.
- eta (int, optional, default = 3) - In each iteration, a complete run of sequential halving is executed. In it, after evaluating each configuration on the same subset size, only a fraction of 1/eta of them ‘advances’ to the next round. Must be greater or equal to 2.
- min_points_in_model(int, optional, default = None): number of observations to start building a KDE. Default ‘None’ means dim+1; when the number of completed trials in this budget is equal to or larger than
max{dim+1, min_points_in_model}, BOHB will start to build a KDE model of this budget then use said KDE model to guide configuration selection. Needs to be positive. (dim means the number of hyperparameters in search space) - top_n_percent(int, optional, default = 15): percentage (between 1 and 99) of the observations which are considered good. Good points and bad points are used for building KDE models. For example, if you have 100 observed trials and top_n_percent is 15, then the top 15% of points will be used for building the good points models “l(x)”. The remaining 85% of points will be used for building the bad point models “g(x)”.
- num_samples(int, optional, default = 64): number of samples to optimize EI (default 64). In this case, we will sample “num_samples” points and compare the result of l(x)/g(x). Then we will return the one with the maximum l(x)/g(x) value as the next configuration if the optimize_mode is
maximize. Otherwise, we return the smallest one. - random_fraction(float, optional, default = 0.33): fraction of purely random configurations that are sampled from the prior without the model.
- bandwidth_factor(float, optional, default = 3.0): to encourage diversity, the points proposed to optimize EI are sampled from a ‘widened’ KDE where the bandwidth is multiplied by this factor. We suggest using the default value if you are not familiar with KDE.
- min_bandwidth(float, optional, default = 0.001): to keep diversity, even when all (good) samples have the same value for one of the parameters, a minimum bandwidth (default: 1e-3) is used instead of zero. We suggest using the default value if you are not familiar with KDE.
Please note that the float type currently only supports decimal representations. You have to use 0.333 instead of 1/3 and 0.001 instead of 1e-3.
Example Configuration:
advisor:
builtinAdvisorName: BOHB
classArgs:
optimize_mode: maximize
min_budget: 1
max_budget: 27
eta: 3
GP Tuner¶
Built-in Tuner Name: GPTuner
Note that the only acceptable types within the search space are randint, uniform, quniform, loguniform, qloguniform, and numerical choice. Only numerical values are supported since the values will be used to evaluate the ‘distance’ between different points.
Suggested scenario
As a strategy in a Sequential Model-based Global Optimization (SMBO) algorithm, GP Tuner uses a proxy optimization problem (finding the maximum of the acquisition function) that, albeit still a hard problem, is cheaper (in the computational sense) to solve and common tools can be employed to solve it. Therefore, GP Tuner is most adequate for situations where the function to be optimized is very expensive to evaluate. GP can be used when computational resources are limited. However, GP Tuner has a computational cost that grows at O(N^3) due to the requirement of inverting the Gram matrix, so it’s not suitable when lots of trials are needed. Detailed Description
classArgs Requirements:
- optimize_mode (‘maximize’ or ‘minimize’, optional, default = ‘maximize’) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
- utility (‘ei’, ‘ucb’ or ‘poi’, optional, default = ‘ei’) - The utility function (acquisition function). ‘ei’, ‘ucb’, and ‘poi’ correspond to ‘Expected Improvement’, ‘Upper Confidence Bound’, and ‘Probability of Improvement’, respectively.
- kappa (float, optional, default = 5) - Used by the ‘ucb’ utility function. The bigger
kappais, the more exploratory the tuner will be. - xi (float, optional, default = 0) - Used by the ‘ei’ and ‘poi’ utility functions. The bigger
xiis, the more exploratory the tuner will be. - nu (float, optional, default = 2.5) - Used to specify the Matern kernel. The smaller nu, the less smooth the approximated function is.
- alpha (float, optional, default = 1e-6) - Used to specify the Gaussian Process Regressor. Larger values correspond to an increased noise level in the observations.
- cold_start_num (int, optional, default = 10) - Number of random explorations to perform before the Gaussian Process. Random exploration can help by diversifying the exploration space.
- selection_num_warm_up (int, optional, default = 1e5) - Number of random points to evaluate when getting the point which maximizes the acquisition function.
- selection_num_starting_points (int, optional, default = 250) - Number of times to run L-BFGS-B from a random starting point after the warmup.
Example Configuration:
# config.yml
tuner:
builtinTunerName: GPTuner
classArgs:
optimize_mode: maximize
utility: 'ei'
kappa: 5.0
xi: 0.0
nu: 2.5
alpha: 1e-6
cold_start_num: 10
selection_num_warm_up: 100000
selection_num_starting_points: 250
PPO Tuner¶
Built-in Tuner Name: PPOTuner
Note that the only acceptable types within the search space are layer_choice and input_choice. For input_choice, n_chosen can only be 0, 1, or [0, 1]. Note, the search space file for NAS is usually automatically generated through the command nnictl ss_gen.
Suggested scenario
PPOTuner is a Reinforcement Learning tuner based on the PPO algorithm. PPOTuner can be used when using the NNI NAS interface to do neural architecture search. In general, the Reinforcement Learning algorithm needs more computing resources, though the PPO algorithm is relatively more efficient than others. It’s recommended to use this tuner when you have a large amount of computional resources available. You could try it on a very simple task, such as the mnist-nas example. See details
classArgs Requirements:
- optimize_mode (‘maximize’ or ‘minimize’) - If ‘maximize’, the tuner will try to maximize metrics. If ‘minimize’, the tuner will try to minimize metrics.
- trials_per_update (int, optional, default = 20) - The number of trials to be used for one update. It must be divisible by minibatch_size.
trials_per_updateis recommended to be an exact multiple oftrialConcurrencyfor better concurrency of trials. - epochs_per_update (int, optional, default = 4) - The number of epochs for one update.
- minibatch_size (int, optional, default = 4) - Mini-batch size (i.e., number of trials for a mini-batch) for the update. Note that trials_per_update must be divisible by minibatch_size.
- ent_coef (float, optional, default = 0.0) - Policy entropy coefficient in the optimization objective.
- lr (float, optional, default = 3e-4) - Learning rate of the model (lstm network); constant.
- vf_coef (float, optional, default = 0.5) - Value function loss coefficient in the optimization objective.
- max_grad_norm (float, optional, default = 0.5) - Gradient norm clipping coefficient.
- gamma (float, optional, default = 0.99) - Discounting factor.
- lam (float, optional, default = 0.95) - Advantage estimation discounting factor (lambda in the paper).
- cliprange (float, optional, default = 0.2) - Cliprange in the PPO algorithm, constant.
Example Configuration:
# config.yml
tuner:
builtinTunerName: PPOTuner
classArgs:
optimize_mode: maximize
PBT Tuner¶
Built-in Tuner Name: PBTTuner
Suggested scenario
Population Based Training (PBT) bridges and extends parallel search methods and sequential optimization methods. It requires relatively small computation resource, by inheriting weights from currently good-performing ones to explore better ones periodically. With PBTTuner, users finally get a trained model, rather than a configuration that could reproduce the trained model by training the model from scratch. This is because model weights are inherited periodically through the whole search process. PBT can also be seen as a training approach. If you don’t need to get a specific configuration, but just expect a good model, PBTTuner is a good choice. See details
classArgs requirements:
- optimize_mode (‘maximize’ or ‘minimize’) - If ‘maximize’, the tuner will target to maximize metrics. If ‘minimize’, the tuner will target to minimize metrics.
- all_checkpoint_dir (str, optional, default = None) - Directory for trials to load and save checkpoint, if not specified, the directory would be “~/nni/checkpoint/
”. Note that if the experiment is not local mode, users should provide a path in a shared storage which can be accessed by all the trials. - population_size (int, optional, default = 10) - Number of trials in a population. Each step has this number of trials. In our implementation, one step is running each trial by specific training epochs set by users.
- factors (tuple, optional, default = (1.2, 0.8)) - Factors for perturbation of hyperparameters.
- fraction (float, optional, default = 0.2) - Fraction for selecting bottom and top trials.
Usage example
# config.yml
tuner:
builtinTunerName: PBTTuner
classArgs:
optimize_mode: maximize
Note that, to use this tuner, your trial code should be modified accordingly, please refer to the document of PBTTuner for details.
Reference and Feedback¶
- To report a bug for this feature in GitHub;
- To file a feature or improvement request for this feature in GitHub;
- To know more about Feature Engineering with NNI;
- To know more about NAS with NNI;
- To know more about Model Compression with NNI;
TPE, Random Search, Anneal Tuners on NNI¶
TPE¶
The Tree-structured Parzen Estimator (TPE) is a sequential model-based optimization (SMBO) approach. SMBO methods sequentially construct models to approximate the performance of hyperparameters based on historical measurements, and then subsequently choose new hyperparameters to test based on this model. The TPE approach models P(x|y) and P(y) where x represents hyperparameters and y the associated evaluation matric. P(x|y) is modeled by transforming the generative process of hyperparameters, replacing the distributions of the configuration prior with non-parametric densities. This optimization approach is described in detail in Algorithms for Hyper-Parameter Optimization.
Parallel TPE optimization¶
TPE approaches were actually run asynchronously in order to make use of multiple compute nodes and to avoid wasting time waiting for trial evaluations to complete. The original algorithm design was optimized for sequential computation. If we were to use TPE with much concurrency, its performance will be bad. We have optimized this case using the Constant Liar algorithm. For these principles of optimization, please refer to our research blog.
Usage¶
To use TPE, you should add the following spec in your experiment’s YAML config file:
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
parallel_optimize: True
constant_liar_type: min
classArgs requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, tuners will try to maximize metrics. If ‘minimize’, tuner will try to minimize metrics.
- parallel_optimize (bool, optional, default = False) - If True, TPE will use the Constant Liar algorithm to optimize parallel hyperparameter tuning. Otherwise, TPE will not discriminate between sequential or parallel situations.
- constant_liar_type (min or max or mean, optional, default = min) - The type of constant liar to use, will logically be determined on the basis of the values taken by y at X. There are three possible values, min{Y}, max{Y}, and mean{Y}.
Random Search¶
In Random Search for Hyper-Parameter Optimization we show that Random Search might be surprisingly effective despite its simplicity. We suggest using Random Search as a baseline when no knowledge about the prior distribution of hyper-parameters is available.
Anneal¶
This simple annealing algorithm begins by sampling from the prior but tends over time to sample from points closer and closer to the best ones observed. This algorithm is a simple variation on random search that leverages smoothness in the response surface. The annealing rate is not adaptive.
Naive Evolution Tuners on NNI¶
Naive Evolution¶
Naive Evolution comes from Large-Scale Evolution of Image Classifiers. It randomly initializes a population based on the search space. For each generation, it chooses better ones and does some mutation (e.g., changes a hyperparameter, adds/removes one layer, etc.) on them to get the next generation. Naive Evolution requires many trials to works but it’s very simple and it’s easily expanded with new features.
SMAC Tuner on NNI¶
SMAC¶
SMAC is based on Sequential Model-Based Optimization (SMBO). It adapts the most prominent previously used model class (Gaussian stochastic process models) and introduces the model class of random forests to SMBO in order to handle categorical parameters. The SMAC supported by nni is a wrapper on the SMAC3 github repo.
Note that SMAC on nni only supports a subset of the types in the search space spec: choice, randint, uniform, loguniform, and quniform.
Metis Tuner on NNI¶
Metis Tuner¶
Metis offers several benefits over other tuning algorithms. While most tools only predict the optimal configuration, Metis gives you two outputs, a prediction for the optimal configuration and a suggestion for the next trial. No more guess work!
While most tools assume training datasets do not have noisy data, Metis actually tells you if you need to resample a particular hyper-parameter.
While most tools have problems of being exploitation-heavy, Metis’ search strategy balances exploration, exploitation, and (optional) resampling.
Metis belongs to the class of sequential model-based optimization (SMBO) algorithms and it is based on the Bayesian Optimization framework. To model the parameter-vs-performance space, Metis uses both a Gaussian Process and GMM. Since each trial can impose a high time cost, Metis heavily trades inference computations with naive trials. At each iteration, Metis does two tasks:
- It finds the global optimal point in the Gaussian Process space. This point represents the optimal configuration.
- It identifies the next hyper-parameter candidate. This is achieved by inferring the potential information gain of exploration, exploitation, and resampling.
Note that the only acceptable types within the search space are quniform, uniform, randint, and numerical choice.
More details can be found in our paper.
Batch Tuner on NNI¶
Batch Tuner¶
Batch tuner allows users to simply provide several configurations (i.e., choices of hyper-parameters) for their trial code. After finishing all the configurations, the experiment is done. Batch tuner only supports the type choice in the search space spec.
Suggested scenario: If the configurations you want to try have been decided, you can list them in the SearchSpace file (using choice) and run them using the batch tuner.
Grid Search on NNI¶
Grid Search¶
Grid Search performs an exhaustive search through a manually specified subset of the hyperparameter space defined in the searchspace file.
Note that the only acceptable types within the search space are choice, quniform, and randint.
GP Tuner on NNI¶
GP Tuner¶
Bayesian optimization works by constructing a posterior distribution of functions (a Gaussian Process) that best describes the function you want to optimize. As the number of observations grows, the posterior distribution improves, and the algorithm becomes more certain of which regions in parameter space are worth exploring and which are not.
GP Tuner is designed to minimize/maximize the number of steps required to find a combination of parameters that are close to the optimal combination. To do so, this method uses a proxy optimization problem (finding the maximum of the acquisition function) that, albeit still a hard problem, is cheaper (in the computational sense) to solve, and it’s amenable to common tools. Therefore, Bayesian Optimization is suggested for situations where sampling the function to be optimized is very expensive.
Note that the only acceptable types within the search space are randint, uniform, quniform, loguniform, qloguniform, and numerical choice.
This optimization approach is described in Section 3 of Algorithms for Hyper-Parameter Optimization.
Network Morphism Tuner on NNI¶
1. Introduction¶
Autokeras is a popular autoML tool using Network Morphism. The basic idea of Autokeras is to use Bayesian Regression to estimate the metric of the Neural Network Architecture. Each time, it generates several child networks from father networks. Then it uses a naïve Bayesian regression to estimate its metric value from the history of trained results of network and metric value pairs. Next, it chooses the child which has the best, estimated performance and adds it to the training queue. Inspired by the work of Autokeras and referring to its code, we implemented our Network Morphism method on the NNI platform.
If you want to know more about network morphism trial usage, please see the Readme.md.
2. Usage¶
To use Network Morphism, you should modify the following spec in your config.yml file:
tuner:
#choice: NetworkMorphism
builtinTunerName: NetworkMorphism
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
#for now, this tuner only supports cv domain
task: cv
#modify to fit your input image width
input_width: 32
#modify to fit your input image channel
input_channel: 3
#modify to fit your number of classes
n_output_node: 10
In the training procedure, it generates a JSON file which represents a Network Graph. Users can call the “json_to_graph()” function to build a PyTorch or Keras model from this JSON file.
import nni
from nni.networkmorphism_tuner.graph import json_to_graph
def build_graph_from_json(ir_model_json):
"""build a pytorch model from json representation
"""
graph = json_to_graph(ir_model_json)
model = graph.produce_torch_model()
return model
# trial get next parameter from network morphism tuner
RCV_CONFIG = nni.get_next_parameter()
# call the function to build pytorch model or keras model
net = build_graph_from_json(RCV_CONFIG)
# training procedure
# ....
# report the final accuracy to NNI
nni.report_final_result(best_acc)
If you want to save and load the best model, the following methods are recommended.
# 1. Use NNI API
## You can get the best model ID from WebUI
## or `nni/experiments/experiment_id/log/model_path/best_model.txt'
## read the json string from model file and load it with NNI API
with open("best-model.json") as json_file:
json_of_model = json_file.read()
model = build_graph_from_json(json_of_model)
# 2. Use Framework API (Related to Framework)
## 2.1 Keras API
## Save the model with Keras API in the trial code
## it's better to save model with id in nni local mode
model_id = nni.get_sequence_id()
## serialize model to JSON
model_json = model.to_json()
with open("model-{}.json".format(model_id), "w") as json_file:
json_file.write(model_json)
## serialize weights to HDF5
model.save_weights("model-{}.h5".format(model_id))
## Load the model with Keras API if you want to reuse the model
## load json and create model
model_id = "" # id of the model you want to reuse
with open('model-{}.json'.format(model_id), 'r') as json_file:
loaded_model_json = json_file.read()
loaded_model = model_from_json(loaded_model_json)
## load weights into new model
loaded_model.load_weights("model-{}.h5".format(model_id))
## 2.2 PyTorch API
## Save the model with PyTorch API in the trial code
model_id = nni.get_sequence_id()
torch.save(model, "model-{}.pt".format(model_id))
## Load the model with PyTorch API if you want to reuse the model
model_id = "" # id of the model you want to reuse
loaded_model = torch.load("model-{}.pt".format(model_id))
3. File Structure¶
The tuner has a lot of different files, functions, and classes. Here, we will give most of those files only a brief introduction:
networkmorphism_tuner.pyis a tuner which uses network morphism techniques.bayesian.pyis a Bayesian method to estimate the metric of unseen model based on the models we have already searched.graph.pyis the meta graph data structure. The class Graph represents the neural architecture graph of a model.- Graph extracts the neural architecture graph from a model.
- Each node in the graph is an intermediate tensor between layers.
- Each layer is an edge in the graph.
- Notably, multiple edges may refer to the same layer.
graph_transformer.pyincludes some graph transformers which widen, deepen, or add skip-connections to the graph.layers.pyincludes all the layers we use in our model.layer_transformer.pyincludes some layer transformers which widen, deepen, or add skip-connections to the layer.nn.pyincludes the class which generates the initial network.metric.pysome metric classes including Accuracy and MSE.utils.pyis the example search network architectures for thecifar10dataset, using Keras.
4. The Network Representation Json Example¶
Here is an example of the intermediate representation JSON file we defined, which is passed from the tuner to the trial in the architecture search procedure. Users can call the “json_to_graph()” function in the trial code to build a PyTorch or Keras model from this JSON file.
{
"input_shape": [32, 32, 3],
"weighted": false,
"operation_history": [],
"layer_id_to_input_node_ids": {"0": [0],"1": [1],"2": [2],"3": [3],"4": [4],"5": [5],"6": [6],"7": [7],"8": [8],"9": [9],"10": [10],"11": [11],"12": [12],"13": [13],"14": [14],"15": [15],"16": [16]
},
"layer_id_to_output_node_ids": {"0": [1],"1": [2],"2": [3],"3": [4],"4": [5],"5": [6],"6": [7],"7": [8],"8": [9],"9": [10],"10": [11],"11": [12],"12": [13],"13": [14],"14": [15],"15": [16],"16": [17]
},
"adj_list": {
"0": [[1, 0]],
"1": [[2, 1]],
"2": [[3, 2]],
"3": [[4, 3]],
"4": [[5, 4]],
"5": [[6, 5]],
"6": [[7, 6]],
"7": [[8, 7]],
"8": [[9, 8]],
"9": [[10, 9]],
"10": [[11, 10]],
"11": [[12, 11]],
"12": [[13, 12]],
"13": [[14, 13]],
"14": [[15, 14]],
"15": [[16, 15]],
"16": [[17, 16]],
"17": []
},
"reverse_adj_list": {
"0": [],
"1": [[0, 0]],
"2": [[1, 1]],
"3": [[2, 2]],
"4": [[3, 3]],
"5": [[4, 4]],
"6": [[5, 5]],
"7": [[6, 6]],
"8": [[7, 7]],
"9": [[8, 8]],
"10": [[9, 9]],
"11": [[10, 10]],
"12": [[11, 11]],
"13": [[12, 12]],
"14": [[13, 13]],
"15": [[14, 14]],
"16": [[15, 15]],
"17": [[16, 16]]
},
"node_list": [
[0, [32, 32, 3]],
[1, [32, 32, 3]],
[2, [32, 32, 64]],
[3, [32, 32, 64]],
[4, [16, 16, 64]],
[5, [16, 16, 64]],
[6, [16, 16, 64]],
[7, [16, 16, 64]],
[8, [8, 8, 64]],
[9, [8, 8, 64]],
[10, [8, 8, 64]],
[11, [8, 8, 64]],
[12, [4, 4, 64]],
[13, [64]],
[14, [64]],
[15, [64]],
[16, [64]],
[17, [10]]
],
"layer_list": [
[0, ["StubReLU", 0, 1]],
[1, ["StubConv2d", 1, 2, 3, 64, 3]],
[2, ["StubBatchNormalization2d", 2, 3, 64]],
[3, ["StubPooling2d", 3, 4, 2, 2, 0]],
[4, ["StubReLU", 4, 5]],
[5, ["StubConv2d", 5, 6, 64, 64, 3]],
[6, ["StubBatchNormalization2d", 6, 7, 64]],
[7, ["StubPooling2d", 7, 8, 2, 2, 0]],
[8, ["StubReLU", 8, 9]],
[9, ["StubConv2d", 9, 10, 64, 64, 3]],
[10, ["StubBatchNormalization2d", 10, 11, 64]],
[11, ["StubPooling2d", 11, 12, 2, 2, 0]],
[12, ["StubGlobalPooling2d", 12, 13]],
[13, ["StubDropout2d", 13, 14, 0.25]],
[14, ["StubDense", 14, 15, 64, 64]],
[15, ["StubReLU", 15, 16]],
[16, ["StubDense", 16, 17, 64, 10]]
]
}
You can consider the model to be a directed acyclic graph. The definition of each model is a JSON object where:
input_shapeis a list of integers which do not include the batch axis.weightedmeans whether the weights and biases in the neural network should be included in the graph.operation_historyis a list saving all the network morphism operations.layer_id_to_input_node_idsis a dictionary mapping from layer identifiers to their input nodes identifiers.layer_id_to_output_node_idsis a dictionary mapping from layer identifiers to their output nodes identifiersadj_listis a two-dimensional list; the adjacency list of the graph. The first dimension is identified by tensor identifiers. In each edge list, the elements are two-element tuples of (tensor identifier, layer identifier).reverse_adj_listis a reverse adjacent list in the same format as adj_list.node_listis a list of integers. The indices of the list are the identifiers.layer_listis a list of stub layers. The indices of the list are the identifiers.- For
StubConv (StubConv1d, StubConv2d, StubConv3d), the numbering follows the format: its node input id (or id list), node output id, input_channel, filters, kernel_size, stride, and padding. - For
StubDense, the numbering follows the format: its node input id (or id list), node output id, input_units, and units. - For
StubBatchNormalization (StubBatchNormalization1d, StubBatchNormalization2d, StubBatchNormalization3d), the numbering follows the format: its node input id (or id list), node output id, and features numbers. - For
StubDropout(StubDropout1d, StubDropout2d, StubDropout3d), the numbering follows the format: its node input id (or id list), node output id, and dropout rate. - For
StubPooling (StubPooling1d, StubPooling2d, StubPooling3d), the numbering follows the format: its node input id (or id list), node output id, kernel_size, stride, and padding. - For else layers, the numbering follows the format: its node input id (or id list) and node output id.
- For
5. TODO¶
Next step, we will change the API from s fixed network generator to a network generator with more available operators. We will use ONNX instead of JSON later as the intermediate representation spec in the future.
Hyperband on NNI¶
1. Introduction¶
Hyperband is a popular autoML algorithm. The basic idea of Hyperband is to create several buckets, each having n randomly generated hyperparameter configurations, each configuration using r resources (e.g., epoch number, batch number). After the n configurations are finished, it chooses the top n/eta configurations and runs them using increased r*eta resources. At last, it chooses the best configuration it has found so far.
2. Implementation with full parallelism¶
First, this is an example of how to write an autoML algorithm based on MsgDispatcherBase, rather than Tuner and Assessor. Hyperband is implemented in this way because it integrates the functions of both Tuner and Assessor, thus, we call it Advisor.
Second, this implementation fully leverages Hyperband’s internal parallelism. Specifically, the next bucket is not started strictly after the current bucket. Instead, it starts when there are available resources.
3. Usage¶
To use Hyperband, you should add the following spec in your experiment’s YAML config file:
advisor:
#choice: Hyperband
builtinAdvisorName: Hyperband
classArgs:
#R: the maximum trial budget
R: 100
#eta: proportion of discarded trials
eta: 3
#choice: maximize, minimize
optimize_mode: maximize
Note that once you use Advisor, you are not allowed to add a Tuner and Assessor spec in the config file. If you use Hyperband, among the hyperparameters (i.e., key-value pairs) received by a trial, there will be one more key called TRIAL_BUDGET defined by user. By using this TRIAL_BUDGET, the trial can control how long it runs.
For report_intermediate_result(metric) and report_final_result(metric) in your trial code, metric should be either a number or a dict which has a key default with a number as its value. This number is the one you want to maximize or minimize, for example, accuracy or loss.
R and eta are the parameters of Hyperband that you can change. R means the maximum trial budget that can be allocated to a configuration. Here, trial budget could mean the number of epochs or mini-batches. This TRIAL_BUDGET should be used by the trial to control how long it runs. Refer to the example under examples/trials/mnist-advisor/ for details.
eta means n/eta configurations from n configurations will survive and rerun using more budgets.
Here is a concrete example of R=81 and eta=3:
| s=4 | s=3 | s=2 | s=1 | s=0 | |
|---|---|---|---|---|---|
| i | n r | n r | n r | n r | n r |
| 0 | 81 1 | 27 3 | 9 9 | 6 27 | 5 81 |
| 1 | 27 3 | 9 9 | 3 27 | 2 81 | |
| 2 | 9 9 | 3 27 | 1 81 | ||
| 3 | 3 27 | 1 81 | |||
| 4 | 1 81 |
s means bucket, n means the number of configurations that are generated, the corresponding r means how many budgets these configurations run. i means round, for example, bucket 4 has 5 rounds, bucket 3 has 4 rounds.
For information about writing trial code, please refer to the instructions under examples/trials/mnist-hyperband/.
4. Future improvements¶
The current implementation of Hyperband can be further improved by supporting a simple early stop algorithm since it’s possible that not all the configurations in the top n/eta perform well. Any unpromising configurations should be stopped early.
In the current implementation, configurations are generated randomly which follows the design in the paper. As an improvement, configurations could be generated more wisely by leveraging advanced algorithms.
BOHB Advisor on NNI¶
1. Introduction¶
BOHB is a robust and efficient hyperparameter tuning algorithm mentioned in this reference paper. BO is an abbreviation for “Bayesian Optimization” and HB is an abbreviation for “Hyperband”.
BOHB relies on HB (Hyperband) to determine how many configurations to evaluate with which budget, but it replaces the random selection of configurations at the beginning of each HB iteration by a model-based search (Bayesian Optimization). Once the desired number of configurations for the iteration is reached, the standard successive halving procedure is carried out using these configurations. We keep track of the performance of all function evaluations g(x, b) of configurations x on all budgets b to use as a basis for our models in later iterations.
Below we divide the introduction of the BOHB process into two parts:
HB (Hyperband)¶
We follow Hyperband’s way of choosing the budgets and continue to use SuccessiveHalving. For more details, you can refer to the Hyperband in NNI and the reference paper for Hyperband. This procedure is summarized by the pseudocode below.

BO (Bayesian Optimization)¶
The BO part of BOHB closely resembles TPE with one major difference: we opted for a single multidimensional KDE compared to the hierarchy of one-dimensional KDEs used in TPE in order to better handle interaction effects in the input space.
Tree Parzen Estimator(TPE): uses a KDE (kernel density estimator) to model the densities.

To fit useful KDEs, we require a minimum number of data points Nmin; this is set to d + 1 for our experiments, where d is the number of hyperparameters. To build a model as early as possible, we do not wait until Nb = |Db|, where the number of observations for budget b is large enough to satisfy q · Nb ≥ Nmin. Instead, after initializing with Nmin + 2 random configurations, we choose the

best and worst configurations, respectively, to model the two densities.
Note that we also sample a constant fraction named random fraction of the configurations uniformly at random.
2. Workflow¶

This image shows the workflow of BOHB. Here we set max_budget = 9, min_budget = 1, eta = 3, others as default. In this case, s_max = 2, so we will continuously run the {s=2, s=1, s=0, s=2, s=1, s=0, …} cycle. In each stage of SuccessiveHalving (the orange box), we will pick the top 1/eta configurations and run them again with more budget, repeating the SuccessiveHalving stage until the end of this iteration. At the same time, we collect the configurations, budgets and final metrics of each trial and use these to build a multidimensional KDEmodel with the key “budget”. Multidimensional KDE is used to guide the selection of configurations for the next iteration.
The sampling procedure (using Multidimensional KDE to guide selection) is summarized by the pseudocode below.

3. Usage¶
BOHB advisor requires the ConfigSpace package. ConfigSpace can be installed using the following command.
nnictl package install --name=BOHB
To use BOHB, you should add the following spec in your experiment’s YAML config file:
advisor:
builtinAdvisorName: BOHB
classArgs:
optimize_mode: maximize
min_budget: 1
max_budget: 27
eta: 3
min_points_in_model: 7
top_n_percent: 15
num_samples: 64
random_fraction: 0.33
bandwidth_factor: 3.0
min_bandwidth: 0.001
classArgs Requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, tuners will try to maximize metrics. If ‘minimize’, tuner will try to minimize metrics.
- min_budget (int, optional, default = 1) - The smallest budget to assign to a trial job, (budget can be the number of mini-batches or epochs). Needs to be positive.
- max_budget (int, optional, default = 3) - The largest budget to assign to a trial job, (budget can be the number of mini-batches or epochs). Needs to be larger than min_budget.
- eta (int, optional, default = 3) - In each iteration, a complete run of sequential halving is executed. In it, after evaluating each configuration on the same subset size, only a fraction of 1/eta of them ‘advances’ to the next round. Must be greater or equal to 2.
- min_points_in_model(int, optional, default = None): number of observations to start building a KDE. Default ‘None’ means dim+1; when the number of completed trials in this budget is equal to or larger than
max{dim+1, min_points_in_model}, BOHB will start to build a KDE model of this budget then use said KDE model to guide configuration selection. Needs to be positive. (dim means the number of hyperparameters in search space) - top_n_percent(int, optional, default = 15): percentage (between 1 and 99) of the observations which are considered good. Good points and bad points are used for building KDE models. For example, if you have 100 observed trials and top_n_percent is 15, then the top 15% of points will be used for building the good points models “l(x)”. The remaining 85% of points will be used for building the bad point models “g(x)”.
- num_samples(int, optional, default = 64): number of samples to optimize EI (default 64). In this case, we will sample “num_samples” points and compare the result of l(x)/g(x). Then we will return the one with the maximum l(x)/g(x) value as the next configuration if the optimize_mode is
maximize. Otherwise, we return the smallest one. - random_fraction(float, optional, default = 0.33): fraction of purely random configurations that are sampled from the prior without the model.
- bandwidth_factor(float, optional, default = 3.0): to encourage diversity, the points proposed to optimize EI are sampled from a ‘widened’ KDE where the bandwidth is multiplied by this factor. We suggest using the default value if you are not familiar with KDE.
- min_bandwidth(float, optional, default = 0.001): to keep diversity, even when all (good) samples have the same value for one of the parameters, a minimum bandwidth (default: 1e-3) is used instead of zero. We suggest using the default value if you are not familiar with KDE.
Please note that the float type currently only supports decimal representations. You have to use 0.333 instead of 1/3 and 0.001 instead of 1e-3.
4. File Structure¶
The advisor has a lot of different files, functions, and classes. Here, we will only give most of those files a brief introduction:
bohb_advisor.pyDefinition of BOHB, handles interaction with the dispatcher, including generating new trials and processing results. Also includes the implementation of the HB (Hyperband) part.config_generator.pyIncludes the implementation of the BO (Bayesian Optimization) part. The function get_config can generate new configurations based on BO; the function new_result will update the model with the new result.
5. Experiment¶
MNIST with BOHB¶
code implementation: examples/trials/mnist-advisor
We chose BOHB to build a CNN on the MNIST dataset. The following is our experimental final results:

More experimental results can be found in the reference paper. We can see that BOHB makes good use of previous results and has a balanced trade-off in exploration and exploitation.
PPO Tuner on NNI¶
PPOTuner¶
This is a tuner geared for NNI’s Neural Architecture Search (NAS) interface. It uses the ppo algorithm. The implementation inherits the main logic of the ppo2 OpenAI implementation here and is adapted for the NAS scenario.
We had successfully tuned the mnist-nas example and has the following result: NOTE: we are refactoring this example to the latest NAS interface, will publish the example codes after the refactor.

We also tune the macro search space for image classification in the enas paper (with a limited epoch number for each trial, i.e., 8 epochs), which is implemented using the NAS interface and tuned with PPOTuner. Here is Figure 7 from the enas paper to show what the search space looks like

The figure above was the chosen architecture. Each square is a layer whose operation was chosen from 6 options. Each dashed line is a skip connection, each square layer can choose 0 or 1 skip connections, getting the output from a previous layer. Note that, in original macro search space, each square layer could choose any number of skip connections, while in our implementation, it is only allowed to choose 0 or 1.
The results are shown in figure below (see the experimenal config here:

PBT Tuner on NNI¶
PBTTuner¶
Population Based Training (PBT) comes from Population Based Training of Neural Networks. It’s a simple asynchronous optimization algorithm which effectively utilizes a fixed computational budget to jointly optimize a population of models and their hyperparameters to maximize performance. Importantly, PBT discovers a schedule of hyperparameter settings rather than following the generally sub-optimal strategy of trying to find a single fixed set to use for the whole course of training.

PBTTuner initializes a population with several trials (i.e., population_size). There are four steps in the above figure, each trial only runs by one step. How long is one step is controlled by trial code, e.g., one epoch. When a trial starts, it loads a checkpoint specified by PBTTuner and continues to run one step, then saves checkpoint to a directory specified by PBTTuner and exits. The trials in a population run steps synchronously, that is, after all the trials finish the i-th step, the (i+1)-th step can be started. Exploitation and exploration of PBT are executed between two consecutive steps.
Provide checkpoint directory¶
Since some trials need to load other trial’s checkpoint, users should provide a directory (i.e., all_checkpoint_dir) which is accessible by every trial. It is easy for local mode, users could directly use the default directory or specify any directory on the local machine. For other training services, users should follow the document of those training services to provide a directory in a shared storage, such as NFS, Azure storage.
Modify your trial code¶
Before running a step, a trial needs to load a checkpoint, the checkpoint directory is specified in hyper-parameter configuration generated by PBTTuner, i.e., params['load_checkpoint_dir']. Similarly, the directory for saving checkpoint is also included in the configuration, i.e., params['save_checkpoint_dir']. Here, all_checkpoint_dir is base folder of load_checkpoint_dir and save_checkpoint_dir whose format is all_checkpoint_dir/<population-id>/<step>.
params = nni.get_next_parameter()
# the path of the checkpoint to load
load_path = os.path.join(params['load_checkpoint_dir'], 'model.pth')
# load checkpoint from `load_path`
...
# run one step
...
# the path for saving a checkpoint
save_path = os.path.join(params['save_checkpoint_dir'], 'model.pth')
# save checkpoint to `save_path`
...
The complete example code can be found here.
Experiment config¶
Below is an exmaple of PBTTuner configuration in experiment config file. Note that Assessor is not allowed if PBTTuner is used.
# config.yml
tuner:
builtinTunerName: PBTTuner
classArgs:
optimize_mode: maximize
all_checkpoint_dir: /the/path/to/store/checkpoints
population_size: 10
Builtin-Assessors¶
In order to save on computing resources, NNI supports an early stopping policy and has an interface called Assessor to do this job.
Assessor receives the intermediate result from a trial and decides whether the trial should be killed using a specific algorithm. Once the trial experiment meets the early stopping conditions (which means Assessor is pessimistic about the final results), the assessor will kill the trial and the status of the trial will be EARLY_STOPPED.
Here is an experimental result of MNIST after using the ‘Curvefitting’ Assessor in ‘maximize’ mode. You can see that Assessor successfully early stopped many trials with bad hyperparameters in advance. If you use Assessor, you may get better hyperparameters using the same computing resources.
Implemented code directory: [config_assessor.yml](https://github.com/Microsoft/nni/blob/master/examples/trials/mnist-tfv1/config_assessor.yml)

Built-in Assessors¶
NNI provides state-of-the-art tuning algorithms within our builtin-assessors and makes them easy to use. Below is a brief overview of NNI’s current builtin Assessors.
Note: Click the Assessor’s name to get each Assessor’s installation requirements, suggested usage scenario, and a config example. A link to a detailed description of each algorithm is provided at the end of the suggested scenario for each Assessor.
Currently, we support the following Assessors:
| Assessor | Brief Introduction of Algorithm |
|---|---|
| Medianstop | Medianstop is a simple early stopping rule. It stops a pending trial X at step S if the trial’s best objective value by step S is strictly worse than the median value of the running averages of all completed trials’ objectives reported up to step S. Reference Paper |
| Curvefitting | Curve Fitting Assessor is an LPA (learning, predicting, assessing) algorithm. It stops a pending trial X at step S if the prediction of the final epoch's performance worse than the best final performance in the trial history. In this algorithm, we use 12 curves to fit the accuracy curve. Reference Paper |
Usage of Builtin Assessors¶
Usage of builtin assessors provided by the NNI SDK requires one to declare the builtinAssessorName and classArgs in the config.yml file. In this part, we will introduce the details of usage and the suggested scenarios, classArg requirements, and an example for each assessor.
Note: Please follow the provided format when writing your config.yml file.
Median Stop Assessor¶
Builtin Assessor Name: Medianstop
Suggested scenario
It’s applicable in a wide range of performance curves, thus, it can be used in various scenarios to speed up the tuning progress. Detailed Description
classArgs requirements:
- optimize_mode (maximize or minimize, optional, default = maximize) - If ‘maximize’, assessor will stop the trial with smaller expectation. If ‘minimize’, assessor will stop the trial with larger expectation.
- start_step (int, optional, default = 0) - A trial is determined to be stopped or not only after receiving start_step number of reported intermediate results.
Usage example:
# config.yml
assessor:
builtinAssessorName: Medianstop
classArgs:
optimize_mode: maximize
start_step: 5
Curve Fitting Assessor¶
Builtin Assessor Name: Curvefitting
Suggested scenario
It’s applicable in a wide range of performance curves, thus, it can be used in various scenarios to speed up the tuning progress. Even better, it’s able to handle and assess curves with similar performance. Detailed Description
Note, according to the original paper, only incremental functions are supported. Therefore this assessor can only be used to maximize optimization metrics. For example, it can be used for accuracy, but not for loss.
classArgs requirements:
- epoch_num (int, required) - The total number of epochs. We need to know the number of epochs to determine which points we need to predict.
- start_step (int, optional, default = 6) - A trial is determined to be stopped or not only after receiving start_step number of reported intermediate results.
- threshold (float, optional, default = 0.95) - The threshold that we use to decide to early stop the worst performance curve. For example: if threshold = 0.95, and the best performance in the history is 0.9, then we will stop the trial who’s predicted value is lower than 0.95 * 0.9 = 0.855.
- gap (int, optional, default = 1) - The gap interval between Assessor judgements. For example: if gap = 2, start_step = 6, then we will assess the result when we get 6, 8, 10, 12…intermediate results.
Usage example:
# config.yml
assessor:
builtinAssessorName: Curvefitting
classArgs:
epoch_num: 20
start_step: 6
threshold: 0.95
gap: 1
Medianstop Assessor on NNI¶
Curve Fitting Assessor on NNI¶
Introduction¶
The Curve Fitting Assessor is an LPA (learning, predicting, assessing) algorithm. It stops a pending trial X at step S if the prediction of the final epoch’s performance is worse than the best final performance in the trial history.
In this algorithm, we use 12 curves to fit the learning curve. The set of parametric curve models are chosen from this reference paper. The learning curves’ shape coincides with our prior knowledge about the form of learning curves: They are typically increasing, saturating functions.
 learning_curve
learning_curve
We combine all learning curve models into a single, more powerful model. This combined model is given by a weighted linear combination:
 f_comb
f_comb
with the new combined parameter vector
 expression_xi
expression_xi
Assuming additive Gaussian noise and the noise parameter being initialized to its maximum likelihood estimate.
We determine the maximum probability value of the new combined parameter vector by learning the historical data. We use such a value to predict future trial performance and stop the inadequate experiments to save computing resources.
Concretely, this algorithm goes through three stages of learning, predicting, and assessing.
- Step1: Learning. We will learn about the trial history of the current trial and determine the \xi at the Bayesian angle. First of all, We fit each curve using the least-squares method, implemented by
fit_theta. After we obtained the parameters, we filter the curve and remove the outliers, implemented byfilter_curve. Finally, we use the MCMC sampling method. implemented bymcmc_sampling, to adjust the weight of each curve. Up to now, we have determined all the parameters in \xi. - Step2: Predicting. It calculates the expected final result accuracy, implemented by
f_comb, at the target position (i.e., the total number of epochs) by \xi and the formula of the combined model. - Step3: If the fitting result doesn’t converge, the predicted value will be
None. In this case, we returnAssessResult.Goodto ask for future accuracy information and predict again. Furthermore, we will get a positive value from thepredict()function. If this value is strictly greater than the best final performance in history *THRESHOLD(default value = 0.95), returnAssessResult.Good, otherwise, returnAssessResult.Bad
The figure below is the result of our algorithm on MNIST trial history data, where the green point represents the data obtained by Assessor, the blue point represents the future but unknown data, and the red line is the Curve predicted by the Curve fitting assessor.
 examples
examples
Usage¶
To use Curve Fitting Assessor, you should add the following spec in your experiment’s YAML config file:
assessor:
builtinAssessorName: Curvefitting
classArgs:
# (required)The total number of epoch.
# We need to know the number of epoch to determine which point we need to predict.
epoch_num: 20
# (optional) In order to save our computing resource, we start to predict when we have more than only after receiving start_step number of reported intermediate results.
# The default value of start_step is 6.
start_step: 6
# (optional) The threshold that we decide to early stop the worse performance curve.
# For example: if threshold = 0.95, best performance in the history is 0.9, then we will stop the trial which predict value is lower than 0.95 * 0.9 = 0.855.
# The default value of threshold is 0.95.
threshold: 0.95
# (optional) The gap interval between Assesor judgements.
# For example: if gap = 2, start_step = 6, then we will assess the result when we get 6, 8, 10, 12...intermedian result.
# The default value of gap is 1.
gap: 1
Limitation¶
According to the original paper, only incremental functions are supported. Therefore this assessor can only be used to maximize optimization metrics. For example, it can be used for accuracy, but not for loss.
File Structure¶
The assessor has a lot of different files, functions, and classes. Here we briefly describe a few of them.
curvefunctions.pyincludes all the function expressions and default parameters.modelfactory.pyincludes learning and predicting; the corresponding calculation part is also implemented here.curvefitting_assessor.pyis the assessor which receives the trial history and assess whether to early stop the trial.
TODO¶
- Further improve the accuracy of the prediction and test it on more models.
Introduction to NNI Training Services¶
Training Service¶
What is Training Service?¶
NNI training service is designed to allow users to focus on AutoML itself, agnostic to the underlying computing infrastructure where the trials are actually run. When migrating from one cluster to another (e.g., local machine to Kubeflow), users only need to tweak several configurations, and the experiment can be easily scaled.
Users can use training service provided by NNI, to run trial jobs on local machine, remote machines, and on clusters like PAI, Kubeflow and FrameworkController. These are called built-in training services.
If the computing resource customers try to use is not listed above, NNI provides interface that allows users to build their own training service easily. Please refer to “how to implement training service” for details.
How to use Training Service?¶
Training service needs to be chosen and configured properly in experiment configuration YAML file. Users could refer to the document of each training service for how to write the configuration. Also, reference provides more details on the specification of the experiment configuration file.
Next, users should prepare code directory, which is specified as codeDir in config file. Please note that in non-local mode, the code directory will be uploaded to remote or cluster before the experiment. Therefore, we limit the number of files to 2000 and total size to 300MB. If the code directory contains too many files, users can choose which files and subfolders should be excluded by adding a .nniignore file that works like a .gitignore file. For more details on how to write this file, see this example and the git documentation.
In case users intend to use large files in their experiment (like large-scaled datasets) and they are not using local mode, they can either: 1) download the data before each trial launches by putting it into trial command; or 2) use a shared storage that is accessible to worker nodes. Usually, training platforms are equipped with shared storage, and NNI allows users to easily use them. Refer to docs of each built-in training service for details.
Built-in Training Services¶
| TrainingService | Brief Introduction |
|---|---|
| Local | NNI supports running an experiment on local machine, called local mode. Local mode means that NNI will run the trial jobs and nniManager process in same machine, and support gpu schedule function for trial jobs. |
| Remote | NNI supports running an experiment on multiple machines through SSH channel, called remote mode. NNI assumes that you have access to those machines, and already setup the environment for running deep learning training code. NNI will submit the trial jobs in remote machine, and schedule suitable machine with enough gpu resource if specified. |
| PAI | NNI supports running an experiment on OpenPAI (aka PAI), called PAI mode. Before starting to use NNI PAI mode, you should have an account to access an OpenPAI cluster. See here if you don't have any OpenPAI account and want to deploy an OpenPAI cluster. In PAI mode, your trial program will run in PAI's container created by Docker. |
| Kubeflow | NNI supports running experiment on Kubeflow, called kubeflow mode. Before starting to use NNI kubeflow mode, you should have a Kubernetes cluster, either on-premises or Azure Kubernetes Service(AKS), a Ubuntu machine on which kubeconfig is setup to connect to your Kubernetes cluster. If you are not familiar with Kubernetes, here is a good start. In kubeflow mode, your trial program will run as Kubeflow job in Kubernetes cluster. |
| FrameworkController | NNI supports running experiment using FrameworkController, called frameworkcontroller mode. FrameworkController is built to orchestrate all kinds of applications on Kubernetes, you don't need to install Kubeflow for specific deep learning framework like tf-operator or pytorch-operator. Now you can use FrameworkController as the training service to run NNI experiment. |
| DLTS | NNI supports running experiment using DLTS, which is an open source toolkit, developed by Microsoft, that allows AI scientists to spin up an AI cluster in turn-key fashion. |
What does Training Service do?¶
According to the architecture shown in Overview, training service (platform) is actually responsible for two events: 1) initiating a new trial; 2) collecting metrics and communicating with NNI core (NNI manager); 3) monitoring trial job status. To demonstrated in detail how training service works, we show the workflow of training service from the very beginning to the moment when first trial succeeds.
Step 1. Validate config and prepare the training platform. Training service will first check whether the training platform user specifies is valid (e.g., is there anything wrong with authentication). After that, training service will start to prepare for the experiment by making the code directory (codeDir) accessible to training platform.
Note
Different training services have different ways to handle codeDir. For example, local training service directly runs trials in codeDir. Remote training service packs codeDir into a zip and uploads it to each machine. K8S-based training services copy codeDir onto a shared storage, which is either provided by training platform itself, or configured by users in config file.
Step 2. Submit the first trial. To initiate a trial, usually (in non-reuse mode), NNI copies another few files (including parameters, launch script and etc.) onto training platform. After that, NNI launches the trial through subprocess, SSH, RESTful API, and etc.
Warning
The working directory of trial command has exactly the same content as codeDir, but can have a differen path (even on differen machines) Local mode is the only training service that shares one codeDir across all trials. Other training services copies a codeDir from the shared copy prepared in step 1 and each trial has an independent working directory. We strongly advise users not to rely on the shared behavior in local mode, as it will make your experiments difficult to scale to other training services.
Step 3. Collect metrics. NNI then monitors the status of trial, updates the status (e.g., from WAITING to RUNNING, RUNNING to SUCCEEDED) recorded, and also collects the metrics. Currently, most training services are implemented in an “active” way, i.e., training service will call the RESTful API on NNI manager to update the metrics. Note that this usually requires the machine that runs NNI manager to be at least accessible to the worker node.
Tutorial: Create and Run an Experiment on local with NNI API¶
In this tutorial, we will use the example in [~/examples/trials/mnist-tfv1] to explain how to create and run an experiment on local with NNI API.
Before starts
You have an implementation for MNIST classifer using convolutional layers, the Python code is in mnist_before.py.
Step 1 - Update model codes
To enable NNI API, make the following changes:
1.1 Declare NNI API
Include `import nni` in your trial code to use NNI APIs.
1.2 Get predefined parameters
Use the following code snippet:
RECEIVED_PARAMS = nni.get_next_parameter()
to get hyper-parameters' values assigned by tuner. `RECEIVED_PARAMS` is an object, for example:
{"conv_size": 2, "hidden_size": 124, "learning_rate": 0.0307, "dropout_rate": 0.2029}
1.3 Report NNI results
Use the API:
`nni.report_intermediate_result(accuracy)`
to send `accuracy` to assessor.
Use the API:
`nni.report_final_result(accuracy)`
to send `accuracy` to tuner.
We had made the changes and saved it to mnist.py.
NOTE:
accuracy - The `accuracy` could be any python object, but if you use NNI built-in tuner/assessor, `accuracy` should be a numerical variable (e.g. float, int).
assessor - The assessor will decide which trial should early stop based on the history performance of trial (intermediate result of one trial).
tuner - The tuner will generate next parameters/architecture based on the explore history (final result of all trials).
Step 2 - Define SearchSpace
The hyper-parameters used in Step 1.2 - Get predefined parameters is defined in a search_space.json file like below:
{
"dropout_rate":{"_type":"uniform","_value":[0.1,0.5]},
"conv_size":{"_type":"choice","_value":[2,3,5,7]},
"hidden_size":{"_type":"choice","_value":[124, 512, 1024]},
"learning_rate":{"_type":"uniform","_value":[0.0001, 0.1]}
}
Refer to define search space to learn more about search space.
Step 3 - Define Experiment
3.1 enable NNI API mode
To enable NNI API mode, you need to set useAnnotation to false and provide the path of SearchSpace file (you just defined in step 1):
useAnnotation: false
searchSpacePath: /path/to/your/search_space.json
To run an experiment in NNI, you only needed:
- Provide a runnable trial
- Provide or choose a tuner
- Provide a YAML experiment configure file
- (optional) Provide or choose an assessor
Prepare trial:
A set of examples can be found in ~/nni/examples after your installation, runls ~/nni/examples/trialsto see all the trial examples.
Let’s use a simple trial example, e.g. mnist, provided by NNI. After you installed NNI, NNI examples have been put in ~/nni/examples, run ls ~/nni/examples/trials to see all the trial examples. You can simply execute the following command to run the NNI mnist example:
python ~/nni/examples/trials/mnist-annotation/mnist.py
This command will be filled in the YAML configure file below. Please refer to here for how to write your own trial.
Prepare tuner: NNI supports several popular automl algorithms, including Random Search, Tree of Parzen Estimators (TPE), Evolution algorithm etc. Users can write their own tuner (refer to here), but for simplicity, here we choose a tuner provided by NNI as below:
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
builtinTunerName is used to specify a tuner in NNI, classArgs are the arguments pass to the tuner (the spec of builtin tuners can be found here), optimization_mode is to indicate whether you want to maximize or minimize your trial’s result.
Prepare configure file: Since you have already known which trial code you are going to run and which tuner you are going to use, it is time to prepare the YAML configure file. NNI provides a demo configure file for each trial example, cat ~/nni/examples/trials/mnist-annotation/config.yml to see it. Its content is basically shown below:
authorName: your_name
experimentName: auto_mnist
# how many trials could be concurrently running
trialConcurrency: 1
# maximum experiment running duration
maxExecDuration: 3h
# empty means never stop
maxTrialNum: 100
# choice: local, remote
trainingServicePlatform: local
# search space file
searchSpacePath: search_space.json
# choice: true, false
useAnnotation: true
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
trial:
command: python mnist.py
codeDir: ~/nni/examples/trials/mnist-annotation
gpuNum: 0
Here useAnnotation is true because this trial example uses our python annotation (refer to here for details). For trial, we should provide trialCommand which is the command to run the trial, provide trialCodeDir where the trial code is. The command will be executed in this directory. We should also provide how many GPUs a trial requires.
With all these steps done, we can run the experiment with the following command:
nnictl create --config ~/nni/examples/trials/mnist-annotation/config.yml
You can refer to here for more usage guide of nnictl command line tool.
View experiment results¶
The experiment has been running now. Other than nnictl, NNI also provides WebUI for you to view experiment progress, to control your experiment, and some other appealing features.
Using multiple local GPUs to speed up search¶
The following steps assume that you have 4 NVIDIA GPUs installed at local and tensorflow with GPU support. The demo enables 4 concurrent trail jobs and each trail job uses 1 GPU.
Prepare configure file: NNI provides a demo configuration file for the setting above, cat ~/nni/examples/trials/mnist-annotation/config_gpu.yml to see it. The trailConcurrency and gpuNum are different from the basic configure file:
...
# how many trials could be concurrently running
trialConcurrency: 4
...
trial:
command: python mnist.py
codeDir: ~/nni/examples/trials/mnist-annotation
gpuNum: 1
We can run the experiment with the following command:
nnictl create --config ~/nni/examples/trials/mnist-annotation/config_gpu.yml
You can use nnictl command line tool or WebUI to trace the training progress. nvidia_smi command line tool can also help you to monitor the GPU usage during training.
Run an Experiment on Remote Machines¶
NNI can run one experiment on multiple remote machines through SSH, called remote mode. It’s like a lightweight training platform. In this mode, NNI can be started from your computer, and dispatch trials to remote machines in parallel.
The OS of remote machines supports Linux, Windows 10, and Windows Server 2019.
Requirements¶
- Make sure the default environment of remote machines meets requirements of your trial code. If the default environment does not meet the requirements, the setup script can be added into
commandfield of NNI config. - Make sure remote machines can be accessed through SSH from the machine which runs
nnictlcommand. It supports both password and key authentication of SSH. For advanced usages, please refer to machineList part of configuration. - Make sure the NNI version on each machine is consistent.
- Make sure the command of Trial is compatible with remote OSes, if you want to use remote Linux and Windows together. For example, the default python 3.x executable called
python3on Linux, andpythonon Windows.
Linux¶
- Follow installation to install NNI on the remote machine.
Windows¶
Follow installation to install NNI on the remote machine.
Install and start
OpenSSH Server.- Open
Settingsapp on Windows. - Click
Apps, then clickOptional features. - Click
Add a feature, search and selectOpenSSH Server, and then clickInstall. - Once it’s installed, run below command to start and set to automatic start.
sc config sshd start=auto net start sshd
- Open
Make sure remote account is administrator, so that it can stop running trials.
Make sure there is no welcome message more than default, since it causes ssh2 failed in NodeJs. For example, if you’re using Data Science VM on Azure, it needs to remove extra echo commands in
C:\dsvm\tools\setup\welcome.bat.The output like below is ok, when opening a new command window.
Microsoft Windows [Version 10.0.17763.1192] (c) 2018 Microsoft Corporation. All rights reserved. (py37_default) C:\Users\AzureUser>
Run an experiment¶
e.g. there are three machines, which can be logged in with username and password.
| IP | Username | Password |
|---|---|---|
| 10.1.1.1 | bob | bob123 |
| 10.1.1.2 | bob | bob123 |
| 10.1.1.3 | bob | bob123 |
Install and run NNI on one of those three machines or another machine, which has network access to them.
Use examples/trials/mnist-annotation as the example. Below is content of examples/trials/mnist-annotation/config_remote.yml:
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai
trainingServicePlatform: remote
# search space file
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: true
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 0
#machineList can be empty if the platform is local
machineList:
- ip: 10.1.1.1
username: bob
passwd: bob123
#port can be skip if using default ssh port 22
#port: 22
- ip: 10.1.1.2
username: bob
passwd: bob123
- ip: 10.1.1.3
username: bob
passwd: bob123
Files in codeDir will be uploaded to remote machines automatically. You can run below command on Windows, Linux, or macOS to spawn trials on remote Linux machines:
nnictl create --config examples/trials/mnist-annotation/config_remote.yml
Run an Experiment on OpenPAI¶
NNI supports running an experiment on OpenPAI, called pai mode. Before starting to use NNI pai mode, you should have an account to access an OpenPAI cluster. See here if you don’t have any OpenPAI account and want to deploy an OpenPAI cluster. In pai mode, your trial program will run in pai’s container created by Docker.
Setup environment¶
Step 1. Install NNI, follow the install guide here.
Step 2. Get token.
Open web portal of OpenPAI, and click My profile button in the top-right side.

Click copy button in the page to copy a jwt token.

Step 3. Mount NFS storage to local machine.
Click Submit job button in web portal.

Find the data management region in job submission page.

The Preview container paths is the NFS host and path that OpenPAI provided, you need to mount the corresponding host and path to your local machine first, then NNI could use the OpenPAI’s NFS storage.For example, use the following command:
sudo mount -t nfs4 gcr-openpai-infra02:/pai/data /local/mnt
Then the /data folder in container will be mounted to /local/mnt folder in your local machine.You could use the following configuration in your NNI’s config file:
nniManagerNFSMountPath: /local/mnt
Step 4. Get OpenPAI’s storage config name and nniManagerMountPath
The Team share storage field is storage configuration used to specify storage value in OpenPAI. You can get paiStorageConfigName and containerNFSMountPath field in Team share storage, for example:
paiStorageConfigName: confignfs-data
containerNFSMountPath: /mnt/confignfs-data
Run an experiment¶
Use examples/trials/mnist-annotation as an example. The NNI config YAML file’s content is like:
authorName: your_name
experimentName: auto_mnist
# how many trials could be concurrently running
trialConcurrency: 2
# maximum experiment running duration
maxExecDuration: 3h
# empty means never stop
maxTrialNum: 100
# choice: local, remote, pai
trainingServicePlatform: pai
# search space file
searchSpacePath: search_space.json
# choice: true, false
useAnnotation: true
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: ~/nni/examples/trials/mnist-annotation
gpuNum: 0
cpuNum: 1
memoryMB: 8196
image: msranni/nni:latest
virtualCluster: default
nniManagerNFSMountPath: /home/user/mnt
containerNFSMountPath: /mnt/data/user
paiStorageConfigName: confignfs-data
# Configuration to access OpenPAI Cluster
paiConfig:
userName: your_pai_nni_user
token: your_pai_token
host: 10.1.1.1
# optional, experimental feature.
reuse: true
Note: You should set trainingServicePlatform: pai in NNI config YAML file if you want to start experiment in pai mode.
Trial configurations¶
Compared with LocalMode and RemoteMachineMode, trial configuration in pai mode have these additional keys:
cpuNum
Optional key. Should be positive number based on your trial program’s CPU requirement. If it is not set in trial configuration, it should be set in the config file specified in
paiConfigPathfield.memoryMB
Optional key. Should be positive number based on your trial program’s memory requirement. If it is not set in trial configuration, it should be set in the config file specified in
paiConfigPathfield.image
Optional key. In pai mode, your trial program will be scheduled by OpenPAI to run in Docker container. This key is used to specify the Docker image used to create the container in which your trial will run.
We already build a docker image nnimsra/nni on Docker Hub. It contains NNI python packages, Node modules and javascript artifact files required to start experiment, and all of NNI dependencies. The docker file used to build this image can be found at here. You can either use this image directly in your config file, or build your own image based on it. If it is not set in trial configuration, it should be set in the config file specified in
paiConfigPathfield.virtualCluster
Optional key. Set the virtualCluster of OpenPAI. If omitted, the job will run on default virtual cluster.
nniManagerNFSMountPath
Required key. Set the mount path in your nniManager machine.
containerNFSMountPath
Required key. Set the mount path in your container used in OpenPAI.
paiStorageConfigName:
Optional key. Set the storage name used in OpenPAI. If it is not set in trial configuration, it should be set in the config file specified in
paiConfigPathfield.command
Optional key. Set the commands used in OpenPAI container.
paiConfigPath Optional key. Set the file path of OpenPAI job configuration, the file is in yaml format.
If users set
paiConfigPathin NNI’s configuration file, no need to specify the fieldscommand,paiStorageConfigName,virtualCluster,image,memoryMB,cpuNum,gpuNumintrialconfiguration. These fields will use the values from the config file specified bypaiConfigPath.Note:
- The job name in OpenPAI’s configuration file will be replaced by a new job name, the new job name is created by NNI, the name format is nni_exp_${this.experimentId}trial${trialJobId}.
- If users set multiple taskRoles in OpenPAI’s configuration file, NNI will wrap all of these taksRoles and start multiple tasks in one trial job, users should ensure that only one taskRole report metric to NNI, otherwise there might be some conflict error.
OpenPAI configurations¶
paiConfig includes OpenPAI specific configurations,
userName
Required key. User name of OpenPAI platform.
token
Required key. Authentication key of OpenPAI platform.
host
Required key. The host of OpenPAI platform. It’s OpenPAI’s job submission page uri, like
10.10.5.1, the default http protocol in NNI ishttp, if your OpenPAI cluster enabled https, please use the uri inhttps://10.10.5.1format.reuse (experimental feature)
Optional key, default is false. If it’s true, NNI will reuse OpenPAI jobs to run as many as possible trials. It can save time of creating new jobs. User needs to make sure each trial can run independent in same job, for example, avoid loading checkpoint from previous trials.
Once complete to fill NNI experiment config file and save (for example, save as exp_pai.yml), then run the following command
nnictl create --config exp_pai.yml
to start the experiment in pai mode. NNI will create OpenPAI job for each trial, and the job name format is something like nni_exp_{experiment_id}_trial_{trial_id}.
You can see jobs created by NNI in the OpenPAI cluster’s web portal, like:

Notice: In pai mode, NNIManager will start a rest server and listen on a port which is your NNI WebUI’s port plus 1. For example, if your WebUI port is 8080, the rest server will listen on 8081, to receive metrics from trial job running in Kubernetes. So you should enable 8081 TCP port in your firewall rule to allow incoming traffic.
Once a trial job is completed, you can goto NNI WebUI’s overview page (like http://localhost:8080/oview) to check trial’s information.
Expand a trial information in trial list view, click the logPath link like:

And you will be redirected to HDFS web portal to browse the output files of that trial in HDFS:

You can see there’re three fils in output folder: stderr, stdout, and trial.log
data management¶
Before using NNI to start your experiment, users should set the corresponding mount data path in your nniManager machine. OpenPAI has their own storage(NFS, AzureBlob …), and the storage will used in OpenPAI will be mounted to the container when it start a job. Users should set the OpenPAI storage type by paiStorageConfigName field to choose a storage in OpenPAI. Then users should mount the storage to their nniManager machine, and set the nniManagerNFSMountPath field in configuration file, NNI will generate bash files and copy data in codeDir to the nniManagerNFSMountPath folder, then NNI will start a trial job. The data in nniManagerNFSMountPath will be sync to OpenPAI storage, and will be mounted to OpenPAI’s container. The data path in container is set in containerNFSMountPath, NNI will enter this folder first, and then run scripts to start a trial job.
version check¶
NNI support version check feature in since version 0.6. It is a policy to insure the version of NNIManager is consistent with trialKeeper, and avoid errors caused by version incompatibility. Check policy:
- NNIManager before v0.6 could run any version of trialKeeper, trialKeeper support backward compatibility.
- Since version 0.6, NNIManager version should keep same with triakKeeper version. For example, if NNIManager version is 0.6, trialKeeper version should be 0.6 too.
- Note that the version check feature only check first two digits of version.For example, NNIManager v0.6.1 could use trialKeeper v0.6 or trialKeeper v0.6.2, but could not use trialKeeper v0.5.1 or trialKeeper v0.7.
If you could not run your experiment and want to know if it is caused by version check, you could check your webUI, and there will be an error message about version check.

Run an Experiment on OpenpaiYarn¶
The original pai mode is modificated to paiYarn mode, which is a distributed training platform based on Yarn.
Run an experiment¶
Use examples/trials/mnist-tfv1 as an example. The NNI config YAML file’s content is like:
authorName: your_name
experimentName: auto_mnist
# how many trials could be concurrently running
trialConcurrency: 2
# maximum experiment running duration
maxExecDuration: 3h
# empty means never stop
maxTrialNum: 100
# choice: local, remote, pai, paiYarn
trainingServicePlatform: paiYarn
# search space file
searchSpacePath: search_space.json
# choice: true, false
useAnnotation: false
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: ~/nni/examples/trials/mnist-tfv1
gpuNum: 0
cpuNum: 1
memoryMB: 8196
image: msranni/nni:latest
# Configuration to access OpenpaiYarn Cluster
paiYarnConfig:
userName: your_paiYarn_nni_user
passWord: your_paiYarn_password
host: 10.1.1.1
Note: You should set trainingServicePlatform: paiYarn in NNI config YAML file if you want to start experiment in paiYarn mode.
Compared with LocalMode and RemoteMachineMode, trial configuration in paiYarn mode have these additional keys:
cpuNum
- Required key. Should be positive number based on your trial program’s CPU requirement
memoryMB
- Required key. Should be positive number based on your trial program’s memory requirement
image
- Required key. In paiYarn mode, your trial program will be scheduled by OpenpaiYarn to run in Docker container. This key is used to specify the Docker image used to create the container in which your trial will run.
- We already build a docker image nnimsra/nni on Docker Hub. It contains NNI python packages, Node modules and javascript artifact files required to start experiment, and all of NNI dependencies. The docker file used to build this image can be found at here. You can either use this image directly in your config file, or build your own image based on it.
virtualCluster
- Optional key. Set the virtualCluster of OpenpaiYarn. If omitted, the job will run on default virtual cluster.
shmMB
- Optional key. Set the shmMB configuration of OpenpaiYarn, it set the shared memory for one task in the task role.
authFile
- Optional key, Set the auth file path for private registry while using paiYarn mode, Refer, you can prepare the authFile and simply provide the local path of this file, NNI will upload this file to HDFS for you.
portList
- Optional key. Set the portList configuration of OpenpaiYarn, it specifies a list of port used in container, Refer.The config schema in NNI is shown below:
portList: - label: test beginAt: 8080 portNumber: 2
Let’s say you want to launch a tensorboard in the mnist example using the port. So the first step is to write a wrapper script
launch_paiYarn.shofmnist.py.export TENSORBOARD_PORT=paiYarn_PORT_LIST_${paiYarn_CURRENT_TASK_ROLE_NAME}_0_tensorboard tensorboard --logdir . --port ${!TENSORBOARD_PORT} & python3 mnist.py
The config file of portList should be filled as following:
trial: command: bash launch_paiYarn.sh portList: - label: tensorboard beginAt: 0 portNumber: 1
NNI support two kind of authorization method in paiYarn, including password and paiYarn token, refer. The authorization is configured in paiYarnConfig field.For password authorization, the paiYarnConfig schema is:
paiYarnConfig:
userName: your_paiYarn_nni_user
passWord: your_paiYarn_password
host: 10.1.1.1
For paiYarn token authorization, the paiYarnConfig schema is:
paiYarnConfig:
userName: your_paiYarn_nni_user
token: your_paiYarn_token
host: 10.1.1.1
Once complete to fill NNI experiment config file and save (for example, save as exp_paiYarn.yml), then run the following command
nnictl create --config exp_paiYarn.yml
to start the experiment in paiYarn mode. NNI will create OpenpaiYarn job for each trial, and the job name format is something like nni_exp_{experiment_id}_trial_{trial_id}.
You can see jobs created by NNI in the OpenpaiYarn cluster’s web portal, like:
Notice: In paiYarn mode, NNIManager will start a rest server and listen on a port which is your NNI WebUI’s port plus 1. For example, if your WebUI port is 8080, the rest server will listen on 8081, to receive metrics from trial job running in Kubernetes. So you should enable 8081 TCP port in your firewall rule to allow incoming traffic.
Once a trial job is completed, you can goto NNI WebUI’s overview page (like http://localhost:8080/oview) to check trial’s information.
Expand a trial information in trial list view, click the logPath link like:
And you will be redirected to HDFS web portal to browse the output files of that trial in HDFS:
You can see there’re three fils in output folder: stderr, stdout, and trial.log
data management¶
If your training data is not too large, it could be put into codeDir, and nni will upload the data to hdfs, or you could build your own docker image with the data. If you have large dataset, it’s not appropriate to put the data in codeDir, and you could follow the guidance to mount the data folder in container.
If you also want to save trial’s other output into HDFS, like model files, you can use environment variable NNI_OUTPUT_DIR in your trial code to save your own output files, and NNI SDK will copy all the files in NNI_OUTPUT_DIR from trial’s container to HDFS, the target path is hdfs://host:port/{username}/nni/{experiments}/{experimentId}/trials/{trialId}/nnioutput
version check¶
NNI support version check feature in since version 0.6. It is a policy to insure the version of NNIManager is consistent with trialKeeper, and avoid errors caused by version incompatibility. Check policy:
- NNIManager before v0.6 could run any version of trialKeeper, trialKeeper support backward compatibility.
- Since version 0.6, NNIManager version should keep same with triakKeeper version. For example, if NNIManager version is 0.6, trialKeeper version should be 0.6 too.
- Note that the version check feature only check first two digits of version.For example, NNIManager v0.6.1 could use trialKeeper v0.6 or trialKeeper v0.6.2, but could not use trialKeeper v0.5.1 or trialKeeper v0.7.
If you could not run your experiment and want to know if it is caused by version check, you could check your webUI, and there will be an error message about version check.
Run an Experiment on Kubeflow¶
===
Now NNI supports running experiment on Kubeflow, called kubeflow mode. Before starting to use NNI kubeflow mode, you should have a Kubernetes cluster, either on-premises or Azure Kubernetes Service(AKS), a Ubuntu machine on which kubeconfig is setup to connect to your Kubernetes cluster. If you are not familiar with Kubernetes, here is a good start. In kubeflow mode, your trial program will run as Kubeflow job in Kubernetes cluster.
Prerequisite for on-premises Kubernetes Service¶
A Kubernetes cluster using Kubernetes 1.8 or later. Follow this guideline to set up Kubernetes
Download, set up, and deploy Kubeflow to your Kubernetes cluster. Follow this guideline to setup Kubeflow.
Prepare a kubeconfig file, which will be used by NNI to interact with your Kubernetes API server. By default, NNI manager will use $(HOME)/.kube/config as kubeconfig file’s path. You can also specify other kubeconfig files by setting the KUBECONFIG environment variable. Refer this guideline to learn more about kubeconfig.
If your NNI trial job needs GPU resource, you should follow this guideline to configure Nvidia device plugin for Kubernetes.
Prepare a NFS server and export a general purpose mount (we recommend to map your NFS server path in
root_squash option, otherwise permission issue may raise when NNI copy files to NFS. Refer this page to learn what root_squash option is), or Azure File Storage.Install NFS client on the machine where you install NNI and run nnictl to create experiment. Run this command to install NFSv4 client:
apt-get install nfs-common
Install NNI, follow the install guide here.
Prerequisite for Azure Kubernetes Service¶
- NNI support Kubeflow based on Azure Kubernetes Service, follow the guideline to set up Azure Kubernetes Service.
- Install Azure CLI and kubectl. Use
az loginto set azure account, and connect kubectl client to AKS, refer this guideline. - Deploy Kubeflow on Azure Kubernetes Service, follow the guideline.
- Follow the guideline to create azure file storage account. If you use Azure Kubernetes Service, NNI need Azure Storage Service to store code files and the output files.
- To access Azure storage service, NNI need the access key of the storage account, and NNI use Azure Key Vault Service to protect your private key. Set up Azure Key Vault Service, add a secret to Key Vault to store the access key of Azure storage account. Follow this guideline to store the access key.
Design¶
 Kubeflow training service instantiates a Kubernetes rest client to interact with your K8s cluster’s API server.
Kubeflow training service instantiates a Kubernetes rest client to interact with your K8s cluster’s API server.
For each trial, we will upload all the files in your local codeDir path (configured in nni_config.yml) together with NNI generated files like parameter.cfg into a storage volumn. Right now we support two kinds of storage volumes: nfs and azure file storage, you should configure the storage volumn in NNI config YAML file. After files are prepared, Kubeflow training service will call K8S rest API to create Kubeflow jobs (tf-operator job or pytorch-operator job) in K8S, and mount your storage volume into the job’s pod. Output files of Kubeflow job, like stdout, stderr, trial.log or model files, will also be copied back to the storage volumn. NNI will show the storage volumn’s URL for each trial in WebUI, to allow user browse the log files and job’s output files.
Supported operator¶
NNI only support tf-operator and pytorch-operator of Kubeflow, other operators is not tested. Users could set operator type in config file. The setting of tf-operator:
kubeflowConfig:
operator: tf-operator
The setting of pytorch-operator:
kubeflowConfig:
operator: pytorch-operator
If users want to use tf-operator, he could set ps and worker in trial config. If users want to use pytorch-operator, he could set master and worker in trial config.
Supported storage type¶
NNI support NFS and Azure Storage to store the code and output files, users could set storage type in config file and set the corresponding config.
The setting for NFS storage are as follows:
kubeflowConfig:
storage: nfs
nfs:
# Your NFS server IP, like 10.10.10.10
server: {your_nfs_server_ip}
# Your NFS server export path, like /var/nfs/nni
path: {your_nfs_server_export_path}
If you use Azure storage, you should set kubeflowConfig in your config YAML file as follows:
kubeflowConfig:
storage: azureStorage
keyVault:
vaultName: {your_vault_name}
name: {your_secert_name}
azureStorage:
accountName: {your_storage_account_name}
azureShare: {your_azure_share_name}
Run an experiment¶
Use examples/trials/mnist-tfv1 as an example. This is a tensorflow job, and use tf-operator of Kubeflow. The NNI config YAML file’s content is like:
authorName: default
experimentName: example_mnist
trialConcurrency: 2
maxExecDuration: 1h
maxTrialNum: 20
#choice: local, remote, pai, kubeflow
trainingServicePlatform: kubeflow
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
assessor:
builtinAssessorName: Medianstop
classArgs:
optimize_mode: maximize
gpuNum: 0
trial:
codeDir: .
worker:
replicas: 2
command: python3 dist_mnist.py
gpuNum: 1
cpuNum: 1
memoryMB: 8196
image: msranni/nni:latest
ps:
replicas: 1
command: python3 dist_mnist.py
gpuNum: 0
cpuNum: 1
memoryMB: 8196
image: msranni/nni:latest
kubeflowConfig:
operator: tf-operator
apiVersion: v1alpha2
storage: nfs
nfs:
# Your NFS server IP, like 10.10.10.10
server: {your_nfs_server_ip}
# Your NFS server export path, like /var/nfs/nni
path: {your_nfs_server_export_path}
Note: You should explicitly set trainingServicePlatform: kubeflow in NNI config YAML file if you want to start experiment in kubeflow mode.
If you want to run PyTorch jobs, you could set your config files as follow:
authorName: default
experimentName: example_mnist_distributed_pytorch
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai, kubeflow
trainingServicePlatform: kubeflow
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: minimize
trial:
codeDir: .
master:
replicas: 1
command: python3 dist_mnist.py
gpuNum: 1
cpuNum: 1
memoryMB: 2048
image: msranni/nni:latest
worker:
replicas: 1
command: python3 dist_mnist.py
gpuNum: 0
cpuNum: 1
memoryMB: 2048
image: msranni/nni:latest
kubeflowConfig:
operator: pytorch-operator
apiVersion: v1alpha2
nfs:
# Your NFS server IP, like 10.10.10.10
server: {your_nfs_server_ip}
# Your NFS server export path, like /var/nfs/nni
path: {your_nfs_server_export_path}
Trial configuration in kubeflow mode have the following configuration keys:
- codeDir
- code directory, where you put training code and config files
- worker (required). This config section is used to configure tensorflow worker role
- replicas
- Required key. Should be positive number depends on how many replication your want to run for tensorflow worker role.
- command
- Required key. Command to launch your trial job, like
python mnist.py
- Required key. Command to launch your trial job, like
- memoryMB
- Required key. Should be positive number based on your trial program’s memory requirement
- cpuNum
- gpuNum
- image
- Required key. In kubeflow mode, your trial program will be scheduled by Kubernetes to run in Pod. This key is used to specify the Docker image used to create the pod where your trail program will run.
- We already build a docker image msranni/nni on Docker Hub. It contains NNI python packages, Node modules and javascript artifact files required to start experiment, and all of NNI dependencies. The docker file used to build this image can be found at here. You can either use this image directly in your config file, or build your own image based on it.
- privateRegistryAuthPath
- Optional field, specify
config.jsonfile path that holds an authorization token of docker registry, used to pull image from private registry. Refer.
- Optional field, specify
- apiVersion
- Required key. The API version of your Kubeflow.
- replicas
- ps (optional). This config section is used to configure Tensorflow parameter server role.
- master(optional). This config section is used to configure PyTorch parameter server role.
Once complete to fill NNI experiment config file and save (for example, save as exp_kubeflow.yml), then run the following command
nnictl create --config exp_kubeflow.yml
to start the experiment in kubeflow mode. NNI will create Kubeflow tfjob or pytorchjob for each trial, and the job name format is something like nni_exp_{experiment_id}_trial_{trial_id}.
You can see the Kubeflow tfjob created by NNI in your Kubernetes dashboard.
Notice: In kubeflow mode, NNIManager will start a rest server and listen on a port which is your NNI WebUI’s port plus 1. For example, if your WebUI port is 8080, the rest server will listen on 8081, to receive metrics from trial job running in Kubernetes. So you should enable 8081 TCP port in your firewall rule to allow incoming traffic.
Once a trial job is completed, you can go to NNI WebUI’s overview page (like http://localhost:8080/oview) to check trial’s information.
version check¶
NNI support version check feature in since version 0.6, refer
Any problems when using NNI in Kubeflow mode, please create issues on NNI Github repo.
Run an Experiment on FrameworkController¶
=== NNI supports running experiment using FrameworkController, called frameworkcontroller mode. FrameworkController is built to orchestrate all kinds of applications on Kubernetes, you don’t need to install Kubeflow for specific deep learning framework like tf-operator or pytorch-operator. Now you can use FrameworkController as the training service to run NNI experiment.
Prerequisite for on-premises Kubernetes Service¶
A Kubernetes cluster using Kubernetes 1.8 or later. Follow this guideline to set up Kubernetes
Prepare a kubeconfig file, which will be used by NNI to interact with your Kubernetes API server. By default, NNI manager will use $(HOME)/.kube/config as kubeconfig file’s path. You can also specify other kubeconfig files by setting the KUBECONFIG environment variable. Refer this guideline to learn more about kubeconfig.
If your NNI trial job needs GPU resource, you should follow this guideline to configure Nvidia device plugin for Kubernetes.
Prepare a NFS server and export a general purpose mount (we recommend to map your NFS server path in
root_squash option, otherwise permission issue may raise when NNI copies files to NFS. Refer this page to learn what root_squash option is), or Azure File Storage.Install NFS client on the machine where you install NNI and run nnictl to create experiment. Run this command to install NFSv4 client:
apt-get install nfs-common
Install NNI, follow the install guide here.
Prerequisite for Azure Kubernetes Service¶
- NNI support Kubeflow based on Azure Kubernetes Service, follow the guideline to set up Azure Kubernetes Service.
- Install Azure CLI and kubectl. Use
az loginto set azure account, and connect kubectl client to AKS, refer this guideline. - Follow the guideline to create azure file storage account. If you use Azure Kubernetes Service, NNI need Azure Storage Service to store code files and the output files.
- To access Azure storage service, NNI need the access key of the storage account, and NNI uses Azure Key Vault Service to protect your private key. Set up Azure Key Vault Service, add a secret to Key Vault to store the access key of Azure storage account. Follow this guideline to store the access key.
Setup FrameworkController¶
Follow the guideline to set up FrameworkController in the Kubernetes cluster, NNI supports FrameworkController by the stateful set mode. If your cluster enforces authorization, you need to create a service account with granted permission for FrameworkController, and then pass the name of the FrameworkController service account to the NNI Experiment Config. refer
Design¶
Please refer the design of Kubeflow training service, FrameworkController training service pipeline is similar.
Example¶
The FrameworkController config file format is:
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 10h
maxTrialNum: 100
#choice: local, remote, pai, kubeflow, frameworkcontroller
trainingServicePlatform: frameworkcontroller
searchSpacePath: ~/nni/examples/trials/mnist-tfv1/search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
assessor:
builtinAssessorName: Medianstop
classArgs:
optimize_mode: maximize
gpuNum: 0
trial:
codeDir: ~/nni/examples/trials/mnist-tfv1
taskRoles:
- name: worker
taskNum: 1
command: python3 mnist.py
gpuNum: 1
cpuNum: 1
memoryMB: 8192
image: msranni/nni:latest
frameworkAttemptCompletionPolicy:
minFailedTaskCount: 1
minSucceededTaskCount: 1
frameworkcontrollerConfig:
storage: nfs
nfs:
server: {your_nfs_server}
path: {your_nfs_server_exported_path}
If you use Azure Kubernetes Service, you should set frameworkcontrollerConfig in your config YAML file as follows:
frameworkcontrollerConfig:
storage: azureStorage
serviceAccountName: {your_frameworkcontroller_service_account_name}
keyVault:
vaultName: {your_vault_name}
name: {your_secert_name}
azureStorage:
accountName: {your_storage_account_name}
azureShare: {your_azure_share_name}
Note: You should explicitly set trainingServicePlatform: frameworkcontroller in NNI config YAML file if you want to start experiment in frameworkcontrollerConfig mode.
The trial’s config format for NNI frameworkcontroller mode is a simple version of FrameworkController’s official config, you could refer the Tensorflow example of FrameworkController for deep understanding.
Trial configuration in frameworkcontroller mode have the following configuration keys:
- taskRoles: you could set multiple task roles in config file, and each task role is a basic unit to process in Kubernetes cluster.
- name: the name of task role specified, like “worker”, “ps”, “master”.
- taskNum: the replica number of the task role.
- command: the users’ command to be used in the container.
- gpuNum: the number of gpu device used in container.
- cpuNum: the number of cpu device used in container.
- memoryMB: the memory limitaion to be specified in container.
- image: the docker image used to create pod and run the program.
- frameworkAttemptCompletionPolicy: the policy to run framework, please refer the user-manual to get the specific information. Users could use the policy to control the pod, for example, if ps does not stop, only worker stops, The completion policy could helps stop ps.
Run an Experiment on DLTS¶
NNI supports running an experiment on DLTS, called dlts mode. Before starting to use NNI dlts mode, you should have an account to access DLTS dashboard.
Setup Environment¶
Step 1. Choose a cluster from DLTS dashboard, ask administrator for the cluster dashboard URL.
 Choose Cluster
Choose Cluster
Step 2. Prepare a NNI config YAML like the following:
# Set this field to "dlts"
trainingServicePlatform: dlts
authorName: your_name
experimentName: auto_mnist
trialConcurrency: 2
maxExecDuration: 3h
maxTrialNum: 100
searchSpacePath: search_space.json
useAnnotation: false
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 1
image: msranni/nni
# Configuration to access DLTS
dltsConfig:
dashboard: # Ask administrator for the cluster dashboard URL
Remember to fill the cluster dashboard URL to the last line.
Step 3. Open your working directory of the cluster, paste the NNI config as well as related code to a directory.
 Copy Config
Copy Config
Step 4. Submit a NNI manager job to the specified cluster.
 Submit Job
Submit Job
Step 5. Go to Endpoints tab of the newly created job, click the Port 40000 link to check trial’s information.
 View NNI WebUI
View NNI WebUI
Run an Experiment on Azure Machine Learning¶
NNI supports running an experiment on AML , called aml mode.
Setup environment¶
Step 1. Install NNI, follow the install guide here.
Step 2. Create an Azure account/subscription using this link. If you already have an Azure account/subscription, skip this step.
Step 3. Install the Azure CLI on your machine, follow the install guide here.
Step 4. Authenticate to your Azure subscription from the CLI. To authenticate interactively, open a command line or terminal and use the following command:
az login
Step 5. Log into your Azure account with a web browser and create a Machine Learning resource. You will need to choose a resource group and specific a workspace name. Then download config.json which will be used later.

Step 6. Create an AML cluster as the computeTarget.

Step 7. Open a command line and install AML package environment.
python3 -m pip install azureml --user
python3 -m pip install azureml-sdk --user
Run an experiment¶
Use examples/trials/mnist-tfv1 as an example. The NNI config YAML file’s content is like:
authorName: default
experimentName: example_mnist
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
trainingServicePlatform: aml
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner, MetisTuner, GPTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
computeTarget: ${replace_to_your_computeTarget}
image: msranni/nni
amlConfig:
subscriptionId: ${replace_to_your_subscriptionId}
resourceGroup: ${replace_to_your_resourceGroup}
workspaceName: ${replace_to_your_workspaceName}
Note: You should set trainingServicePlatform: aml in NNI config YAML file if you want to start experiment in aml mode.
Compared with LocalMode trial configuration in aml mode have these additional keys:
- computeTarget
- required key. The compute cluster name you want to use in your AML workspace. See Step 6.
- image
- required key. The docker image name used in job. The image
msranni/nniof this example only support GPU computeTargets.
- required key. The docker image name used in job. The image
amlConfig:
- subscriptionId
- the subscriptionId of your account
- resourceGroup
- the resourceGroup of your account
- workspaceName
- the workspaceName of your account
The required information of amlConfig could be found in the downloaded config.json in Step 5.
Run the following commands to start the example experiment:
git clone -b ${NNI_VERSION} https://github.com/microsoft/nni
cd nni/examples/trials/mnist-tfv1
# modify config_aml.yml ...
nnictl create --config config_aml.yml
Replace ${NNI_VERSION} with a released version name or branch name, e.g., v1.7.
Examples¶
MNIST examples¶
CNN MNIST classifier for deep learning is similar to hello world for programming languages. Thus, we use MNIST as example to introduce different features of NNI. The examples are listed below:
- MNIST with NNI API (TensorFlow v1.x)
- MNIST with NNI API (TensorFlow v2.x)
- MNIST with NNI annotation
- MNIST in keras
- MNIST – tuning with batch tuner
- MNIST – tuning with hyperband
- MNIST – tuning within a nested search space
- distributed MNIST (tensorflow) using kubeflow
- distributed MNIST (pytorch) using kubeflow
MNIST with NNI API (TensorFlow v1.x)
This is a simple network which has two convolutional layers, two pooling layers and a fully connected layer. We tune hyperparameters, such as dropout rate, convolution size, hidden size, etc. It can be tuned with most NNI built-in tuners, such as TPE, SMAC, Random. We also provide an exmaple YAML file which enables assessor.
code directory: examples/trials/mnist-tfv1/
MNIST with NNI API (TensorFlow v2.x)
Same network to the example above, but written in TensorFlow v2.x Keras API.
code directory: examples/trials/mnist-tfv2/
This example is similar to the example above, the only difference is that this example uses NNI annotation to specify search space and report results, while the example above uses NNI apis to receive configuration and report results.
code directory: examples/trials/mnist-annotation/
This example is implemented in keras. It is also a network for MNIST dataset, with two convolution layers, one pooling layer, and two fully connected layers.
code directory: examples/trials/mnist-keras/
MNIST – tuning with batch tuner
This example is to show how to use batch tuner. Users simply list all the configurations they want to try in the search space file. NNI will try all of them.
code directory: examples/trials/mnist-batch-tune-keras/
This example is to show how to use hyperband to tune the model. There is one more key STEPS in the received configuration for trials to control how long it can run (e.g., number of iterations).
code directory: examples/trials/mnist-hyperband/
MNIST – tuning within a nested search space
This example is to show that NNI also support nested search space. The search space file is an example of how to define nested search space.
code directory: examples/trials/mnist-nested-search-space/
distributed MNIST (tensorflow) using kubeflow
This example is to show how to run distributed training on kubeflow through NNI. Users can simply provide distributed training code and a configure file which specifies the kubeflow mode. For example, what is the command to run ps and what is the command to run worker, and how many resources they consume. This example is implemented in tensorflow, thus, uses kubeflow tensorflow operator.
code directory: examples/trials/mnist-distributed/
distributed MNIST (pytorch) using kubeflow
Similar to the previous example, the difference is that this example is implemented in pytorch, thus, it uses kubeflow pytorch operator.
code directory: examples/trials/mnist-distributed-pytorch/
CIFAR-10 examples¶
Overview¶
CIFAR-10 classification is a common benchmark problem in machine learning. The CIFAR-10 dataset is the collection of images. It is one of the most widely used datasets for machine learning research which contains 60,000 32x32 color images in 10 different classes. Thus, we use CIFAR-10 classification as an example to introduce NNI usage.
Goals¶
As we all know, the choice of model optimizer is directly affects the performance of the final metrics. The goal of this tutorial is to tune a better performace optimizer to train a relatively small convolutional neural network (CNN) for recognizing images.
In this example, we have selected the following common deep learning optimizer:
“SGD”, “Adadelta”, “Adagrad”, “Adam”, “Adamax”
Experimental¶
This example requires PyTorch. PyTorch install package should be chosen based on python version and cuda version.
Here is an example of the environment python==3.5 and cuda == 8.0, then using the following commands to install PyTorch:
python3 -m pip install http://download.pytorch.org/whl/cu80/torch-0.4.1-cp35-cp35m-linux_x86_64.whl
python3 -m pip install torchvision
Search Space
As we stated in the target, we target to find out the best optimizer for training CIFAR-10 classification. When using different optimizers, we also need to adjust learning rates and network structure accordingly. so we chose these three parameters as hyperparameters and write the following search space.
{
"lr":{"_type":"choice", "_value":[0.1, 0.01, 0.001, 0.0001]},
"optimizer":{"_type":"choice", "_value":["SGD", "Adadelta", "Adagrad", "Adam", "Adamax"]},
"model":{"_type":"choice", "_value":["vgg", "resnet18", "googlenet", "densenet121", "mobilenet", "dpn92", "senet18"]}
}
Implemented code directory: search_space.json
Trial
The code for CNN training of each hyperparameters set, paying particular attention to the following points are specific for NNI:
- Use
nni.get_next_parameter()to get next training hyperparameter set. - Use
nni.report_intermediate_result(acc)to report the intermedian result after finish each epoch. - Use
nni.report_final_result(acc)to report the final result before the trial end.
Implemented code directory: main.py
You can also use your previous code directly, refer to How to define a trial for modify.
Config
Here is the example of running this experiment on local(with multiple GPUs):
code directory: examples/trials/cifar10_pytorch/config.yml
Here is the example of running this experiment on OpenPAI:
code directory: examples/trials/cifar10_pytorch/config_pai.yml
The complete examples we have implemented: examples/trials/cifar10_pytorch/
We are ready for the experiment, let’s now run the config.yml file from your command line to start the experiment.
nnictl create --config nni/examples/trials/cifar10_pytorch/config.yml
Scikit-learn in NNI¶
Scikit-learn is a popular machine learning tool for data mining and data analysis. It supports many kinds of machine learning models like LinearRegression, LogisticRegression, DecisionTree, SVM etc. How to make the use of scikit-learn more efficiency is a valuable topic.
NNI supports many kinds of tuning algorithms to search the best models and/or hyper-parameters for scikit-learn, and support many kinds of environments like local machine, remote servers and cloud.
1. How to run the example¶
To start using NNI, you should install the NNI package, and use the command line tool nnictl to start an experiment. For more information about installation and preparing for the environment, please refer here.
After you installed NNI, you could enter the corresponding folder and start the experiment using following commands:
nnictl create --config ./config.yml
2. Description of the example¶
2.1 classification¶
This example uses the dataset of digits, which is made up of 1797 8x8 images, and each image is a hand-written digit, the goal is to classify these images into 10 classes.
In this example, we use SVC as the model, and choose some parameters of this model, including "C", "kernel", "degree", "gamma" and "coef0". For more information of these parameters, please refer.
2.2 regression¶
This example uses the Boston Housing Dataset, this dataset consists of price of houses in various places in Boston and the information such as Crime (CRIM), areas of non-retail business in the town (INDUS), the age of people who own the house (AGE) etc., to predict the house price of Boston.
In this example, we tune different kinds of regression models including "LinearRegression", "SVR", "KNeighborsRegressor", "DecisionTreeRegressor" and some parameters like "svr_kernel", "knr_weights". You could get more details about these models from here.
3. How to write scikit-learn code using NNI¶
It is easy to use NNI in your scikit-learn code, there are only a few steps.
step 1
Prepare a search_space.json to storage your choose spaces. For example, if you want to choose different models, you may try:
{ "model_name":{"_type":"choice","_value":["LinearRegression", "SVR", "KNeighborsRegressor", "DecisionTreeRegressor"]} }
If you want to choose different models and parameters, you could put them together in a search_space.json file.
{ "model_name":{"_type":"choice","_value":["LinearRegression", "SVR", "KNeighborsRegressor", "DecisionTreeRegressor"]}, "svr_kernel": {"_type":"choice","_value":["linear", "poly", "rbf"]}, "knr_weights": {"_type":"choice","_value":["uniform", "distance"]} }
Then you could read these values as a dict from your python code, please get into the step 2.
step 2
At the beginning of your python code, you should
import nnito insure the packages works normally.First, you should use
nni.get_next_parameter()function to get your parameters given by NNI. Then you could use these parameters to update your code. For example, if you define your search_space.json like following format:{ "C": {"_type":"uniform","_value":[0.1, 1]}, "kernel": {"_type":"choice","_value":["linear", "rbf", "poly", "sigmoid"]}, "degree": {"_type":"choice","_value":[1, 2, 3, 4]}, "gamma": {"_type":"uniform","_value":[0.01, 0.1]}, "coef0 ": {"_type":"uniform","_value":[0.01, 0.1]} }
You may get a parameter dict like this:
params = { 'C': 1.0, 'kernel': 'linear', 'degree': 3, 'gamma': 0.01, 'coef0': 0.01 }
Then you could use these variables to write your scikit-learn code.
step 3
After you finished your training, you could get your own score of the model, like your precision, recall or MSE etc. NNI needs your score to tuner algorithms and generate next group of parameters, please report the score back to NNI and start next trial job.
You just need to use
nni.report_final_result(score)to communicate with NNI after you process your scikit-learn code. Or if you have multiple scores in the steps of training, you could also report them back to NNI usingnni.report_intemediate_result(score). Note, you may not report intermediate result of your job, but you must report back your final result.
Automatic Model Architecture Search for Reading Comprehension¶
This example shows us how to use Genetic Algorithm to find good model architectures for Reading Comprehension.
1. Search Space¶
Since attention and RNN have been proven effective in Reading Comprehension, we conclude the search space as follow:
- IDENTITY (Effectively means keep training).
- INSERT-RNN-LAYER (Inserts a LSTM. Comparing the performance of GRU and LSTM in our experiment, we decided to use LSTM here.)
- REMOVE-RNN-LAYER
- INSERT-ATTENTION-LAYER(Inserts an attention layer.)
- REMOVE-ATTENTION-LAYER
- ADD-SKIP (Identity between random layers).
- REMOVE-SKIP (Removes random skip).

New version¶
Also we have another version which time cost is less and performance is better. We will release soon.
2. How to run this example in local?¶
2.1 Use downloading script to download data¶
Execute the following command to download needed files using the downloading script:
chmod +x ./download.sh
./download.sh
Or Download manually
- download “dev-v1.1.json” and “train-v1.1.json” in https://rajpurkar.github.io/SQuAD-explorer/
wget https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
wget https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
- download “glove.840B.300d.txt” in https://nlp.stanford.edu/projects/glove/
wget http://nlp.stanford.edu/data/glove.840B.300d.zip
unzip glove.840B.300d.zip
2.2 Update configuration¶
Modify nni/examples/trials/ga_squad/config.yml, here is the default configuration:
authorName: default
experimentName: example_ga_squad
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 1
#choice: local, remote
trainingServicePlatform: local
#choice: true, false
useAnnotation: false
tuner:
codeDir: ~/nni/examples/tuners/ga_customer_tuner
classFileName: customer_tuner.py
className: CustomerTuner
classArgs:
optimize_mode: maximize
trial:
command: python3 trial.py
codeDir: ~/nni/examples/trials/ga_squad
gpuNum: 0
In the “trial” part, if you want to use GPU to perform the architecture search, change gpuNum from 0 to 1. You need to increase the maxTrialNum and maxExecDuration, according to how long you want to wait for the search result.
2.3 submit this job¶
nnictl create --config ~/nni/examples/trials/ga_squad/config.yml
3 Run this example on OpenPAI¶
Due to the memory limitation of upload, we only upload the source code and complete the data download and training on OpenPAI. This experiment requires sufficient memory that memoryMB >= 32G, and the training may last for several hours.
3.1 Update configuration¶
Modify nni/examples/trials/ga_squad/config_pai.yml, here is the default configuration:
authorName: default
experimentName: example_ga_squad
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai
trainingServicePlatform: pai
#choice: true, false
useAnnotation: false
#Your nni_manager ip
nniManagerIp: 10.10.10.10
tuner:
codeDir: https://github.com/Microsoft/nni/tree/master/examples/tuners/ga_customer_tuner
classFileName: customer_tuner.py
className: CustomerTuner
classArgs:
optimize_mode: maximize
trial:
command: chmod +x ./download.sh && ./download.sh && python3 trial.py
codeDir: .
gpuNum: 0
cpuNum: 1
memoryMB: 32869
#The docker image to run nni job on OpenPAI
image: msranni/nni:latest
paiConfig:
#The username to login OpenPAI
userName: username
#The password to login OpenPAI
passWord: password
#The host of restful server of OpenPAI
host: 10.10.10.10
Please change the default value to your personal account and machine information. Including nniManagerIp, userName, passWord and host.
In the “trial” part, if you want to use GPU to perform the architecture search, change gpuNum from 0 to 1. You need to increase the maxTrialNum and maxExecDuration, according to how long you want to wait for the search result.
trialConcurrency is the number of trials running concurrently, which is the number of GPUs you want to use, if you are setting gpuNum to 1.
3.2 submit this job¶
nnictl create --config ~/nni/examples/trials/ga_squad/config_pai.yml
4. Technical details about the trial¶
4.1 How does it works¶
The evolution-algorithm based architecture for question answering has two different parts just like any other examples: the trial and the tuner.
4.2 The trial¶
The trial has a lot of different files, functions and classes. Here we will only give most of those files a brief introduction:
attention.pycontains an implementation for attention mechanism in Tensorflow.data.pycontains functions for data preprocessing.evaluate.pycontains the evaluation script.graph.pycontains the definition of the computation graph.rnn.pycontains an implementation for GRU in Tensorflow.train_model.pyis a wrapper for the whole question answering model.
Among those files, trial.py and graph_to_tf.py are special.
graph_to_tf.py has a function named as graph_to_network, here is its skeleton code:
def graph_to_network(input1,
input2,
input1_lengths,
input2_lengths,
graph,
dropout_rate,
is_training,
num_heads=1,
rnn_units=256):
topology = graph.is_topology()
layers = dict()
layers_sequence_lengths = dict()
num_units = input1.get_shape().as_list()[-1]
layers[0] = input1*tf.sqrt(tf.cast(num_units, tf.float32)) + \
positional_encoding(input1, scale=False, zero_pad=False)
layers[1] = input2*tf.sqrt(tf.cast(num_units, tf.float32))
layers[0] = dropout(layers[0], dropout_rate, is_training)
layers[1] = dropout(layers[1], dropout_rate, is_training)
layers_sequence_lengths[0] = input1_lengths
layers_sequence_lengths[1] = input2_lengths
for _, topo_i in enumerate(topology):
if topo_i == '|':
continue
if graph.layers[topo_i].graph_type == LayerType.input.value:
# ......
elif graph.layers[topo_i].graph_type == LayerType.attention.value:
# ......
# More layers to handle
As we can see, this function is actually a compiler, that converts the internal model DAG configuration (which will be introduced in the Model configuration format section) graph, to a Tensorflow computation graph.
topology = graph.is_topology()
performs topological sorting on the internal graph representation, and the code inside the loop:
for _, topo_i in enumerate(topology):
performs actually conversion that maps each layer to a part in Tensorflow computation graph.
4.3 The tuner¶
The tuner is much more simple than the trial. They actually share the same graph.py. Besides, the tuner has a customer_tuner.py, the most important class in which is CustomerTuner:
class CustomerTuner(Tuner):
# ......
def generate_parameters(self, parameter_id):
"""Returns a set of trial graph config, as a serializable object.
parameter_id : int
"""
if len(self.population) <= 0:
logger.debug("the len of poplution lower than zero.")
raise Exception('The population is empty')
pos = -1
for i in range(len(self.population)):
if self.population[i].result == None:
pos = i
break
if pos != -1:
indiv = copy.deepcopy(self.population[pos])
self.population.pop(pos)
temp = json.loads(graph_dumps(indiv.config))
else:
random.shuffle(self.population)
if self.population[0].result > self.population[1].result:
self.population[0] = self.population[1]
indiv = copy.deepcopy(self.population[0])
self.population.pop(1)
indiv.mutation()
graph = indiv.config
temp = json.loads(graph_dumps(graph))
# ......
As we can see, the overloaded method generate_parameters implements a pretty naive mutation algorithm. The code lines:
if self.population[0].result > self.population[1].result:
self.population[0] = self.population[1]
indiv = copy.deepcopy(self.population[0])
controls the mutation process. It will always take two random individuals in the population, only keeping and mutating the one with better result.
4.4 Model configuration format¶
Here is an example of the model configuration, which is passed from the tuner to the trial in the architecture search procedure.
{
"max_layer_num": 50,
"layers": [
{
"input_size": 0,
"type": 3,
"output_size": 1,
"input": [],
"size": "x",
"output": [4, 5],
"is_delete": false
},
{
"input_size": 0,
"type": 3,
"output_size": 1,
"input": [],
"size": "y",
"output": [4, 5],
"is_delete": false
},
{
"input_size": 1,
"type": 4,
"output_size": 0,
"input": [6],
"size": "x",
"output": [],
"is_delete": false
},
{
"input_size": 1,
"type": 4,
"output_size": 0,
"input": [5],
"size": "y",
"output": [],
"is_delete": false
},
{"Comment": "More layers will be here for actual graphs."}
]
}
Every model configuration will have a “layers” section, which is a JSON list of layer definitions. The definition of each layer is also a JSON object, where:
typeis the type of the layer. 0, 1, 2, 3, 4 corresponds to attention, self-attention, RNN, input and output layer respectively.sizeis the length of the output. “x”, “y” correspond to document length / question length, respectively.input_sizeis the number of inputs the layer has.inputis the indices of layers taken as input of this layer.outputis the indices of layers use this layer’s output as their input.is_deletemeans whether the layer is still available.
GBDT in nni¶
Gradient boosting is a machine learning technique for regression and classification problems, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees. It builds the model in a stage-wise fashion as other boosting methods do, and it generalizes them by allowing optimization of an arbitrary differentiable loss function.
Gradient boosting decision tree has many popular implementations, such as lightgbm, xgboost, and catboost, etc. GBDT is a great tool for solving the problem of traditional machine learning problem. Since GBDT is a robust algorithm, it could use in many domains. The better hyper-parameters for GBDT, the better performance you could achieve.
NNI is a great platform for tuning hyper-parameters, you could try various builtin search algorithm in nni and run multiple trials concurrently.
1. Search Space in GBDT¶
There are many hyper-parameters in GBDT, but what kind of parameters will affect the performance or speed? Based on some practical experience, some suggestion here(Take lightgbm as example):
- For better accuracy
learning_rate. The range oflearning ratecould be [0.001, 0.9].num_leaves.num_leavesis related tomax_depth, you don’t have to tune both of them.bagging_freq.bagging_freqcould be [1, 2, 4, 8, 10]num_iterations. May larger if underfitting.
- For speed up
bagging_fraction. The range ofbagging_fractioncould be [0.7, 1.0].feature_fraction. The range offeature_fractioncould be [0.6, 1.0].max_bin.
- To avoid overfitting
min_data_in_leaf. This depends on your dataset.min_sum_hessian_in_leaf. This depend on your dataset.lambda_l1andlambda_l2.min_gain_to_split.num_leaves.
Reference link: lightgbm and autoxgoboost
2. Task description¶
Now we come back to our example “auto-gbdt” which run in lightgbm and nni. The data including train data and test data. Given the features and label in train data, we train a GBDT regression model and use it to predict.
3. How to run in nni¶
3.1 Install all the requirments¶
pip install lightgbm
pip install pandas
3.2 Prepare your trial code¶
You need to prepare a basic code as following:
...
def get_default_parameters():
...
return params
def load_data(train_path='./data/regression.train', test_path='./data/regression.test'):
'''
Load or create dataset
'''
...
return lgb_train, lgb_eval, X_test, y_test
def run(lgb_train, lgb_eval, params, X_test, y_test):
# train
gbm = lgb.train(params,
lgb_train,
num_boost_round=20,
valid_sets=lgb_eval,
early_stopping_rounds=5)
# predict
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# eval
rmse = mean_squared_error(y_test, y_pred) ** 0.5
print('The rmse of prediction is:', rmse)
if __name__ == '__main__':
lgb_train, lgb_eval, X_test, y_test = load_data()
PARAMS = get_default_parameters()
# train
run(lgb_train, lgb_eval, PARAMS, X_test, y_test)
3.3 Prepare your search space.¶
If you like to tune num_leaves, learning_rate, bagging_fraction and bagging_freq, you could write a search_space.json as follow:
{
"num_leaves":{"_type":"choice","_value":[31, 28, 24, 20]},
"learning_rate":{"_type":"choice","_value":[0.01, 0.05, 0.1, 0.2]},
"bagging_fraction":{"_type":"uniform","_value":[0.7, 1.0]},
"bagging_freq":{"_type":"choice","_value":[1, 2, 4, 8, 10]}
}
More support variable type you could reference here.
3.4 Add SDK of nni into your code.¶
+import nni
...
def get_default_parameters():
...
return params
def load_data(train_path='./data/regression.train', test_path='./data/regression.test'):
'''
Load or create dataset
'''
...
return lgb_train, lgb_eval, X_test, y_test
def run(lgb_train, lgb_eval, params, X_test, y_test):
# train
gbm = lgb.train(params,
lgb_train,
num_boost_round=20,
valid_sets=lgb_eval,
early_stopping_rounds=5)
# predict
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# eval
rmse = mean_squared_error(y_test, y_pred) ** 0.5
print('The rmse of prediction is:', rmse)
+ nni.report_final_result(rmse)
if __name__ == '__main__':
lgb_train, lgb_eval, X_test, y_test = load_data()
+ RECEIVED_PARAMS = nni.get_next_parameter()
PARAMS = get_default_parameters()
+ PARAMS.update(RECEIVED_PARAMS)
# train
run(lgb_train, lgb_eval, PARAMS, X_test, y_test)
3.5 Write a config file and run it.¶
In the config file, you could set some settings including:
- Experiment setting:
trialConcurrency,maxExecDuration,maxTrialNum,trial gpuNum, etc. - Platform setting:
trainingServicePlatform, etc. - Path seeting:
searchSpacePath,trial codeDir, etc. - Algorithm setting: select
tuneralgorithm,tuner optimize_mode, etc.
An config.yml as follow:
authorName: default
experimentName: example_auto-gbdt
trialConcurrency: 1
maxExecDuration: 10h
maxTrialNum: 10
#choice: local, remote, pai
trainingServicePlatform: local
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: minimize
trial:
command: python3 main.py
codeDir: .
gpuNum: 0
Run this experiment with command as follow:
nnictl create --config ./config.yml
Tuning RocksDB on NNI¶
Overview¶
RocksDB is a popular high performance embedded key-value database used in production systems at various web-scale enterprises including Facebook, Yahoo!, and LinkedIn.. It is a fork of LevelDB by Facebook optimized to exploit many central processing unit (CPU) cores, and make efficient use of fast storage, such as solid-state drives (SSD), for input/output (I/O) bound workloads.
The performance of RocksDB is highly contingent on its tuning. However, because of the complexity of its underlying technology and a large number of configurable parameters, a good configuration is sometimes hard to obtain. NNI can help to address this issue. NNI supports many kinds of tuning algorithms to search the best configuration of RocksDB, and support many kinds of environments like local machine, remote servers and cloud.
This example illustrates how to use NNI to search the best configuration of RocksDB for a fillrandom benchmark supported by a benchmark tool db_bench, which is an official benchmark tool provided by RocksDB itself. Therefore, before running this example, please make sure NNI is installed and db_bench is in your PATH. Please refer to here for detailed information about installation and preparing of NNI environment, and here for compiling RocksDB as well as db_bench.
We also provide a simple script db_bench_installation.sh helping to compile and install db_bench as well as its dependencies on Ubuntu. Installing RocksDB on other systems can follow the same procedure.
code directory: example/trials/systems/rocksdb-fillrandom
Experiment setup¶
There are mainly three steps to setup an experiment of tuning systems on NNI. Define search space with a json file, write a benchmark code, and start NNI experiment by passing a config file to NNI manager.
Search Space¶
For simplicity, this example tunes three parameters, write_buffer_size, min_write_buffer_num and level0_file_num_compaction_trigger, for writing 16M keys with 20 Bytes of key size and 100 Bytes of value size randomly, based on writing operations per second (OPS). write_buffer_size sets the size of a single memtable. Once memtable exceeds this size, it is marked immutable and a new one is created. min_write_buffer_num is the minimum number of memtables to be merged before flushing to storage. Once the number of files in level 0 reaches level0_file_num_compaction_trigger, level 0 to level 1 compaction is triggered.
In this example, the search space is specified by a search_space.json file as shown below. Detailed explanation of search space could be found here.
{
"write_buffer_size": {
"_type": "quniform",
"_value": [2097152, 16777216, 1048576]
},
"min_write_buffer_number_to_merge": {
"_type": "quniform",
"_value": [2, 16, 1]
},
"level0_file_num_compaction_trigger": {
"_type": "quniform",
"_value": [2, 16, 1]
}
}
code directory: example/trials/systems/rocksdb-fillrandom/search_space.json
Benchmark code¶
Benchmark code should receive a configuration from NNI manager, and report the corresponding benchmark result back. Following NNI APIs are designed for this purpose. In this example, writing operations per second (OPS) is used as a performance metric. Please refer to here for detailed information.
- Use
nni.get_next_parameter()to get next system configuration. - Use
nni.report_final_result(metric)to report the benchmark result.
code directory: example/trials/systems/rocksdb-fillrandom/main.py
Config file¶
One could start a NNI experiment with a config file. A config file for NNI is a yaml file usually including experiment settings (trialConcurrency, maxExecDuration, maxTrialNum, trial gpuNum, etc.), platform settings (trainingServicePlatform, etc.), path settings (searchSpacePath, trial codeDir, etc.) and tuner settings (tuner, tuner optimize_mode, etc.). Please refer to here for more information.
Here is an example of tuning RocksDB with SMAC algorithm:
code directory: example/trials/systems/rocksdb-fillrandom/config_smac.yml
Here is an example of tuning RocksDB with TPE algorithm:
code directory: example/trials/systems/rocksdb-fillrandom/config_tpe.yml
Other tuners can be easily adopted in the same way. Please refer to here for more information.
Finally, we could enter the example folder and start the experiment using following commands:
# tuning RocksDB with SMAC tuner
nnictl create --config ./config_smac.yml
# tuning RocksDB with TPE tuner
nnictl create --config ./config_tpe.yml
Experiment results¶
We ran these two examples on the same machine with following details:
- 16 * Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
- 465 GB of rotational hard drive with ext4 file system
- 128 GB of RAM
- Kernel version: 4.15.0-58-generic
- NNI version: v1.0-37-g1bd24577
- RocksDB version: 6.4
- RocksDB DEBUG_LEVEL: 0
The detailed experiment results are shown in the below figure. Horizontal axis is sequential order of trials. Vertical axis is the metric, write OPS in this example. Blue dots represent trials for tuning RocksDB with SMAC tuner, and orange dots stand for trials for tuning RocksDB with TPE tuner.
 image
image
Following table lists the best trials and corresponding parameters and metric obtained by the two tuners. Unsurprisingly, both of them found the same optimal configuration for fillrandom benchmark.
| Tuner | Best trial | Best OPS | write_buffer_size | min_write_buffer_number_to_merge | level0_file_num_compaction_trigger |
|---|---|---|---|---|---|
| SMAC | 255 | 779289 | 2097152 | 7.0 | 7.0 |
| TPE | 169 | 761456 | 2097152 | 7.0 | 7.0 |
Tuning Tensor Operators on NNI¶
Overview¶
Abundant applications raise the demands of training and inference deep neural networks (DNNs) efficiently on diverse hardware platforms ranging from cloud servers to embedded devices. Moreover, computational graph-level optimization of deep neural network, like tensor operator fusion, may introduce new tensor operators. Thus, manually optimized tensor operators provided by hardware-specific libraries have limitations in terms of supporting new hardware platforms or supporting new operators, so automatically optimizing tensor operators on diverse hardware platforms is essential for large-scale deployment and application of deep learning technologies in the real-world problems.
Tensor operator optimization is substantially a combinatorial optimization problem. The objective function is the performance of a tensor operator on specific hardware platform, which should be maximized with respect to the hyper-parameters of corresponding device code, such as how to tile a matrix or whether to unroll a loop. Unlike many typical problems of this type, such as travelling salesman problem, the objective function of tensor operator optimization is a black box and expensive to sample. One has to compile a device code with a specific configuration and run it on real hardware to get the corresponding performance metric. Therefore, a desired method for optimizing tensor operators should find the best configuration with as few samples as possible.
The expensive objective function makes solving tensor operator optimization problem with traditional combinatorial optimization methods, for example, simulated annealing and evolutionary algorithms, almost impossible. Although these algorithms inherently support combinatorial search spaces, they do not take sample-efficiency into account, thus thousands of or even more samples are usually needed, which is unacceptable when tuning tensor operators in product environments. On the other hand, sequential model based optimization (SMBO) methods are proved sample-efficient for optimizing black-box functions with continuous search spaces. However, when optimizing ones with combinatorial search spaces, SMBO methods are not as sample-efficient as their continuous counterparts, because there is lack of prior assumptions about the objective functions, such as continuity and differentiability in the case of continuous search spaces. For example, if one could assume an objective function with a continuous search space is infinitely differentiable, a Gaussian process with a radial basis function (RBF) kernel could be used to model the objective function. In this way, a sample provides not only a single value at a point but also the local properties of the objective function in its neighborhood or even global properties, which results in a high sample-efficiency. In contrast, SMBO methods for combinatorial optimization suffer poor sample-efficiency due to the lack of proper prior assumptions and surrogate models which can leverage them.
OpEvo is recently proposed for solving this challenging problem. It efficiently explores the search spaces of tensor operators by introducing a topology-aware mutation operation based on q-random walk distribution to leverage the topological structures over the search spaces. Following this example, you can use OpEvo to tune three representative types of tensor operators selected from two popular neural networks, BERT and AlexNet. Three comparison baselines, AutoTVM, G-BFS and N-A2C, are also provided. Please refer to OpEvo: An Evolutionary Method for Tensor Operator Optimization for detailed explanation about these algorithms.
Environment Setup¶
We prepared a dockerfile for setting up experiment environments. Before starting, please make sure the Docker daemon is running and the driver of your GPU accelerator is properly installed. Enter into the example folder examples/trials/systems/opevo and run below command to build and instantiate a Docker image from the dockerfile.
# if you are using Nvidia GPU
make cuda-env
# if you are using AMD GPU
make rocm-env
Run Experiments:¶
Three representative kinds of tensor operators, matrix multiplication, batched matrix multiplication and 2D convolution, are chosen from BERT and AlexNet, and tuned with NNI. The Trial code for all tensor operators is /root/compiler_auto_tune_stable.py, and Search Space files and config files for each tuning algorithm locate in /root/experiments/, which are categorized by tensor operators. Here /root refers to the root of the container.
For tuning the operators of matrix multiplication, please run below commands from /root:
# (N, K) x (K, M) represents a matrix of shape (N, K) multiplies a matrix of shape (K, M)
# (512, 1024) x (1024, 1024)
# tuning with OpEvo
nnictl create --config experiments/mm/N512K1024M1024/config_opevo.yml
# tuning with G-BFS
nnictl create --config experiments/mm/N512K1024M1024/config_gbfs.yml
# tuning with N-A2C
nnictl create --config experiments/mm/N512K1024M1024/config_na2c.yml
# tuning with AutoTVM
OP=matmul STEP=512 N=512 M=1024 K=1024 P=NN ./run.s
# (512, 1024) x (1024, 4096)
# tuning with OpEvo
nnictl create --config experiments/mm/N512K1024M4096/config_opevo.yml
# tuning with G-BFS
nnictl create --config experiments/mm/N512K1024M4096/config_gbfs.yml
# tuning with N-A2C
nnictl create --config experiments/mm/N512K1024M4096/config_na2c.yml
# tuning with AutoTVM
OP=matmul STEP=512 N=512 M=1024 K=4096 P=NN ./run.sh
# (512, 4096) x (4096, 1024)
# tuning with OpEvo
nnictl create --config experiments/mm/N512K4096M1024/config_opevo.yml
# tuning with G-BFS
nnictl create --config experiments/mm/N512K4096M1024/config_gbfs.yml
# tuning with N-A2C
nnictl create --config experiments/mm/N512K4096M1024/config_na2c.yml
# tuning with AutoTVM
OP=matmul STEP=512 N=512 M=4096 K=1024 P=NN ./run.sh
For tuning the operators of batched matrix multiplication, please run below commands from /root:
# batched matrix with batch size 960 and shape of matrix (128, 128) multiplies batched matrix with batch size 960 and shape of matrix (128, 64)
# tuning with OpEvo
nnictl create --config experiments/bmm/B960N128K128M64PNN/config_opevo.yml
# tuning with AutoTVM
OP=batch_matmul STEP=512 B=960 N=128 K=128 M=64 P=NN ./run.sh
# batched matrix with batch size 960 and shape of matrix (128, 128) is transposed first and then multiplies batched matrix with batch size 960 and shape of matrix (128, 64)
# tuning with OpEvo
nnictl create --config experiments/bmm/B960N128K128M64PTN/config_opevo.yml
# tuning with AutoTVM
OP=batch_matmul STEP=512 B=960 N=128 K=128 M=64 P=TN ./run.sh
# batched matrix with batch size 960 and shape of matrix (128, 64) is transposed first and then right multiplies batched matrix with batch size 960 and shape of matrix (128, 64).
# tuning with OpEvo
nnictl create --config experiments/bmm/B960N128K64M128PNT/config_opevo.yml
# tuning with AutoTVM
OP=batch_matmul STEP=512 B=960 N=128 K=64 M=128 P=NT ./run.sh
For tuning the operators of 2D convolution, please run below commands from /root:
# image tensor of shape (512, 3, 227, 227) convolves with kernel tensor of shape (64, 3, 11, 11) with stride 4 and padding 0
# tuning with OpEvo
nnictl create --config experiments/conv/N512C3HW227F64K11ST4PD0/config_opevo.yml
# tuning with AutoTVM
OP=convfwd_direct STEP=512 N=512 C=3 H=227 W=227 F=64 K=11 ST=4 PD=0 ./run.sh
# image tensor of shape (512, 64, 27, 27) convolves with kernel tensor of shape (192, 64, 5, 5) with stride 1 and padding 2
# tuning with OpEvo
nnictl create --config experiments/conv/N512C64HW27F192K5ST1PD2/config_opevo.yml
# tuning with AutoTVM
OP=convfwd_direct STEP=512 N=512 C=64 H=27 W=27 F=192 K=5 ST=1 PD=2 ./run.sh
Please note that G-BFS and N-A2C are only designed for tuning tiling schemes of multiplication of matrices with only power of 2 rows and columns, so they are not compatible with other types of configuration spaces, thus not eligible to tune the operators of batched matrix multiplication and 2D convolution. Here, AutoTVM is implemented by its authors in the TVM project, so the tuning results are printed on the screen rather than reported to NNI manager. The port 8080 of the container is bind to the host on the same port, so one can access the NNI Web UI through host_ip_addr:8080 and monitor tuning process as below screenshot.

Citing OpEvo¶
If you feel OpEvo is helpful, please consider citing the paper as follows:
@misc{gao2020opevo,
title={OpEvo: An Evolutionary Method for Tensor Operator Optimization},
author={Xiaotian Gao and Cui Wei and Lintao Zhang and Mao Yang},
year={2020},
eprint={2006.05664},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
Knowledge Distillation on NNI Compressor¶
KnowledgeDistill¶
Knowledge distillation support, in Distilling the Knowledge in a Neural Network, the compressed model is trained to mimic a pre-trained, larger model. This training setting is also referred to as “teacher-student”, where the large model is the teacher and the small model is the student.

Usage¶
PyTorch code
from knowledge_distill.knowledge_distill import KnowledgeDistill
kd = KnowledgeDistill(kd_teacher_model, kd_T=5)
alpha = 1
beta = 0.8
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
# you only to add the following line to fine-tune with knowledge distillation
loss = alpha * loss + beta * kd.loss(data=data, student_out=output)
loss.backward()
EfficientNet¶
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
Use Grid search to find the best combination of alpha, beta and gamma for EfficientNet-B1, as discussed in Section 3.3 in paper. Search space, tuner, configuration examples are provided here.
Instructions¶
- Set your working directory here in the example code directory.
- Run
git clone https://github.com/ultmaster/EfficientNet-PyTorchto clone this modified version of EfficientNet-PyTorch. The modifications were done to adhere to the original Tensorflow version as close as possible (including EMA, label smoothing and etc.); also added are the part which gets parameters from tuner and reports intermediate/final results. Clone it intoEfficientNet-PyTorch; the files likemain.py,train_imagenet.shwill appear inside, as specified in the configuration files. - Run
nnictl create --config config_local.yml(useconfig_pai.ymlfor OpenPAI) to find the best EfficientNet-B1. Adjust the training service (PAI/local/remote), batch size in the config files according to the environment.
For training on ImageNet, read EfficientNet-PyTorch/train_imagenet.sh. Download ImageNet beforehand and extract it adhering to PyTorch format and then replace /mnt/data/imagenet in with the location of the ImageNet storage. This file should also be a good example to follow for mounting ImageNet into the container on OpenPAI.
Results¶
The follow image is a screenshot, demonstrating the relationship between acc@1 and alpha, beta, gamma.

WebUI¶
View summary page¶
Click the tab “Overview”.
- On the overview tab, you can see the experiment trial profile/search space and the performance of top trials.


- If your experiment has many trials, you can change the refresh interval here.

- You can review and download the experiment results and nni-manager/dispatcher log files from the “View” button.

- You can click the exclamation point in the error box to see a log message if the experiment’s status is an error.


- You can click “Feedback” to report any questions.
View job default metric¶
- Click the tab “Default Metric” to see the point graph of all trials. Hover to see its specific default metric and search space message.

- Click the switch named “optimization curve” to see the experiment’s optimization curve.

View hyper parameter¶
Click the tab “Hyper Parameter” to see the parallel graph.
- You can select the percentage to see top trials.
- Choose two axis to swap its positions


View Trial Intermediate Result Graph¶
Click the tab “Intermediate Result” to see the line graph.

The trial may have many intermediate results in the training process. In order to see the trend of some trials more clearly, we set a filtering function for the intermediate result graph.
You may find that these trials will get better or worse at an intermediate result. This indicates that it is an important and relevant intermediate result. To take a closer look at the point here, you need to enter its corresponding X-value at #Intermediate. Then input the range of metrics on this intermedia result. In the picture below, we choose the No. 4 intermediate result and set the range of metrics to 0.8-1.

View trials status¶
Click the tab “Trials Detail” to see the status of all trials. Specifically:
- Trial detail: trial’s id, trial’s duration, start time, end time, status, accuracy, and search space file.

- The button named “Add column” can select which column to show on the table. If you run an experiment whose final result is a dict, you can see other keys in the table. You can choose the column “Intermediate count” to watch the trial’s progress.

- If you want to compare some trials, you can select them and then click “Compare” to see the results.


- Support to search for a specific trial by it’s id, status, Trial No. and parameters.

- You can use the button named “Copy as python” to copy the trial’s parameters.

- If you run on the OpenPAI or Kubeflow platform, you can also see the hdfsLog.

- Intermediate Result Graph: you can see the default and other keys in this graph by clicking the operation column button.


- Kill: you can kill a job that status is running.


How to Debug in NNI¶
Overview¶
There are three parts that might have logs in NNI. They are nnimanager, dispatcher and trial. Here we will introduce them succinctly. More information please refer to Overview.
- NNI controller: NNI controller (nnictl) is the nni command-line tool that is used to manage experiments (e.g., start an experiment).
- nnimanager: nnimanager is the core of NNI, whose log is important when the whole experiment fails (e.g., no webUI or training service fails)
- Dispatcher: Dispatcher calls the methods of Tuner and Assessor. Logs of dispatcher are related to the tuner or assessor code.
- Tuner: Tuner is an AutoML algorithm, which generates a new configuration for the next try. A new trial will run with this configuration.
- Assessor: Assessor analyzes trial’s intermediate results (e.g., periodically evaluated accuracy on test dataset) to tell whether this trial can be early stopped or not.
- Trial: Trial code is the code you write to run your experiment, which is an individual attempt at applying a new configuration (e.g., a set of hyperparameter values, a specific nerual architecture).
Where is the log¶
There are three kinds of log in NNI. When creating a new experiment, you can specify log level as debug by adding --debug. Besides, you can set more detailed log level in your configuration file by using
logLevel keyword. Available logLevels are: trace, debug, info, warning, error, fatal.
NNI controller¶
All possible errors that happen when launching an NNI experiment can be found here.
You can use nnictl log stderr to find error information. For more options please refer to NNICTL
Experiment Root Directory¶
Every experiment has a root folder, which is shown on the right-top corner of webUI. Or you could assemble it by replacing the experiment_id with your actual experiment_id in path ~/nni/experiment/experiment_id/ in case of webUI failure. experiment_id could be seen when you run nnictl create ... to create a new experiment.
For flexibility, we also offer alogDiroption in your configuration, which specifies the directory to store all experiments (defaults to~/nni/experiment). Please refer to Configuration for more details.
Under that directory, there is another directory named log, where nnimanager.log and dispatcher.log are placed.
Trial Root Directory¶
Usually in webUI, you can click + in the left of every trial to expand it to see each trial’s log path.
Besides, there is another directory under experiment root directory, named trials, which stores all the trials.
Every trial has a unique id as its directory name. In this directory, a file named stderr records trial error and another named trial.log records this trial’s log.
Different kinds of errors¶
There are different kinds of errors. However, they can be divided into three categories based on their severity. So when nni fails, check each part sequentially.
Generally, if webUI is started successfully, there is a Status in the Overview tab, serving as a possible indicator of what kind of error happens. Otherwise you should check manually.
NNI Fails¶
This is the most serious error. When this happens, the whole experiment fails and no trial will be run. Usually this might be related to some installation problem.
When this happens, you should check nnictl’s error output file stderr (i.e., nnictl log stderr) and then the nnimanager’s log to find if there is any error.
Dispatcher Fails¶
Dispatcher fails. Usually, for some new users of NNI, it means that tuner fails. You could check dispatcher’s log to see what happens to your dispatcher. For built-in tuner, some common errors might be invalid search space (unsupported type of search space or inconsistence between initializing args in configuration file and actual tuner’s __init__ function args).
Take the later situation as an example. If you write a customized tuner who’s __init__ function has an argument called optimize_mode, which you do not provide in your configuration file, NNI will fail to run your tuner so the experiment fails. You can see errors in the webUI like:

Here we can see it is a dispatcher error. So we can check dispatcher’s log, which might look like:
[2019-02-19 19:36:45] DEBUG (nni.main/MainThread) START
[2019-02-19 19:36:47] ERROR (nni.main/MainThread) __init__() missing 1 required positional arguments: 'optimize_mode'
Traceback (most recent call last):
File "/usr/lib/python3.7/site-packages/nni/__main__.py", line 202, in <module>
main()
File "/usr/lib/python3.7/site-packages/nni/__main__.py", line 164, in main
args.tuner_args)
File "/usr/lib/python3.7/site-packages/nni/__main__.py", line 81, in create_customized_class_instance
instance = class_constructor(**class_args)
TypeError: __init__() missing 1 required positional arguments: 'optimize_mode'.
Trial Fails¶
In this situation, NNI can still run and create new trials.
It means your trial code (which is run by NNI) fails. This kind of error is strongly related to your trial code. Please check trial’s log to fix any possible errors shown there.
A common example of this would be run the mnist example without installing tensorflow. Surely there is an Import Error (that is, not installing tensorflow but trying to import it in your trial code) and thus every trial fails.

As it shows, every trial has a log path, where you can find trial’s log and stderr.
In addition to experiment level debug, NNI also provides the capability for debugging a single trial without the need to start the entire experiment. Refer to standalone mode for more information about debug single trial code.
Advanced Features¶
Customize-Tuner¶
Customize Tuner¶
NNI provides state-of-the-art tuning algorithm in builtin-tuners. NNI supports to build a tuner by yourself for tuning demand.
If you want to implement your own tuning algorithm, you can implement a customized Tuner, there are three things to do:
- Inherit the base Tuner class
- Implement receive_trial_result, generate_parameter and update_search_space function
- Configure your customized tuner in experiment YAML config file
Here is an example:
1. Inherit the base Tuner class
from nni.tuner import Tuner
class CustomizedTuner(Tuner):
def __init__(self, ...):
...
2. Implement receive_trial_result, generate_parameter and update_search_space function
from nni.tuner import Tuner
class CustomizedTuner(Tuner):
def __init__(self, ...):
...
def receive_trial_result(self, parameter_id, parameters, value, **kwargs):
'''
Receive trial's final result.
parameter_id: int
parameters: object created by 'generate_parameters()'
value: final metrics of the trial, including default metric
'''
# your code implements here.
...
def generate_parameters(self, parameter_id, **kwargs):
'''
Returns a set of trial (hyper-)parameters, as a serializable object
parameter_id: int
'''
# your code implements here.
return your_parameters
...
def update_search_space(self, search_space):
'''
Tuners are advised to support updating search space at run-time.
If a tuner can only set search space once before generating first hyper-parameters,
it should explicitly document this behaviour.
search_space: JSON object created by experiment owner
'''
# your code implements here.
...
receive_trial_result will receive the parameter_id, parameters, value as parameters input. Also, Tuner will receive the value object are exactly same value that Trial send.
The your_parameters return from generate_parameters function, will be package as json object by NNI SDK. NNI SDK will unpack json object so the Trial will receive the exact same your_parameters from Tuner.
For example:
If the you implement the generate_parameters like this:
def generate_parameters(self, parameter_id, **kwargs):
'''
Returns a set of trial (hyper-)parameters, as a serializable object
parameter_id: int
'''
# your code implements here.
return {"dropout": 0.3, "learning_rate": 0.4}
It means your Tuner will always generate parameters {"dropout": 0.3, "learning_rate": 0.4}. Then Trial will receive {"dropout": 0.3, "learning_rate": 0.4} by calling API nni.get_next_parameter(). Once the trial ends with a result (normally some kind of metrics), it can send the result to Tuner by calling API nni.report_final_result(), for example nni.report_final_result(0.93). Then your Tuner’s receive_trial_result function will receied the result like:
parameter_id = 82347
parameters = {"dropout": 0.3, "learning_rate": 0.4}
value = 0.93
Note that The working directory of your tuner is <home>/nni/experiments/<experiment_id>/log, which can be retrieved with environment variable NNI_LOG_DIRECTORY, therefore, if you want to access a file (e.g., data.txt) in the directory of your own tuner, you cannot use open('data.txt', 'r'). Instead, you should use the following:
_pwd = os.path.dirname(__file__)
_fd = open(os.path.join(_pwd, 'data.txt'), 'r')
This is because your tuner is not executed in the directory of your tuner (i.e., pwd is not the directory of your own tuner).
3. Configure your customized tuner in experiment YAML config file
NNI needs to locate your customized tuner class and instantiate the class, so you need to specify the location of the customized tuner class and pass literal values as parameters to the __init__ constructor.
tuner:
codeDir: /home/abc/mytuner
classFileName: my_customized_tuner.py
className: CustomizedTuner
# Any parameter need to pass to your tuner class __init__ constructor
# can be specified in this optional classArgs field, for example
classArgs:
arg1: value1
More detail example you could see:
Write a more advanced automl algorithm¶
The methods above are usually enough to write a general tuner. However, users may also want more methods, for example, intermediate results, trials’ state (e.g., the methods in assessor), in order to have a more powerful automl algorithm. Therefore, we have another concept called advisor which directly inherits from MsgDispatcherBase in src/sdk/pynni/nni/msg_dispatcher_base.py. Please refer to here for how to write a customized advisor.
Customize Assessor¶
NNI supports to build an assessor by yourself for tuning demand.
If you want to implement a customized Assessor, there are three things to do:
- Inherit the base Assessor class
- Implement assess_trial function
- Configure your customized Assessor in experiment YAML config file
1. Inherit the base Assessor class
from nni.assessor import Assessor
class CustomizedAssessor(Assessor):
def __init__(self, ...):
...
2. Implement assess trial function
from nni.assessor import Assessor, AssessResult
class CustomizedAssessor(Assessor):
def __init__(self, ...):
...
def assess_trial(self, trial_history):
"""
Determines whether a trial should be killed. Must override.
trial_history: a list of intermediate result objects.
Returns AssessResult.Good or AssessResult.Bad.
"""
# you code implement here.
...
3. Configure your customized Assessor in experiment YAML config file
NNI needs to locate your customized Assessor class and instantiate the class, so you need to specify the location of the customized Assessor class and pass literal values as parameters to the __init__ constructor.
assessor:
codeDir: /home/abc/myassessor
classFileName: my_customized_assessor.py
className: CustomizedAssessor
# Any parameter need to pass to your Assessor class __init__ constructor
# can be specified in this optional classArgs field, for example
classArgs:
arg1: value1
Please noted in 2. The object trial_history are exact the object that Trial send to Assessor by using SDK report_intermediate_result function.
The working directory of your assessor is <home>/nni/experiments/<experiment_id>/log, which can be retrieved with environment variable NNI_LOG_DIRECTORY,
More detail example you could see:
How To - Customize Your Own Advisor¶
Warning: API is subject to change in future releases.
Advisor targets the scenario that the automl algorithm wants the methods of both tuner and assessor. Advisor is similar to tuner on that it receives trial parameters request, final results, and generate trial parameters. Also, it is similar to assessor on that it receives intermediate results, trial’s end state, and could send trial kill command. Note that, if you use Advisor, tuner and assessor are not allowed to be used at the same time.
If a user want to implement a customized Advisor, she/he only needs to:
1. Define an Advisor inheriting from the MsgDispatcherBase class. For example:
from nni.msg_dispatcher_base import MsgDispatcherBase
class CustomizedAdvisor(MsgDispatcherBase):
def __init__(self, ...):
...
2. Implement the methods with prefix handle_ except handle_request.. You might find docs for MsgDispatcherBase helpful.
3. Configure your customized Advisor in experiment YAML config file.
Similar to tuner and assessor. NNI needs to locate your customized Advisor class and instantiate the class, so you need to specify the location of the customized Advisor class and pass literal values as parameters to the __init__ constructor.
advisor:
codeDir: /home/abc/myadvisor
classFileName: my_customized_advisor.py
className: CustomizedAdvisor
# Any parameter need to pass to your advisor class __init__ constructor
# can be specified in this optional classArgs field, for example
classArgs:
arg1: value1
Note that The working directory of your advisor is <home>/nni/experiments/<experiment_id>/log, which can be retrieved with environment variable NNI_LOG_DIRECTORY.
How to Implement Training Service in NNI¶
Overview¶
TrainingService is a module related to platform management and job schedule in NNI. TrainingService is designed to be easily implemented, we define an abstract class TrainingService as the parent class of all kinds of TrainingService, users just need to inherit the parent class and complete their own child class if they want to implement customized TrainingService.
System architecture¶

The brief system architecture of NNI is shown in the picture. NNIManager is the core management module of system, in charge of calling TrainingService to manage trial jobs and the communication between different modules. Dispatcher is a message processing center responsible for message dispatch. TrainingService is a module to manage trial jobs, it communicates with nniManager module, and has different instance according to different training platform. For the time being, NNI supports local platfrom, remote platfrom, PAI platfrom, kubeflow platform and FrameworkController platfrom.
In this document, we introduce the brief design of TrainingService. If users want to add a new TrainingService instance, they just need to complete a child class to implement TrainingService, don’t need to understand the code detail of NNIManager, Dispatcher or other modules.
Folder structure of code¶
NNI’s folder structure is shown below:
nni
|- deployment
|- docs
|- examaples
|- src
| |- nni_manager
| | |- common
| | |- config
| | |- core
| | |- coverage
| | |- dist
| | |- rest_server
| | |- training_service
| | | |- common
| | | |- kubernetes
| | | |- local
| | | |- pai
| | | |- remote_machine
| | | |- test
| |- sdk
| |- webui
|- test
|- tools
| |-nni_annotation
| |-nni_cmd
| |-nni_gpu_tool
| |-nni_trial_tool
nni/src/ folder stores the most source code of NNI. The code in this folder is related to NNIManager, TrainingService, SDK, WebUI and other modules. Users could find the abstract class of TrainingService in nni/src/nni_manager/common/trainingService.ts file, and they should put their own implemented TrainingService in nni/src/nni_manager/training_service folder. If users have implemented their own TrainingService code, they should also supplement the unit test of the code, and place them in nni/src/nni_manager/training_service/test folder.
Function annotation of TrainingService¶
abstract class TrainingService {
public abstract listTrialJobs(): Promise<TrialJobDetail[]>;
public abstract getTrialJob(trialJobId: string): Promise<TrialJobDetail>;
public abstract addTrialJobMetricListener(listener: (metric: TrialJobMetric) => void): void;
public abstract removeTrialJobMetricListener(listener: (metric: TrialJobMetric) => void): void;
public abstract submitTrialJob(form: JobApplicationForm): Promise<TrialJobDetail>;
public abstract updateTrialJob(trialJobId: string, form: JobApplicationForm): Promise<TrialJobDetail>;
public abstract get isMultiPhaseJobSupported(): boolean;
public abstract cancelTrialJob(trialJobId: string, isEarlyStopped?: boolean): Promise<void>;
public abstract setClusterMetadata(key: string, value: string): Promise<void>;
public abstract getClusterMetadata(key: string): Promise<string>;
public abstract cleanUp(): Promise<void>;
public abstract run(): Promise<void>;
}
The parent class of TrainingService has a few abstract functions, users need to inherit the parent class and implement all of these abstract functions.
setClusterMetadata(key: string, value: string)
ClusterMetadata is the data related to platform details, for examples, the ClusterMetadata defined in remote machine server is:
export class RemoteMachineMeta {
public readonly ip : string;
public readonly port : number;
public readonly username : string;
public readonly passwd?: string;
public readonly sshKeyPath?: string;
public readonly passphrase?: string;
public gpuSummary : GPUSummary | undefined;
/* GPU Reservation info, the key is GPU index, the value is the job id which reserves this GPU*/
public gpuReservation : Map<number, string>;
constructor(ip : string, port : number, username : string, passwd : string,
sshKeyPath : string, passphrase : string) {
this.ip = ip;
this.port = port;
this.username = username;
this.passwd = passwd;
this.sshKeyPath = sshKeyPath;
this.passphrase = passphrase;
this.gpuReservation = new Map<number, string>();
}
}
The metadata includes the host address, the username or other configuration related to the platform. Users need to define their own metadata format, and set the metadata instance in this function. This function is called before the experiment is started to set the configuration of remote machines.
getClusterMetadata(key: string)
This function will return the metadata value according to the values, it could be left empty if users don’t need to use it.
submitTrialJob(form: JobApplicationForm)
SubmitTrialJob is a function to submit new trial jobs, users should generate a job instance in TrialJobDetail type. TrialJobDetail is defined as follow:
interface TrialJobDetail {
readonly id: string;
readonly status: TrialJobStatus;
readonly submitTime: number;
readonly startTime?: number;
readonly endTime?: number;
readonly tags?: string[];
readonly url?: string;
readonly workingDirectory: string;
readonly form: JobApplicationForm;
readonly sequenceId: number;
isEarlyStopped?: boolean;
}
According to different kinds of implementation, users could put the job detail into a job queue, and keep fetching the job from the queue and start preparing and running them. Or they could finish preparing and running process in this function, and return job detail after the submit work.
cancelTrialJob(trialJobId: string, isEarlyStopped?: boolean)
If this function is called, the trial started by the platform should be canceled. Different kind of platform has diffenent methods to calcel a running job, this function should be implemented according to specific platform.
updateTrialJob(trialJobId: string, form: JobApplicationForm)
This function is called to update the trial job’s status, trial job’s status should be detected according to different platform, and be updated to RUNNING, SUCCEED, FAILED etc.
getTrialJob(trialJobId: string)
This function returns a trialJob detail instance according to trialJobId.
listTrialJobs()
Users should put all of trial job detail information into a list, and return the list.
addTrialJobMetricListener(listener: (metric: TrialJobMetric) => void)
NNI will hold an EventEmitter to get job metrics, if there is new job metrics detected, the EventEmitter will be triggered. Users should start the EventEmitter in this function.
removeTrialJobMetricListener(listener: (metric: TrialJobMetric) => void)
Close the EventEmitter.
run()
The run() function is a main loop function in TrainingService, users could set a while loop to execute their logic code, and finish executing them when the experiment is stopped.
cleanUp()
This function is called to clean up the environment when a experiment is stopped. Users should do the platform-related cleaning operation in this function.
TrialKeeper tool¶
NNI offers a TrialKeeper tool to help maintaining trial jobs. Users can find the source code in nni/tools/nni_trial_tool. If users want to run trial jobs in cloud platform, this tool will be a fine choice to help keeping trial running in the platform.
The running architecture of TrialKeeper is show as follow:

When users submit a trial job to cloud platform, they should wrap their trial command into TrialKeeper, and start a TrialKeeper process in cloud platform. Notice that TrialKeeper use restful server to communicate with TrainingService, users should start a restful server in local machine to receive metrics sent from TrialKeeper. The source code about restful server could be found in nni/src/nni_manager/training_service/common/clusterJobRestServer.ts.
How to install customized algorithms as builtin tuners, assessors and advisors¶
Overview¶
NNI provides a lot of builtin tuners, advisors and assessors can be used directly for Hyper Parameter Optimization, and some extra algorithms can be installed via nnictl package install --name <name> after NNI is installed. You can check these extra algorithms via nnictl package list command.
NNI also provides the ability to build your own customized tuners, advisors and assessors. To use the customized algorithm, users can simply follow the spec in experiment config file to properly reference the algorithm, which has been illustrated in the tutorials of customized tuners/advisors/assessors.
NNI also allows users to install the customized algorithm as a builtin algorithm, in order for users to use the algorithm in the same way as NNI builtin tuners/advisors/assessors. More importantly, it becomes much easier for users to share or distribute their implemented algorithm to others. Customized tuners/advisors/assessors can be installed into NNI as builtin algorithms, once they are installed into NNI, you can use your customized algorithms the same way as builtin tuners/advisors/assessors in your experiment configuration file. For example, you built a customized tuner and installed it into NNI using a builtin name mytuner, then you can use this tuner in your configuration file like below:
tuner:
builtinTunerName: mytuner
Install customized algorithms as builtin tuners, assessors and advisors¶
You can follow below steps to build a customized tuner/assessor/advisor, and install it into NNI as builtin algorithm.
1. Create a customized tuner/assessor/advisor¶
Reference following instructions to create:
2. (Optional) Create a validator to validate classArgs¶
NNI provides a ClassArgsValidator interface for customized algorithms author to validate the classArgs parameters in experiment configuration file which are passed to customized algorithms constructors.
The ClassArgsValidator interface is defined as:
class ClassArgsValidator(object):
def validate_class_args(self, **kwargs):
"""
The classArgs fields in experiment configuration are packed as a dict and
passed to validator as kwargs.
"""
pass
For example, you can implement your validator such as:
from schema import Schema, Optional
from nni import ClassArgsValidator
class MedianstopClassArgsValidator(ClassArgsValidator):
def validate_class_args(self, **kwargs):
Schema({
Optional('optimize_mode'): self.choices('optimize_mode', 'maximize', 'minimize'),
Optional('start_step'): self.range('start_step', int, 0, 9999),
}).validate(kwargs)
The validator will be invoked before experiment is started to check whether the classArgs fields are valid for your customized algorithms.
3. Prepare package installation source¶
In order to be installed as builtin tuners, assessors and advisors, the customized algorithms need to be packaged as installable source which can be recognized by pip command, under the hood nni calls pip command to install the package.
Besides being a common pip source, the package needs to provide meta information in the classifiers field.
Format of classifiers field is a following:
NNI Package :: <type> :: <builtin name> :: <full class name of tuner> :: <full class name of class args validator>
type: type of algorithms, could be one oftuner,assessor,advisorbuiltin name: builtin name used in experiment configuration filefull class name of tuner: tuner class name, including its module name, for example:demo_tuner.DemoTunerfull class name of class args validator: class args validator class name, including its module name, for example:demo_tuner.MyClassArgsValidator
Following is an example of classfiers in package’s setup.py:
classifiers = [
'Programming Language :: Python :: 3',
'License :: OSI Approved :: MIT License',
'Operating System :: ',
'NNI Package :: tuner :: demotuner :: demo_tuner.DemoTuner :: demo_tuner.MyClassArgsValidator'
],
Once you have the meta info in setup.py, you can build your pip installation source via:
- Run command
python setup.py developfrom the package directory, this command will build the directory as a pip installation source. - Run command
python setup.py bdist_wheelfrom the package directory, this command build a whl file which is a pip installation source.
NNI will look for the classifier starts with NNI Package to retrieve the package meta information while the package being installed with nnictl package install <source> command.
Reference customized tuner example for a full example.
4. Install customized algorithms package into NNI¶
If your installation source is prepared as a directory with python setup.py develop, you can install the package by following command:
nnictl package install <installation source directory>
For example:
nnictl package install nni/examples/tuners/customized_tuner/
If your installation source is prepared as a whl file with python setup.py bdist_wheel, you can install the package by following command:
nnictl package install <whl file path>
For example:
nnictl package install nni/examples/tuners/customized_tuner/dist/demo_tuner-0.1-py3-none-any.whl
5. Use the installed builtin algorithms in experiment¶
Once your customized algorithms is installed, you can use it in experiment configuration file the same way as other builtin tuners/assessors/advisors, for example:
tuner:
builtinTunerName: demotuner
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
Manage packages using nnictl package¶
List installed packages¶
Run following command to list the installed packages:
nnictl package list
+-----------------+------------+-----------+--------=-------------+------------------------------------------+
| Name | Type | Installed | Class Name | Module Name |
+-----------------+------------+-----------+----------------------+------------------------------------------+
| demotuner | tuners | Yes | DemoTuner | demo_tuner |
| SMAC | tuners | No | SMACTuner | nni.smac_tuner.smac_tuner |
| PPOTuner | tuners | No | PPOTuner | nni.ppo_tuner.ppo_tuner |
| BOHB | advisors | Yes | BOHB | nni.bohb_advisor.bohb_advisor |
+-----------------+------------+-----------+----------------------+------------------------------------------+
Run following command to list all packages, including the builtin packages can not be uninstalled.
nnictl package list --all
+-----------------+------------+-----------+--------=-------------+------------------------------------------+
| Name | Type | Installed | Class Name | Module Name |
+-----------------+------------+-----------+----------------------+------------------------------------------+
| TPE | tuners | Yes | HyperoptTuner | nni.hyperopt_tuner.hyperopt_tuner |
| Random | tuners | Yes | HyperoptTuner | nni.hyperopt_tuner.hyperopt_tuner |
| Anneal | tuners | Yes | HyperoptTuner | nni.hyperopt_tuner.hyperopt_tuner |
| Evolution | tuners | Yes | EvolutionTuner | nni.evolution_tuner.evolution_tuner |
| BatchTuner | tuners | Yes | BatchTuner | nni.batch_tuner.batch_tuner |
| GridSearch | tuners | Yes | GridSearchTuner | nni.gridsearch_tuner.gridsearch_tuner |
| NetworkMorphism | tuners | Yes | NetworkMorphismTuner | nni.networkmorphism_tuner.networkmo... |
| MetisTuner | tuners | Yes | MetisTuner | nni.metis_tuner.metis_tuner |
| GPTuner | tuners | Yes | GPTuner | nni.gp_tuner.gp_tuner |
| PBTTuner | tuners | Yes | PBTTuner | nni.pbt_tuner.pbt_tuner |
| SMAC | tuners | No | SMACTuner | nni.smac_tuner.smac_tuner |
| PPOTuner | tuners | No | PPOTuner | nni.ppo_tuner.ppo_tuner |
| Medianstop | assessors | Yes | MedianstopAssessor | nni.medianstop_assessor.medianstop_... |
| Curvefitting | assessors | Yes | CurvefittingAssessor | nni.curvefitting_assessor.curvefitt... |
| Hyperband | advisors | Yes | Hyperband | nni.hyperband_advisor.hyperband_adv... |
| BOHB | advisors | Yes | BOHB | nni.bohb_advisor.bohb_advisor |
+-----------------+------------+-----------+----------------------+------------------------------------------+
Uninstall package¶
Run following command to uninstall an installed package:
nnictl package uninstall <builtin name>
For example:
nnictl package uninstall demotuner
How to install customized tuner as a builtin tuner¶
You can following below steps to install a customized tuner in nni/examples/tuners/customized_tuner as a builtin tuner.
Prepare installation source and install package¶
There are 2 options to install this customized tuner:
Option 1: install from directory¶
Step 1: From nni/examples/tuners/customized_tuner directory, run:
python setup.py develop
This command will build the nni/examples/tuners/customized_tuner directory as a pip installation source.
Step 2: Run command:
nnictl package install ./
Option 2: install from whl file¶
Step 1: From nni/examples/tuners/customized_tuner directory, run:
python setup.py bdist_wheel
This command build a whl file which is a pip installation source.
Step 2: Run command:
nnictl package install dist/demo_tuner-0.1-py3-none-any.whl
Check the installed package¶
Then run command nnictl package list, you should be able to see that demotuner is installed:
+-----------------+------------+-----------+--------=-------------+------------------------------------------+
| Name | Type | Installed | Class Name | Module Name |
+-----------------+------------+-----------+----------------------+------------------------------------------+
| demotuner | tuners | Yes | DemoTuner | demo_tuner |
+-----------------+------------+-----------+----------------------+------------------------------------------+
Use the installed tuner in experiment¶
Now you can use the demotuner in experiment configuration file the same way as other builtin tuners:
tuner:
builtinTunerName: demotuner
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
Neural Architecture Search¶
Automatic neural architecture search is taking an increasingly important role on finding better models. Recent research works have proved the feasibility of automatic NAS, and also found some models that could beat manually tuned models. Some of representative works are NASNet, ENAS, DARTS, Network Morphism, and Evolution. Moreover, new innovations keep emerging.
However, it takes great efforts to implement NAS algorithms, and it is hard to reuse code base of existing algorithms in a new one. To facilitate NAS innovations (e.g., design and implement new NAS models, compare different NAS models side-by-side), an easy-to-use and flexible programming interface is crucial.
Therefore, we provide a unified interface for NAS, to accelerate innovations on NAS, and apply state-of-art algorithms on real world problems faster. For details, please refer to the following tutorials:
Neural Architecture Search (NAS) on NNI¶
Contents
Overview¶
Automatic neural architecture search is taking an increasingly important role in finding better models. Recent research has proved the feasibility of automatic NAS and has lead to models that beat many manually designed and tuned models. Some representative works are NASNet, ENAS, DARTS, Network Morphism, and Evolution. Further, new innovations keep emerging.
However, it takes a great effort to implement NAS algorithms, and it’s hard to reuse the code base of existing algorithms for new ones. To facilitate NAS innovations (e.g., the design and implementation of new NAS models, the comparison of different NAS models side-by-side, etc.), an easy-to-use and flexible programming interface is crucial.
With this motivation, our ambition is to provide a unified architecture in NNI, accelerate innovations on NAS, and apply state-of-the-art algorithms to real-world problems faster.
With the unified interface, there are two different modes for architecture search. One is the so-called one-shot NAS, where a super-net is built based on a search space and one-shot training is used to generate a good-performing child model. The other is the traditional search-based approach, where each child model within the search space runs as an independent trial. We call it classic NAS.
NNI also provides dedicated visualization tool for users to check the status of the neural architecture search process.
Supported Classic NAS Algorithms¶
The procedure of classic NAS algorithms is similar to hyper-parameter tuning, users use nnictl to start experiments and each model runs as a trial. The difference is that search space file is automatically generated from user model (with search space in it) by running nnictl ss_gen. The following table listed supported tuning algorihtms for classic NAS mode. More algorihtms will be supported in future release.
| Name | Brief Introduction of Algorithm |
|---|---|
| Random Search | Randomly pick a model from search space |
| PPO Tuner | PPO Tuner is a Reinforcement Learning tuner based on PPO algorithm. Reference Paper |
Please refer to here for the usage of classic NAS algorithms.
Supported One-shot NAS Algorithms¶
NNI currently supports the one-shot NAS algorithms listed below and is adding more. Users can reproduce an algorithm or use it on their own dataset. We also encourage users to implement other algorithms with NNI API, to benefit more people.
| Name | Brief Introduction of Algorithm |
|---|---|
| ENAS | Efficient Neural Architecture Search via Parameter Sharing. In ENAS, a controller learns to discover neural network architectures by searching for an optimal subgraph within a large computational graph. It uses parameter sharing between child models to achieve fast speed and excellent performance. |
| DARTS | DARTS: Differentiable Architecture Search introduces a novel algorithm for differentiable network architecture search on bilevel optimization. |
| P-DARTS | Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation is based on DARTS. It introduces an efficient algorithm which allows the depth of searched architectures to grow gradually during the training procedure. |
| SPOS | Single Path One-Shot Neural Architecture Search with Uniform Sampling constructs a simplified supernet trained with a uniform path sampling method and applies an evolutionary algorithm to efficiently search for the best-performing architectures. |
| CDARTS | Cyclic Differentiable Architecture Search builds a cyclic feedback mechanism between the search and evaluation networks. It introduces a cyclic differentiable architecture search framework which integrates the two networks into a unified architecture. |
| ProxylessNAS | ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware. It removes proxy, directly learns the architectures for large-scale target tasks and target hardware platforms. |
| TextNAS | TextNAS: A Neural Architecture Search Space tailored for Text Representation. It is a neural architecture search algorithm tailored for text representation. |
One-shot algorithms run standalone without nnictl. NNI supports both PyTorch and Tensorflow 2.X.
Here are some common dependencies to run the examples. PyTorch needs to be above 1.2 to use BoolTensor.
- tensorboard
- PyTorch 1.2+
- git
Please refer to here for the usage of one-shot NAS algorithms.
One-shot NAS can be visualized with our visualization tool. Learn more details here.
Using NNI API to Write Your Search Space¶
The programming interface of designing and searching a model is often demanded in two scenarios.
- When designing a neural network, there may be multiple operation choices on a layer, sub-model, or connection, and it’s undetermined which one or combination performs best. So, it needs an easy way to express the candidate layers or sub-models.
- When applying NAS on a neural network, it needs a unified way to express the search space of architectures, so that it doesn’t need to update trial code for different search algorithms.
For using NNI NAS, we suggest users to first go through the tutorial of NAS API for building search space.
NAS Visualization¶
To help users track the process and status of how the model is searched under specified search space, we developed a visualization tool. It visualizes search space as a super-net and shows importance of subnets and layers/operations, as well as how the importance changes along with the search process. Please refer to the document of NAS visualization for how to use it.
Reference and Feedback¶
- To report a bug for this feature in GitHub;
- To file a feature or improvement request for this feature in GitHub.
Write A Search Space¶
Genrally, a search space describes candiate architectures from which users want to find the best one. Different search algorithms, no matter classic NAS or one-shot NAS, can be applied on the search space. NNI provides APIs to unified the expression of neural architecture search space.
A search space can be built on a base model. This is also a common practice when a user wants to apply NAS on an existing model. Take MNIST on PyTorch as an example. Note that NNI provides the same APIs for expressing search space on PyTorch and TensorFlow.
from nni.nas.pytorch import mutables
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = mutables.LayerChoice([
nn.Conv2d(1, 32, 3, 1),
nn.Conv2d(1, 32, 5, 3)
]) # try 3x3 kernel and 5x5 kernel
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
# ... same as original ...
return output
The example above adds an option of choosing conv5x5 at conv1. The modification is as simple as declaring a LayerChoice with the original conv3x3 and a new conv5x5 as its parameter. That’s it! You don’t have to modify the forward function in any way. You can imagine conv1 as any other module without NAS.
So how about the possibilities of connections? This can be done using InputChoice. To allow for a skip connection on the MNIST example, we add another layer called conv3. In the following example, a possible connection from conv2 is added to the output of conv3.
from nni.nas.pytorch import mutables
class Net(nn.Module):
def __init__(self):
# ... same ...
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.conv3 = nn.Conv2d(64, 64, 1, 1)
# declaring that there is exactly one candidate to choose from
# search strategy will choose one or None
self.skipcon = mutables.InputChoice(n_candidates=1)
# ... same ...
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x0 = self.skipcon([x]) # choose one or none from [x]
x = self.conv3(x)
if x0 is not None: # skipconnection is open
x += x0
x = F.max_pool2d(x, 2)
# ... same ...
return output
Input choice can be thought of as a callable module that receives a list of tensors and outputs the concatenation/sum/mean of some of them (sum by default), or None if none is selected. Like layer choices, input choices should be initialized in __init__ and called in forward. This is to allow search algorithms to identify these choices and do necessary preparations.
LayerChoice and InputChoice are both mutables. Mutable means “changeable”. As opposed to traditional deep learning layers/modules which have fixed operation types once defined, models with mutable are essentially a series of possible models.
Users can specify a key for each mutable. By default, NNI will assign one for you that is globally unique, but in case users want to share choices (for example, there are two LayerChoices with the same candidate operations and you want them to have the same choice, i.e., if first one chooses the i-th op, the second one also chooses the i-th op), they can give them the same key. The key marks the identity for this choice and will be used in the dumped checkpoint. So if you want to increase the readability of your exported architecture, manually assigning keys to each mutable would be a good idea. For advanced usage on mutables (e.g., LayerChoice and InputChoice), see Mutables.
With search space defined, the next step is searching for the best model from it. Please refer to classic NAS algorithms and one-shot NAS algorithms for how to search from your defined search space.
Classic NAS Algorithms¶
In classic NAS algorithms, each architecture is trained as a trial and the NAS algorithm acts as a tuner. Thus, this training mode naturally fits within the NNI hyper-parameter tuning framework, where Tuner generates new architecture for the next trial and trials run in the training service.
Quick Start¶
The following example shows how to use classic NAS algorithms. You can see it is quite similar to NNI hyper-parameter tuning.
model = Net()
# get the chosen architecture from tuner and apply it on model
get_and_apply_next_architecture(model)
train(model) # your code for training the model
acc = test(model) # test the trained model
nni.report_final_result(acc) # report the performance of the chosen architecture
First, instantiate the model. Search space has been defined in this model through LayerChoice and InputChoice. After that, user should invoke get_and_apply_next_architecture(model) to settle down to a specific architecture. This function receives the architecture from tuner (i.e., the classic NAS algorithm) and applies the architecture to model. At this point, model becomes a specific architecture rather than a search space. Then users are free to train this model just like training a normal PyTorch model. After get the accuracy of this model, users should invoke nni.report_final_result(acc) to report the result to the tuner.
At this point, trial code is ready. Then, we can prepare an NNI experiment, i.e., search space file and experiment config file. Different from NNI hyper-parameter tuning, search space file is automatically generated from the trial code by running the command (the detailed usage of this command can be found here):
nnictl ss_gen --trial_command="the command for running your trial code"
A file named nni_auto_gen_search_space.json is generated by this command. Then put the path of the generated search space in the field searchSpacePath of the experiment config file. The other fields of the config file can be filled by referring this tutorial.
Currently, we only support PPO Tuner and random tuner for classic NAS. More classic NAS algorithms will be supported soon.
The complete examples can be found here for PyTorch and here for TensorFlow.
Standalone mode for easy debugging¶
We support a standalone mode for easy debugging, where you can directly run the trial command without launching an NNI experiment. This is for checking whether your trial code can correctly run. The first candidate(s) are chosen for LayerChoice and InputChoice in this standalone mode.
One-shot NAS Algorithms¶
One-shot NAS algorithms leverage weight sharing among models in neural architecture search space to train a supernet, and use this supernet to guide the selection of better models. This type of algorihtms greatly reduces computational resource compared to independently training each model from scratch (which we call “Classic NAS”). NNI has supported many popular One-shot NAS algorithms as following.
One-shot NAS algorithms¶
Besides classic NAS algorithms, users also apply more advanced one-shot NAS algorithms to find better models from a search space. There are lots of related works about one-shot NAS algorithms, such as SMASH, ENAS, DARTS, FBNet, ProxylessNAS, SPOS, Single-Path NAS, Understanding One-shot and GDAS. One-shot NAS algorithms usually build a supernet containing every candidate in the search space as its subnetwork, and in each step, a subnetwork or combination of several subnetworks is trained.
Currently, several one-shot NAS methods are supported on NNI. For example, DartsTrainer, which uses SGD to train architecture weights and model weights iteratively, and ENASTrainer, which uses a controller to train the model. New and more efficient NAS trainers keep emerging in research community and some will be implemented in future releases of NNI.
Search with One-shot NAS Algorithms¶
Each one-shot NAS algorithm implements a trainer, for which users can find usage details in the description of each algorithm. Here is a simple example, demonstrating how users can use EnasTrainer.
# this is exactly same as traditional model training
model = Net()
dataset_train = CIFAR10(root="./data", train=True, download=True, transform=train_transform)
dataset_valid = CIFAR10(root="./data", train=False, download=True, transform=valid_transform)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), 0.05, momentum=0.9, weight_decay=1.0E-4)
# use NAS here
def top1_accuracy(output, target):
# this is the function that computes the reward, as required by ENAS algorithm
batch_size = target.size(0)
_, predicted = torch.max(output.data, 1)
return (predicted == target).sum().item() / batch_size
def metrics_fn(output, target):
# metrics function receives output and target and computes a dict of metrics
return {"acc1": top1_accuracy(output, target)}
from nni.nas.pytorch import enas
trainer = enas.EnasTrainer(model,
loss=criterion,
metrics=metrics_fn,
reward_function=top1_accuracy,
optimizer=optimizer,
batch_size=128
num_epochs=10, # 10 epochs
dataset_train=dataset_train,
dataset_valid=dataset_valid,
log_frequency=10) # print log every 10 steps
trainer.train() # training
trainer.export(file="model_dir/final_architecture.json") # export the final architecture to file
model is the one with user defined search space. Then users should prepare training data and model evaluation metrics. To search from the defined search space, a one-shot algorithm is instantiated, called trainer (e.g., EnasTrainer). The trainer exposes a few arguments that you can customize. For example, the loss function, the metrics function, the optimizer, and the datasets. These should satisfy most usage requirements and we do our best to make sure our built-in trainers work on as many models, tasks, and datasets as possible.
Note that when using one-shot NAS algorithms, there is no need to start an NNI experiment. Users can directly run this Python script (i.e., train.py) through python3 train.py without nnictl. After training, users can export the best one of the found models through trainer.export().
Each trainer in NNI has its targeted scenario and usage. Some trainers have the assumption that the task is a classification task; some trainers might have a different definition of “epoch” (e.g., an ENAS epoch = some child steps + some controller steps). Most trainers do not have support for distributed training: they won’t wrap your model with DataParallel or DistributedDataParallel to do that. So after a few tryouts, if you want to actually use the trainers on your very customized applications, you might need to customize your trainer.
Furthermore, one-shot NAS can be visualized with our NAS UI. See more details.
Retrain with Exported Architecture¶
After the search phase, it’s time to train the found architecture. Unlike many open-source NAS algorithms who write a whole new model specifically for retraining. We found that the search model and retraining model are usually very similar, and therefore you can construct your final model with the exact same model code. For example
model = Net()
apply_fixed_architecture(model, "model_dir/final_architecture.json")
The JSON is simply a mapping from mutable keys to choices. Choices can be expressed in:
- A string: select the candidate with corresponding name.
- A number: select the candidate with corresponding index.
- A list of string: select the candidates with corresponding names.
- A list of number: select the candidates with corresponding indices.
- A list of boolean values: a multi-hot array.
For example,
{
"LayerChoice1": "conv5x5",
"LayerChoice2": 6,
"InputChoice3": ["layer1", "layer3"],
"InputChoice4": [1, 2],
"InputChoice5": [false, true, false, false, true]
}
After applying, the model is then fixed and ready for final training. The model works as a single model, and unused parameters and modules are pruned.
Also, refer to DARTS for code exemplifying retraining.
ENAS¶
Introduction¶
The paper Efficient Neural Architecture Search via Parameter Sharing uses parameter sharing between child models to accelerate the NAS process. In ENAS, a controller learns to discover neural network architectures by searching for an optimal subgraph within a large computational graph. The controller is trained with policy gradient to select a subgraph that maximizes the expected reward on the validation set. Meanwhile the model corresponding to the selected subgraph is trained to minimize a canonical cross entropy loss.
Implementation on NNI is based on the official implementation in Tensorflow, including a general-purpose Reinforcement-learning controller and a trainer that trains target network and this controller alternatively. Following paper, we have also implemented macro and micro search space on CIFAR10 to demonstrate how to use these trainers. Since code to train from scratch on NNI is not ready yet, reproduction results are currently unavailable.
Examples¶
CIFAR10 Macro/Micro Search Space¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/enas
# search in macro search space
python3 search.py --search-for macro
# search in micro search space
python3 search.py --search-for micro
# view more options for search
python3 search.py -h
Reference¶
PyTorch¶
-
class
nni.nas.pytorch.enas.EnasTrainer(model, loss, metrics, reward_function, optimizer, num_epochs, dataset_train, dataset_valid, mutator=None, batch_size=64, workers=4, device=None, log_frequency=None, callbacks=None, entropy_weight=0.0001, skip_weight=0.8, baseline_decay=0.999, child_steps=500, mutator_lr=0.00035, mutator_steps_aggregate=20, mutator_steps=50, aux_weight=0.4, test_arc_per_epoch=1)[source]¶ ENAS trainer.
Parameters: - model (nn.Module) – PyTorch model to be trained.
- loss (callable) – Receives logits and ground truth label, return a loss tensor.
- metrics (callable) – Receives logits and ground truth label, return a dict of metrics.
- reward_function (callable) – Receives logits and ground truth label, return a tensor, which will be feeded to RL controller as reward.
- optimizer (Optimizer) – The optimizer used for optimizing the model.
- num_epochs (int) – Number of epochs planned for training.
- dataset_train (Dataset) – Dataset for training. Will be split for training weights and architecture weights.
- dataset_valid (Dataset) – Dataset for testing.
- mutator (EnasMutator) – Use when customizing your own mutator or a mutator with customized parameters.
- batch_size (int) – Batch size.
- workers (int) – Workers for data loading.
- device (torch.device) –
torch.device("cpu")ortorch.device("cuda"). - log_frequency (int) – Step count per logging.
- callbacks (list of Callback) – list of callbacks to trigger at events.
- entropy_weight (float) – Weight of sample entropy loss.
- skip_weight (float) – Weight of skip penalty loss.
- baseline_decay (float) – Decay factor of baseline. New baseline will be equal to
baseline_decay * baseline_old + reward * (1 - baseline_decay). - child_steps (int) – How many mini-batches for model training per epoch.
- mutator_lr (float) – Learning rate for RL controller.
- mutator_steps_aggregate (int) – Number of steps that will be aggregated into one mini-batch for RL controller.
- mutator_steps (int) – Number of mini-batches for each epoch of RL controller learning.
- aux_weight (float) – Weight of auxiliary head loss.
aux_weight * aux_losswill be added to total loss. - test_arc_per_epoch (int) – How many architectures are chosen for direct test after each epoch.
-
class
nni.nas.pytorch.enas.EnasMutator(model, lstm_size=64, lstm_num_layers=1, tanh_constant=1.5, cell_exit_extra_step=False, skip_target=0.4, temperature=None, branch_bias=0.25, entropy_reduction='sum')[source]¶ A mutator that mutates the graph with RL.
Parameters: - model (nn.Module) – PyTorch model.
- lstm_size (int) – Controller LSTM hidden units.
- lstm_num_layers (int) – Number of layers for stacked LSTM.
- tanh_constant (float) – Logits will be equal to
tanh_constant * tanh(logits). Don’t usetanhif this value isNone. - cell_exit_extra_step (bool) – If true, RL controller will perform an extra step at the exit of each MutableScope, dump the hidden state and mark it as the hidden state of this MutableScope. This is to align with the original implementation of paper.
- skip_target (float) – Target probability that skipconnect will appear.
- temperature (float) – Temperature constant that divides the logits.
- branch_bias (float) – Manual bias applied to make some operations more likely to be chosen.
Currently this is implemented with a hardcoded match rule that aligns with original repo.
If a mutable has a
reducein its key, all its op choices that contains conv in their typename will receive a bias of+self.branch_biasinitially; while others receive a bias of-self.branch_bias. - entropy_reduction (str) – Can be one of
sumandmean. How the entropy of multi-input-choice is reduced.
DARTS¶
Introduction¶
The paper DARTS: Differentiable Architecture Search addresses the scalability challenge of architecture search by formulating the task in a differentiable manner. Their method is based on the continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent.
Authors’ code optimizes the network weights and architecture weights alternatively in mini-batches. They further explore the possibility that uses second order optimization (unroll) instead of first order, to improve the performance.
Implementation on NNI is based on the official implementation and a popular 3rd-party repo. DARTS on NNI is designed to be general for arbitrary search space. A CNN search space tailored for CIFAR10, same as the original paper, is implemented as a use case of DARTS.
Reproduction Results¶
The above-mentioned example is meant to reproduce the results in the paper, we do experiments with first and second order optimization. Due to the time limit, we retrain only the best architecture derived from the search phase and we repeat the experiment only once. Our results is currently on par with the results reported in paper. We will add more results later when ready.
| In paper | Reproduction | |
|---|---|---|
| First order (CIFAR10) | 3.00 +/- 0.14 | 2.78 |
| Second order (CIFAR10) | 2.76 +/- 0.09 | 2.89 |
Examples¶
CNN Search Space¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/darts
python3 search.py
# train the best architecture
python3 retrain.py --arc-checkpoint ./checkpoints/epoch_49.json
Reference¶
PyTorch¶
-
class
nni.nas.pytorch.darts.DartsTrainer(model, loss, metrics, optimizer, num_epochs, dataset_train, dataset_valid, mutator=None, batch_size=64, workers=4, device=None, log_frequency=None, callbacks=None, arc_learning_rate=0.0003, unrolled=False)[source]¶ DARTS trainer.
Parameters: - model (nn.Module) – PyTorch model to be trained.
- loss (callable) – Receives logits and ground truth label, return a loss tensor.
- metrics (callable) – Receives logits and ground truth label, return a dict of metrics.
- optimizer (Optimizer) – The optimizer used for optimizing the model.
- num_epochs (int) – Number of epochs planned for training.
- dataset_train (Dataset) – Dataset for training. Will be split for training weights and architecture weights.
- dataset_valid (Dataset) – Dataset for testing.
- mutator (DartsMutator) – Use in case of customizing your own DartsMutator. By default will instantiate a DartsMutator.
- batch_size (int) – Batch size.
- workers (int) – Workers for data loading.
- device (torch.device) –
torch.device("cpu")ortorch.device("cuda"). - log_frequency (int) – Step count per logging.
- callbacks (list of Callback) – list of callbacks to trigger at events.
- arc_learning_rate (float) – Learning rate of architecture parameters.
- unrolled (float) –
Trueif using second order optimization, else first order optimization.
-
class
nni.nas.pytorch.darts.DartsMutator(model)[source]¶ Connects the model in a DARTS (differentiable) way.
An extra connection is automatically inserted for each LayerChoice, when this connection is selected, there is no op on this LayerChoice (namely a
ZeroOp), in which case, every element in the exported choice list isfalse(not chosen).All input choice will be fully connected in the search phase. On exporting, the input choice will choose inputs based on keys in
choose_from. If the keys were to be keys of LayerChoices, the top logit of the corresponding LayerChoice will join the competition of input choice to compete against other logits. Otherwise, the logit will be assumed 0.It’s possible to cut branches by setting parameter
choicesin a particular position to-inf. After softmax, the value would be 0. Framework will ignore 0 values and not connect. Note that the gradient on the-inflocation will be 0. Since manipulations with-infwill benan, you need to handle the gradient update phase carefully.-
choices¶ dict that maps keys of LayerChoices to weighted-connection float tensors.
Type: ParameterDict
-
Limitations¶
- DARTS doesn’t support DataParallel and needs to be customized in order to support DistributedDataParallel.
P-DARTS¶
Examples¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/pdarts
python3 search.py
# train the best architecture, it's the same progress as darts.
cd ../darts
python3 retrain.py --arc-checkpoint ../pdarts/checkpoints/epoch_2.json
Single Path One-Shot (SPOS)¶
Introduction¶
Proposed in Single Path One-Shot Neural Architecture Search with Uniform Sampling is a one-shot NAS method that addresses the difficulties in training One-Shot NAS models by constructing a simplified supernet trained with an uniform path sampling method, so that all underlying architectures (and their weights) get trained fully and equally. An evolutionary algorithm is then applied to efficiently search for the best-performing architectures without any fine tuning.
Implementation on NNI is based on official repo. We implement a trainer that trains the supernet and a evolution tuner that leverages the power of NNI framework that speeds up the evolutionary search phase. We have also shown
Examples¶
Here is a use case, which is the search space in paper, and the way to use flops limit to perform uniform sampling.
Requirements¶
NVIDIA DALI >= 0.16 is needed as we use DALI to accelerate the data loading of ImageNet. Installation guide
Download the flops lookup table from here (maintained by Megvii).
Put op_flops_dict.pkl and checkpoint-150000.pth.tar (if you don’t want to retrain the supernet) under data directory.
Prepare ImageNet in the standard format (follow the script here). Linking it to data/imagenet will be more convenient.
After preparation, it’s expected to have the following code structure:
spos
├── architecture_final.json
├── blocks.py
├── config_search.yml
├── data
│ ├── imagenet
│ │ ├── train
│ │ └── val
│ └── op_flops_dict.pkl
├── dataloader.py
├── network.py
├── readme.md
├── scratch.py
├── supernet.py
├── tester.py
├── tuner.py
└── utils.py
Step 1. Train Supernet¶
python supernet.py
Will export the checkpoint to checkpoints directory, for the next step.
NOTE: The data loading used in the official repo is slightly different from usual, as they use BGR tensor and keep the values between 0 and 255 intentionally to align with their own DL framework. The option --spos-preprocessing will simulate the behavior used originally and enable you to use the checkpoints pretrained.
Step 2. Evolution Search¶
Single Path One-Shot leverages evolution algorithm to search for the best architecture. The tester, which is responsible for testing the sampled architecture, recalculates all the batch norm for a subset of training images, and evaluates the architecture on the full validation set.
In order to make the tuner aware of the flops limit and have the ability to calculate the flops, we created a new tuner called EvolutionWithFlops in tuner.py, inheriting the tuner in SDK.
To have a search space ready for NNI framework, first run
nnictl ss_gen -t "python tester.py"
This will generate a file called nni_auto_gen_search_space.json, which is a serialized representation of your search space.
By default, it will use checkpoint-150000.pth.tar downloaded previously. In case you want to use the checkpoint trained by yourself from the last step, specify --checkpoint in the command in config_search.yml.
Then search with evolution tuner.
nnictl create --config config_search.yml
The final architecture exported from every epoch of evolution can be found in checkpoints under the working directory of your tuner, which, by default, is $HOME/nni/experiments/your_experiment_id/log.
Step 3. Train from Scratch¶
python scratch.py
By default, it will use architecture_final.json. This architecture is provided by the official repo (converted into NNI format). You can use any architecture (e.g., the architecture found in step 2) with --fixed-arc option.
Reference¶
PyTorch¶
-
class
nni.nas.pytorch.spos.SPOSEvolution(max_epochs=20, num_select=10, num_population=50, m_prob=0.1, num_crossover=25, num_mutation=25)[source]¶ SPOS evolution tuner.
Parameters: - max_epochs (int) – Maximum number of epochs to run.
- num_select (int) – Number of survival candidates of each epoch.
- num_population (int) – Number of candidates at the start of each epoch. If candidates generated by crossover and mutation are not enough, the rest will be filled with random candidates.
- m_prob (float) – The probability of mutation.
- num_crossover (int) – Number of candidates generated by crossover in each epoch.
- num_mutation (int) – Number of candidates generated by mutation in each epoch.
-
export_results(result)[source]¶ Export a number of candidates to checkpoints dir.
Parameters: result (dict) – Chosen architectures to be exported.
-
generate_multiple_parameters(parameter_id_list, **kwargs)[source]¶ Callback function necessary to implement a tuner. This will put more parameter ids into the parameter id queue.
-
receive_trial_result(parameter_id, parameters, value, **kwargs)[source]¶ Callback function. Receive a trial result.
-
class
nni.nas.pytorch.spos.SPOSSupernetTrainer(model, loss, metrics, optimizer, num_epochs, train_loader, valid_loader, mutator=None, batch_size=64, workers=4, device=None, log_frequency=None, callbacks=None)[source]¶ This trainer trains a supernet that can be used for evolution search.
Parameters: - model (nn.Module) – Model with mutables.
- mutator (Mutator) – A mutator object that has been initialized with the model.
- loss (callable) – Called with logits and targets. Returns a loss tensor.
- metrics (callable) – Returns a dict that maps metrics keys to metrics data.
- optimizer (Optimizer) – Optimizer that optimizes the model.
- num_epochs (int) – Number of epochs of training.
- train_loader (iterable) – Data loader of training. Raise
StopIterationwhen one epoch is exhausted. - dataset_valid (iterable) – Data loader of validation. Raise
StopIterationwhen one epoch is exhausted. - batch_size (int) – Batch size.
- workers (int) – Number of threads for data preprocessing. Not used for this trainer. Maybe removed in future.
- device (torch.device) – Device object. Either
torch.device("cuda")ortorch.device("cpu"). WhenNone, trainer will automatic detects GPU and selects GPU first. - log_frequency (int) – Number of mini-batches to log metrics.
- callbacks (list of Callback) – Callbacks to plug into the trainer. See Callbacks.
-
class
nni.nas.pytorch.spos.SPOSSupernetTrainingMutator(model, flops_func=None, flops_lb=None, flops_ub=None, flops_bin_num=7, flops_sample_timeout=500)[source]¶ A random mutator with flops limit.
Parameters: - model (nn.Module) – PyTorch model.
- flops_func (callable) – Callable that takes a candidate from sample_search and returns its candidate. When flops_func is None, functions related to flops will be deactivated.
- flops_lb (number) – Lower bound of flops.
- flops_ub (number) – Upper bound of flops.
- flops_bin_num (number) – Number of bins divided for the interval of flops to ensure the uniformity. Bigger number will be more uniform, but the sampling will be slower.
- flops_sample_timeout (int) – Maximum number of attempts to sample before giving up and use a random candidate.
Known Limitations¶
- Block search only. Channel search is not supported yet.
- Only GPU version is provided here.
Current Reproduction Results¶
Reproduction is still undergoing. Due to the gap between official release and original paper, we compare our current results with official repo (our run) and paper.
- Evolution phase is almost aligned with official repo. Our evolution algorithm shows a converging trend and reaches ~65% accuracy at the end of search. Nevertheless, this result is not on par with paper. For details, please refer to this issue.
- Retrain phase is not aligned. Our retraining code, which uses the architecture released by the authors, reaches 72.14% accuracy, still having a gap towards 73.61% by official release and 74.3% reported in original paper.
CDARTS¶
Introduction¶
CDARTS builds a cyclic feedback mechanism between the search and evaluation networks. First, the search network generates an initial topology for evaluation, so that the weights of the evaluation network can be optimized. Second, the architecture topology in the search network is further optimized by the label supervision in classification, as well as the regularization from the evaluation network through feature distillation. Repeating the above cycle results in a joint optimization of the search and evaluation networks, and thus enables the evolution of the topology to fit the final evaluation network.
In implementation of CdartsTrainer, it first instantiates two models and two mutators (one for each). The first model is the so-called “search network”, which is mutated with a RegularizedDartsMutator – a mutator with subtle differences with DartsMutator. The second model is the “evaluation network”, which is mutated with a discrete mutator that leverages the previous search network mutator, to sample a single path each time. Trainers train models and mutators alternatively. Users can refer to references if they are interested in more details on these trainers and mutators.
Reproduction Results¶
This is CDARTS based on the NNI platform, which currently supports CIFAR10 search and retrain. ImageNet search and retrain should also be supported, and we provide corresponding interfaces. Our reproduced results on NNI are slightly lower than the paper, but much higher than the original DARTS. Here we show the results of three independent experiments on CIFAR10.
| Runs | Paper | NNI |
|---|---|---|
| 1 | 97.52 | 97.44 |
| 2 | 97.53 | 97.48 |
| 3 | 97.58 | 97.56 |
Examples¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# install apex for distributed training.
git clone https://github.com/NVIDIA/apex
cd apex
python setup.py install --cpp_ext --cuda_ext
# search the best architecture
cd examples/nas/cdarts
bash run_search_cifar.sh
# train the best architecture.
bash run_retrain_cifar.sh
Reference¶
PyTorch¶
-
class
nni.nas.pytorch.cdarts.CdartsTrainer(model_small, model_large, criterion, loaders, samplers, logger=None, regular_coeff=5, regular_ratio=0.2, warmup_epochs=2, fix_head=True, epochs=32, steps_per_epoch=None, loss_alpha=2, loss_T=2, distributed=True, log_frequency=10, grad_clip=5.0, interactive_type='kl', output_path='./outputs', w_lr=0.2, w_momentum=0.9, w_weight_decay=0.0003, alpha_lr=0.2, alpha_weight_decay=0.0001, nasnet_lr=0.2, local_rank=0, share_module=True)[source]¶ CDARTS trainer.
Parameters: - model_small (nn.Module) – PyTorch model to be trained. This is the search network of CDARTS.
- model_large (nn.Module) – PyTorch model to be trained. This is the evaluation network of CDARTS.
- criterion (callable) – Receives logits and ground truth label, return a loss tensor, e.g.,
nn.CrossEntropyLoss(). - loaders (list of torch.utils.data.DataLoader) – List of train data and valid data loaders, for training weights and architecture weights respectively.
- samplers (list of torch.utils.data.Sampler) – List of train data and valid data samplers. This can be PyTorch standard samplers if not distributed.
In distributed mode, sampler needs to have
set_epochmethod. Refer to data utils in CDARTS example for details. - logger (logging.Logger) – The logger for logging. Will use nni logger by default (if logger is
None). - regular_coeff (float) – The coefficient of regular loss.
- regular_ratio (float) – The ratio of regular loss.
- warmup_epochs (int) – The epochs to warmup the search network
- fix_head (bool) –
Trueif fixing the paramters of auxiliary heads, else unfix the paramters of auxiliary heads. - epochs (int) – Number of epochs planned for training.
- steps_per_epoch (int) – Steps of one epoch.
- loss_alpha (float) – The loss coefficient.
- loss_T (float) – The loss coefficient.
- distributed (bool) –
Trueif using distributed training, else non-distributed training. - log_frequency (int) – Step count per logging.
- grad_clip (float) – Gradient clipping for weights.
- interactive_type (string) –
klorsmoothl1. - output_path (string) – Log storage path.
- w_lr (float) – Learning rate of the search network parameters.
- w_momentum (float) – Momentum of the search and the evaluation network.
- w_weight_decay (float) – The weight decay the search and the evaluation network parameters.
- alpha_lr (float) – Learning rate of the architecture parameters.
- alpha_weight_decay (float) – The weight decay the architecture parameters.
- nasnet_lr (float) – Learning rate of the evaluation network parameters.
- local_rank (int) – The number of thread.
- share_module (bool) –
Trueif sharing the stem and auxiliary heads, else not sharing these modules.
-
class
nni.nas.pytorch.cdarts.RegularizedDartsMutator(model)[source]¶ This is
DartsMutatorbasically, with two differences.1. Choices can be cut (bypassed). This is done by
cut_choices. Cutted choices will not be used in forward pass and thus consumes no memory.- Regularization on choices, to prevent the mutator from overfitting on some choices.
-
cut_choices(cut_num=2)[source]¶ Cut the choices with the smallest weights.
cut_numshould be the accumulative number of cutting, e.g., if first time cutting is 2, the second time should be 4 to cut another two.Parameters: cut_num (int) – Number of choices to cut, so far. Warning
Though the parameters are set to \(-\infty\) to be bypassed, they will still receive gradient of 0, which introduced
nanproblem when callingoptimizer.step(). To solve this issue, a simple way is to reset nan to \(-\infty\) each time after the parameters are updated.
-
export(logger=None)[source]¶ Export an architecture with logger. Genotype will be printed with logger.
Returns: A mapping from mutable keys to decisions. Return type: dict
-
reset()[source]¶ Warning
Renamed
reset_with_loss()to return regularization loss on reset.
-
reset_with_loss()[source]¶ Resample and return loss. If loss is 0, to avoid device issue, it will return
None.Currently loss penalty are proportional to the L1-norm of parameters corresponding to modules if their type name contains certain substrings. These substrings include:
poolwithoutbn,identity,dilconv.
-
class
nni.nas.pytorch.cdarts.DartsDiscreteMutator(model, parent_mutator)[source]¶ A mutator that applies the final sampling result of a parent mutator on another model to train.
Parameters: - model (nn.Module) – The model to apply the mutator.
- parent_mutator (Mutator) – The mutator that provides
sample_finalmethod, that will be called to get the architecture.
-
class
nni.nas.pytorch.cdarts.RegularizedMutatorParallel(*args, **kwargs)[source]¶ Parallelize
RegularizedDartsMutator.This makes
reset_with_loss()method parallelized, also allowingcut_choices()andexport()to be easily accessible.-
cut_choices(*args, **kwargs)[source]¶ Parallelized
cut_choices().
-
reset_with_loss()[source]¶ Parallelized
reset_with_loss().
-
ProxylessNAS on NNI¶
Introduction¶
The paper ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware removes proxy, it directly learns the architectures for large-scale target tasks and target hardware platforms. They address high memory consumption issue of differentiable NAS and reduce the computational cost to the same level of regular training while still allowing a large candidate set. Please refer to the paper for the details.
Usage¶
To use ProxylessNAS training/searching approach, users need to specify search space in their model using NNI NAS interface, e.g., LayerChoice, InputChoice. After defining and instantiating the model, the following work can be leaved to ProxylessNasTrainer by instantiating the trainer and passing the model to it.
trainer = ProxylessNasTrainer(model,
model_optim=optimizer,
train_loader=data_provider.train,
valid_loader=data_provider.valid,
device=device,
warmup=True,
ckpt_path=args.checkpoint_path,
arch_path=args.arch_path)
trainer.train()
trainer.export(args.arch_path)
The complete example code can be found here.
Input arguments of ProxylessNasTrainer
- model (PyTorch model, required) - The model that users want to tune/search. It has mutables to specify search space.
- model_optim (PyTorch optimizer, required) - The optimizer users want to train the model.
- device (device, required) - The devices that users provide to do the train/search. The trainer applies data parallel on the model for users.
- train_loader (PyTorch data loader, required) - The data loader for training set.
- valid_loader (PyTorch data loader, required) - The data loader for validation set.
- label_smoothing (float, optional, default = 0.1) - The degree of label smoothing.
- n_epochs (int, optional, default = 120) - The number of epochs to train/search.
- init_lr (float, optional, default = 0.025) - The initial learning rate for training the model.
- binary_mode (‘two’, ‘full’, or ‘full_v2’, optional, default = ‘full_v2’) - The forward/backward mode for the binary weights in mutator. ‘full’ means forward all the candidate ops, ‘two’ means only forward two sampled ops, ‘full_v2’ means recomputing the inactive ops during backward.
- arch_init_type (‘normal’ or ‘uniform’, optional, default = ‘normal’) - The way to init architecture parameters.
- arch_init_ratio (float, optional, default = 1e-3) - The ratio to init architecture parameters.
- arch_optim_lr (float, optional, default = 1e-3) - The learning rate of the architecture parameters optimizer.
- arch_weight_decay (float, optional, default = 0) - Weight decay of the architecture parameters optimizer.
- grad_update_arch_param_every (int, optional, default = 5) - Update architecture weights every this number of minibatches.
- grad_update_steps (int, optional, default = 1) - During each update of architecture weights, the number of steps to train architecture weights.
- warmup (bool, optional, default = True) - Whether to do warmup.
- warmup_epochs (int, optional, default = 25) - The number of epochs to do during warmup.
- arch_valid_frequency (int, optional, default = 1) - The frequency of printing validation result.
- load_ckpt (bool, optional, default = False) - Whether to load checkpoint.
- ckpt_path (str, optional, default = None) - checkpoint path, if load_ckpt is True, ckpt_path cannot be None.
- arch_path (str, optional, default = None) - The path to store chosen architecture.
Implementation¶
The implementation on NNI is based on the offical implementation. The official implementation supports two training approaches: gradient descent and RL based, and support different targeted hardware, including ‘mobile’, ‘cpu’, ‘gpu8’, ‘flops’. In our current implementation on NNI, gradient descent training approach is supported, but has not supported different hardwares. The complete support is ongoing.
Below we will describe implementation details. Like other one-shot NAS algorithms on NNI, ProxylessNAS is composed of two parts: search space and training approach. For users to flexibly define their own search space and use built-in ProxylessNAS training approach, we put the specified search space in example code using NNI NAS interface, and put the training approach in SDK.

ProxylessNAS training approach is composed of ProxylessNasMutator and ProxylessNasTrainer. ProxylessNasMutator instantiates MixedOp for each mutable (i.e., LayerChoice), and manage architecture weights in MixedOp. For DataParallel, architecture weights should be included in user model. Specifically, in ProxylessNAS implementation, we add MixedOp to the corresponding mutable (i.e., LayerChoice) as a member variable. The mutator also exposes two member functions, i.e., arch_requires_grad, arch_disable_grad, for the trainer to control the training of architecture weights.
ProxylessNasMutator also implements the forward logic of the mutables (i.e., LayerChoice).
Reproduce Results¶
To reproduce the result, we first run the search, we found that though it runs many epochs the chosen architecture converges at the first several epochs. This is probably induced by hyper-parameters or the implementation, we are working on it. The test accuracy of the found architecture is top1: 72.31, top5: 90.26.
TextNAS¶
Introduction¶
This is the implementation of the TextNAS algorithm proposed in the paper TextNAS: A Neural Architecture Search Space tailored for Text Representation. TextNAS is a neural architecture search algorithm tailored for text representation, more specifically, TextNAS is based on a novel search space consists of operators widely adopted to solve various NLP tasks, and TextNAS also supports multi-path ensemble within a single network to balance the width and depth of the architecture.
The search space of TextNAS contains:
* 1-D convolutional operator with filter size 1, 3, 5, 7
* recurrent operator (bi-directional GRU)
* self-attention operator
* pooling operator (max/average)
Following the ENAS algorithm, TextNAS also utilizes parameter sharing to accelerate the search speed and adopts a reinforcement-learning controller for the architecture sampling and generation. Please refer to the paper for more details of TextNAS.
Preparation¶
Prepare the word vectors and SST dataset, and organize them in data directory as shown below:
textnas
├── data
│ ├── sst
│ │ └── trees
│ │ ├── dev.txt
│ │ ├── test.txt
│ │ └── train.txt
│ └── glove.840B.300d.txt
├── dataloader.py
├── model.py
├── ops.py
├── README.md
├── search.py
└── utils.py
The following link might be helpful for finding and downloading the corresponding dataset:
Examples¶
Search Space¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/textnas
# view more options for search
python3 search.py -h
After each search epoch, 10 sampled architectures will be tested directly. Their performances are expected to be 40% - 42% after 10 epochs.
By default, 20 sampled architectures will be exported into checkpoints directory for next step.
retrain¶
# In case NNI code is not cloned. If the code is cloned already, ignore this line and enter code folder.
git clone https://github.com/Microsoft/nni.git
# search the best architecture
cd examples/nas/textnas
# default to retrain on sst-2
sh run_retrain.sh
Customize a NAS Algorithm¶
Extend the Ability of One-Shot Trainers¶
Users might want to do multiple things if they are using the trainers on real tasks, for example, distributed training, half-precision training, logging periodically, writing tensorboard, dumping checkpoints and so on. As mentioned previously, some trainers do have support for some of the items listed above; others might not. Generally, there are two recommended ways to add anything you want to an existing trainer: inherit an existing trainer and override, or copy an existing trainer and modify.
Either way, you are walking into the scope of implementing a new trainer. Basically, implementing a one-shot trainer is no different from any traditional deep learning trainer, except that a new concept called mutator will reveal itself. So that the implementation will be different in at least two places:
- Initialization
model = Model()
mutator = MyMutator(model)
- Training
for _ in range(epochs):
for x, y in data_loader:
mutator.reset() # reset all the choices in model
out = model(x) # like traditional model
loss = criterion(out, y)
loss.backward()
# no difference below
To demonstrate what mutators are for, we need to know how one-shot NAS normally works. Usually, one-shot NAS “co-optimize model weights and architecture weights”. It repeatedly: sample an architecture or combination of several architectures from the supernet, train the chosen architectures like traditional deep learning model, update the trained parameters to the supernet, and use the metrics or loss as some signal to guide the architecture sampler. The mutator, is the architecture sampler here, often defined to be another deep-learning model. Therefore, you can treat it as any model, by defining parameters in it and optimizing it with optimizers. One mutator is initialized with exactly one model. Once a mutator is binded to a model, it cannot be rebinded to another model.
mutator.reset() is the core step. That’s where all the choices in the model are finalized. The reset result will be always effective, until the next reset flushes the data. After the reset, the model can be seen as a traditional model to do forward-pass and backward-pass.
Finally, mutators provide a method called mutator.export() that export a dict with architectures to the model. Note that currently this dict this a mapping from keys of mutables to tensors of selection. So in order to dump to json, users need to convert the tensors explicitly into python list.
Meanwhile, NNI provides some useful tools so that users can implement trainers more easily. See Trainers for details.
Implement New Mutators¶
To start with, here is the pseudo-code that demonstrates what happens on mutator.reset() and mutator.export().
def reset(self):
self.apply_on_model(self.sample_search())
def export(self):
return self.sample_final()
On reset, a new architecture is sampled with sample_search() and applied on the model. Then the model is trained for one or more steps in search phase. On export, a new architecture is sampled with sample_final() and do nothing to the model. This is either for checkpoint or exporting the final architecture.
The requirements of return values of sample_search() and sample_final() are the same: a mapping from mutable keys to tensors. The tensor can be either a BoolTensor (true for selected, false for negative), or a FloatTensor which applies weight on each candidate. The selected branches will then be computed (in LayerChoice, modules will be called; in InputChoice, it’s just tensors themselves), and reduce with the reduction operation specified in the choices. For most algorithms only worrying about the former part, here is an example of your mutator implementation.
class RandomMutator(Mutator):
def __init__(self, model):
super().__init__(model) # don't forget to call super
# do something else
def sample_search(self):
result = dict()
for mutable in self.mutables: # this is all the mutable modules in user model
# mutables share the same key will be de-duplicated
if isinstance(mutable, LayerChoice):
# decided that this mutable should choose `gen_index`
gen_index = np.random.randint(mutable.length)
result[mutable.key] = torch.tensor([i == gen_index for i in range(mutable.length)],
dtype=torch.bool)
elif isinstance(mutable, InputChoice):
if mutable.n_chosen is None: # n_chosen is None, then choose any number
result[mutable.key] = torch.randint(high=2, size=(mutable.n_candidates,)).view(-1).bool()
# else do something else
return result
def sample_final(self):
return self.sample_search() # use the same logic here. you can do something different
The complete example of random mutator can be found here.
For advanced usages, e.g., users want to manipulate the way modules in LayerChoice are executed, they can inherit BaseMutator, and overwrite on_forward_layer_choice and on_forward_input_choice, which are the callback implementation of LayerChoice and InputChoice respectively. Users can still use property mutables to get all LayerChoice and InputChoice in the model code. For details, please refer to reference here to learn more.
Tip
A useful application of random mutator is for debugging. Use
mutator = RandomMutator(model)
mutator.reset()
will immediately set one possible candidate in the search space as the active one.
Implemented a Distributed NAS Tuner¶
Before learning how to write a distributed NAS tuner, users should first learn how to write a general tuner. read Customize Tuner for tutorials.
When users call “nnictl ss_gen” to generate search space file, a search space file like this will be generated:
{
"key_name": {
"_type": "layer_choice",
"_value": ["op1_repr", "op2_repr", "op3_repr"]
},
"key_name": {
"_type": "input_choice",
"_value": {
"candidates": ["in1_key", "in2_key", "in3_key"],
"n_chosen": 1
}
}
}
This is the exact search space tuners will receive in update_search_space. It’s then tuners’ responsibility to interpret the search space and generate new candidates in generate_parameters. A valid “parameters” will be in the following format:
{
"key_name": {
"_value": "op1_repr",
"_idx": 0
},
"key_name": {
"_value": ["in2_key"],
"_idex": [1]
}
}
Send it through generate_parameters, and the tuner would look like any HPO tuner. Refer to SPOS example code for an example.
NAS Visualization (Experimental)¶
Built-in Trainers Support¶
Currently, only ENAS and DARTS support visualization. Examples of ENAS and DARTS has demonstrated how to enable visualization in your code, namely, adding this before trainer.train():
trainer.enable_visualization()
This will create a directory logs/<current_time_stamp> in your working folder, in which you will find two files graph.json and log.
You don’t have to wait until your program finishes to launch NAS UI, but it’s important that these two files have been already created. Launch NAS UI with
nnictl webui nas --logdir logs/<current_time_stamp> --port <port>
Visualize a Customized Trainer¶
If you are interested in how to customize a trainer, please read this doc.
You should do two modifications to an existing trainer to enable visualization:
- Export your graph before training, with
vis_graph = self.mutator.graph(inputs)
# `inputs` is a dummy input to your model. For example, torch.randn((1, 3, 32, 32)).cuda()
# If your model has multiple inputs, it should be a tuple.
with open("/path/to/your/logdir/graph.json", "w") as f:
json.dump(vis_graph, f)
- Logging the choices you’ve made. You can do it once per epoch, once per mini-batch or whatever frequency you’d like.
def __init__(self):
# ...
self.status_writer = open("/path/to/your/logdir/log", "w") # create a writer
def train(self):
# ...
print(json.dumps(self.mutator.status()), file=self.status_writer, flush=True) # dump a record of status
If you are implementing your customized trainer inheriting Trainer. We have provided enable_visualization() and _write_graph_status() for easy-to-use purposes. All you need to do is calling trainer.enable_visualization() before start, and trainer._write_graph_status() each time you want to do the logging. But remember both of these APIs are experimental and subject to change in future.
Last but not least, invode NAS UI with
nnictl webui nas --logdir /path/to/your/logdir


Limitations¶
- NAS visualization only works with PyTorch >=1.4. We’ve tested it on PyTorch 1.3.1 and it doesn’t work.
- We rely on PyTorch support for tensorboard for graph export, which relies on
torch.jit. It will not work if your model doesn’t supportjit. - There are known performance issues when loading a moderate-size graph with many op choices (like DARTS search space).
Feedback¶
NAS UI is currently experimental. We welcome your feedback. Here we have listed all the to-do items of NAS UI in the future. Feel free to comment (or submit a new issue) if you have other suggestions.
NAS Benchmarks (experimental)¶
Example Usages of NAS Benchmarks¶
[1]:
import pprint
import time
from nni.nas.benchmarks.nasbench101 import query_nb101_trial_stats
from nni.nas.benchmarks.nasbench201 import query_nb201_trial_stats
from nni.nas.benchmarks.nds import query_nds_trial_stats
ti = time.time()
NAS-Bench-101¶
Use the following architecture as an example: 
[2]:
arch = {
'op1': 'conv3x3-bn-relu',
'op2': 'maxpool3x3',
'op3': 'conv3x3-bn-relu',
'op4': 'conv3x3-bn-relu',
'op5': 'conv1x1-bn-relu',
'input1': [0],
'input2': [1],
'input3': [2],
'input4': [0],
'input5': [0, 3, 4],
'input6': [2, 5]
}
for t in query_nb101_trial_stats(arch, 108):
pprint.pprint(t)
{'config': {'arch': {'input1': [0],
'input2': [1],
'input3': [2],
'input4': [0],
'input5': [0, 3, 4],
'input6': [2, 5],
'op1': 'conv3x3-bn-relu',
'op2': 'maxpool3x3',
'op3': 'conv3x3-bn-relu',
'op4': 'conv3x3-bn-relu',
'op5': 'conv1x1-bn-relu'},
'hash': '00005c142e6f48ac74fdcf73e3439874',
'id': 4,
'num_epochs': 108,
'num_vertices': 7},
'id': 10,
'parameters': 8.55553,
'test_acc': 92.11738705635071,
'train_acc': 100.0,
'training_time': 106147.67578125,
'valid_acc': 92.41786599159241}
{'config': {'arch': {'input1': [0],
'input2': [1],
'input3': [2],
'input4': [0],
'input5': [0, 3, 4],
'input6': [2, 5],
'op1': 'conv3x3-bn-relu',
'op2': 'maxpool3x3',
'op3': 'conv3x3-bn-relu',
'op4': 'conv3x3-bn-relu',
'op5': 'conv1x1-bn-relu'},
'hash': '00005c142e6f48ac74fdcf73e3439874',
'id': 4,
'num_epochs': 108,
'num_vertices': 7},
'id': 11,
'parameters': 8.55553,
'test_acc': 91.90705418586731,
'train_acc': 100.0,
'training_time': 106095.05859375,
'valid_acc': 92.45793223381042}
{'config': {'arch': {'input1': [0],
'input2': [1],
'input3': [2],
'input4': [0],
'input5': [0, 3, 4],
'input6': [2, 5],
'op1': 'conv3x3-bn-relu',
'op2': 'maxpool3x3',
'op3': 'conv3x3-bn-relu',
'op4': 'conv3x3-bn-relu',
'op5': 'conv1x1-bn-relu'},
'hash': '00005c142e6f48ac74fdcf73e3439874',
'id': 4,
'num_epochs': 108,
'num_vertices': 7},
'id': 12,
'parameters': 8.55553,
'test_acc': 92.15745329856873,
'train_acc': 100.0,
'training_time': 106138.55712890625,
'valid_acc': 93.04887652397156}
An architecture of NAS-Bench-101 could be trained more than once. Each element of the returned generator is a dict which contains one of the training results of this trial config (architecture + hyper-parameters) including train/valid/test accuracy, training time, number of epochs, etc. The results of NAS-Bench-201 and NDS follow similar formats.
NAS-Bench-201¶
Use the following architecture as an example: 
[3]:
arch = {
'0_1': 'avg_pool_3x3',
'0_2': 'conv_1x1',
'1_2': 'skip_connect',
'0_3': 'conv_1x1',
'1_3': 'skip_connect',
'2_3': 'skip_connect'
}
for t in query_nb201_trial_stats(arch, 200, 'cifar100'):
pprint.pprint(t)
{'config': {'arch': {'0_1': 'avg_pool_3x3',
'0_2': 'conv_1x1',
'0_3': 'conv_1x1',
'1_2': 'skip_connect',
'1_3': 'skip_connect',
'2_3': 'skip_connect'},
'dataset': 'cifar100',
'id': 7,
'num_cells': 5,
'num_channels': 16,
'num_epochs': 200},
'flops': 15.65322,
'id': 3,
'latency': 0.013182918230692545,
'ori_test_acc': 53.11,
'ori_test_evaluation_time': 1.0195916947864352,
'ori_test_loss': 1.7307863704681397,
'parameters': 0.135156,
'seed': 999,
'test_acc': 53.07999995727539,
'test_evaluation_time': 0.5097958473932176,
'test_loss': 1.731276072692871,
'train_acc': 57.82,
'train_loss': 1.5116578379058838,
'training_time': 2888.4371995925903,
'valid_acc': 53.14000000610351,
'valid_evaluation_time': 0.5097958473932176,
'valid_loss': 1.7302966793060304}
{'config': {'arch': {'0_1': 'avg_pool_3x3',
'0_2': 'conv_1x1',
'0_3': 'conv_1x1',
'1_2': 'skip_connect',
'1_3': 'skip_connect',
'2_3': 'skip_connect'},
'dataset': 'cifar100',
'id': 7,
'num_cells': 5,
'num_channels': 16,
'num_epochs': 200},
'flops': 15.65322,
'id': 7,
'latency': 0.013182918230692545,
'ori_test_acc': 51.93,
'ori_test_evaluation_time': 1.0195916947864352,
'ori_test_loss': 1.7572312774658203,
'parameters': 0.135156,
'seed': 777,
'test_acc': 51.979999938964845,
'test_evaluation_time': 0.5097958473932176,
'test_loss': 1.7429540189743042,
'train_acc': 57.578,
'train_loss': 1.5114233912658692,
'training_time': 2888.4371995925903,
'valid_acc': 51.88,
'valid_evaluation_time': 0.5097958473932176,
'valid_loss': 1.7715086591720581}
{'config': {'arch': {'0_1': 'avg_pool_3x3',
'0_2': 'conv_1x1',
'0_3': 'conv_1x1',
'1_2': 'skip_connect',
'1_3': 'skip_connect',
'2_3': 'skip_connect'},
'dataset': 'cifar100',
'id': 7,
'num_cells': 5,
'num_channels': 16,
'num_epochs': 200},
'flops': 15.65322,
'id': 11,
'latency': 0.013182918230692545,
'ori_test_acc': 53.38,
'ori_test_evaluation_time': 1.0195916947864352,
'ori_test_loss': 1.7281623031616211,
'parameters': 0.135156,
'seed': 888,
'test_acc': 53.67999998779297,
'test_evaluation_time': 0.5097958473932176,
'test_loss': 1.7327697801589965,
'train_acc': 57.792,
'train_loss': 1.5091403088760376,
'training_time': 2888.4371995925903,
'valid_acc': 53.08000000610352,
'valid_evaluation_time': 0.5097958473932176,
'valid_loss': 1.7235548280715942}
NDS¶
Use the following architecture as an example: 
Here, bot_muls, ds, num_gs, ss and ws stand for “bottleneck multipliers”, “depths”, “number of groups”, “strides” and “widths” respectively.
[4]:
model_spec = {
'bot_muls': [0.0, 0.25, 0.25, 0.25],
'ds': [1, 16, 1, 4],
'num_gs': [1, 2, 1, 2],
'ss': [1, 1, 2, 2],
'ws': [16, 64, 128, 16]
}
# Use none as a wildcard
for t in query_nds_trial_stats('residual_bottleneck', None, None, model_spec, None, 'cifar10'):
pprint.pprint(t)
{'best_test_acc': 90.48,
'best_train_acc': 96.356,
'best_train_loss': 0.116,
'config': {'base_lr': 0.1,
'cell_spec': {},
'dataset': 'cifar10',
'generator': 'random',
'id': 45505,
'model_family': 'residual_bottleneck',
'model_spec': {'bot_muls': [0.0, 0.25, 0.25, 0.25],
'ds': [1, 16, 1, 4],
'num_gs': [1, 2, 1, 2],
'ss': [1, 1, 2, 2],
'ws': [16, 64, 128, 16]},
'num_epochs': 100,
'proposer': 'resnext-a',
'weight_decay': 0.0005},
'final_test_acc': 90.39,
'final_train_acc': 96.298,
'final_train_loss': 0.116,
'flops': 69.890986,
'id': 45505,
'iter_time': 0.065,
'parameters': 0.083002,
'seed': 1}
[5]:
model_spec = {'ds': [1, 12, 12, 12], 'ss': [1, 1, 2, 2], 'ws': [16, 24, 24, 40]}
for t in query_nds_trial_stats('residual_basic', 'resnet', 'random', model_spec, {}, 'cifar10'):
pprint.pprint(t)
{'best_test_acc': 93.58,
'best_train_acc': 99.772,
'best_train_loss': 0.011,
'config': {'base_lr': 0.1,
'cell_spec': {},
'dataset': 'cifar10',
'generator': 'random',
'id': 108998,
'model_family': 'residual_basic',
'model_spec': {'ds': [1, 12, 12, 12],
'ss': [1, 1, 2, 2],
'ws': [16, 24, 24, 40]},
'num_epochs': 100,
'proposer': 'resnet',
'weight_decay': 0.0005},
'final_test_acc': 93.49,
'final_train_acc': 99.772,
'final_train_loss': 0.011,
'flops': 184.519578,
'id': 108998,
'iter_time': 0.059,
'parameters': 0.594138,
'seed': 1}
[6]:
# get the first one
pprint.pprint(next(query_nds_trial_stats('vanilla', None, None, None, None, None)))
{'best_test_acc': 84.5,
'best_train_acc': 89.66499999999999,
'best_train_loss': 0.302,
'config': {'base_lr': 0.1,
'cell_spec': {},
'dataset': 'cifar10',
'generator': 'random',
'id': 139492,
'model_family': 'vanilla',
'model_spec': {'ds': [1, 12, 12, 12],
'ss': [1, 1, 2, 2],
'ws': [16, 24, 32, 40]},
'num_epochs': 100,
'proposer': 'vanilla',
'weight_decay': 0.0005},
'final_test_acc': 84.35,
'final_train_acc': 89.633,
'final_train_loss': 0.303,
'flops': 208.36393,
'id': 154692,
'iter_time': 0.058,
'parameters': 0.68977,
'seed': 1}
[7]:
# count number
model_spec = {'num_nodes_normal': 5, 'num_nodes_reduce': 5, 'depth': 12, 'width': 32, 'aux': False, 'drop_prob': 0.0}
cell_spec = {
'normal_0_op_x': 'avg_pool_3x3',
'normal_0_input_x': 0,
'normal_0_op_y': 'conv_7x1_1x7',
'normal_0_input_y': 1,
'normal_1_op_x': 'sep_conv_3x3',
'normal_1_input_x': 2,
'normal_1_op_y': 'sep_conv_5x5',
'normal_1_input_y': 0,
'normal_2_op_x': 'dil_sep_conv_3x3',
'normal_2_input_x': 2,
'normal_2_op_y': 'dil_sep_conv_3x3',
'normal_2_input_y': 2,
'normal_3_op_x': 'skip_connect',
'normal_3_input_x': 4,
'normal_3_op_y': 'dil_sep_conv_3x3',
'normal_3_input_y': 4,
'normal_4_op_x': 'conv_7x1_1x7',
'normal_4_input_x': 2,
'normal_4_op_y': 'sep_conv_3x3',
'normal_4_input_y': 4,
'normal_concat': [3, 5, 6],
'reduce_0_op_x': 'avg_pool_3x3',
'reduce_0_input_x': 0,
'reduce_0_op_y': 'dil_sep_conv_3x3',
'reduce_0_input_y': 1,
'reduce_1_op_x': 'sep_conv_3x3',
'reduce_1_input_x': 0,
'reduce_1_op_y': 'sep_conv_3x3',
'reduce_1_input_y': 0,
'reduce_2_op_x': 'skip_connect',
'reduce_2_input_x': 2,
'reduce_2_op_y': 'sep_conv_7x7',
'reduce_2_input_y': 0,
'reduce_3_op_x': 'conv_7x1_1x7',
'reduce_3_input_x': 4,
'reduce_3_op_y': 'skip_connect',
'reduce_3_input_y': 4,
'reduce_4_op_x': 'conv_7x1_1x7',
'reduce_4_input_x': 0,
'reduce_4_op_y': 'conv_7x1_1x7',
'reduce_4_input_y': 5,
'reduce_concat': [3, 6]
}
for t in query_nds_trial_stats('nas_cell', None, None, model_spec, cell_spec, 'cifar10'):
assert t['config']['model_spec'] == model_spec
assert t['config']['cell_spec'] == cell_spec
pprint.pprint(t)
{'best_test_acc': 93.37,
'best_train_acc': 99.91,
'best_train_loss': 0.006,
'config': {'base_lr': 0.1,
'cell_spec': {'normal_0_input_x': 0,
'normal_0_input_y': 1,
'normal_0_op_x': 'avg_pool_3x3',
'normal_0_op_y': 'conv_7x1_1x7',
'normal_1_input_x': 2,
'normal_1_input_y': 0,
'normal_1_op_x': 'sep_conv_3x3',
'normal_1_op_y': 'sep_conv_5x5',
'normal_2_input_x': 2,
'normal_2_input_y': 2,
'normal_2_op_x': 'dil_sep_conv_3x3',
'normal_2_op_y': 'dil_sep_conv_3x3',
'normal_3_input_x': 4,
'normal_3_input_y': 4,
'normal_3_op_x': 'skip_connect',
'normal_3_op_y': 'dil_sep_conv_3x3',
'normal_4_input_x': 2,
'normal_4_input_y': 4,
'normal_4_op_x': 'conv_7x1_1x7',
'normal_4_op_y': 'sep_conv_3x3',
'normal_concat': [3, 5, 6],
'reduce_0_input_x': 0,
'reduce_0_input_y': 1,
'reduce_0_op_x': 'avg_pool_3x3',
'reduce_0_op_y': 'dil_sep_conv_3x3',
'reduce_1_input_x': 0,
'reduce_1_input_y': 0,
'reduce_1_op_x': 'sep_conv_3x3',
'reduce_1_op_y': 'sep_conv_3x3',
'reduce_2_input_x': 2,
'reduce_2_input_y': 0,
'reduce_2_op_x': 'skip_connect',
'reduce_2_op_y': 'sep_conv_7x7',
'reduce_3_input_x': 4,
'reduce_3_input_y': 4,
'reduce_3_op_x': 'conv_7x1_1x7',
'reduce_3_op_y': 'skip_connect',
'reduce_4_input_x': 0,
'reduce_4_input_y': 5,
'reduce_4_op_x': 'conv_7x1_1x7',
'reduce_4_op_y': 'conv_7x1_1x7',
'reduce_concat': [3, 6]},
'dataset': 'cifar10',
'generator': 'random',
'id': 1,
'model_family': 'nas_cell',
'model_spec': {'aux': False,
'depth': 12,
'drop_prob': 0.0,
'num_nodes_normal': 5,
'num_nodes_reduce': 5,
'width': 32},
'num_epochs': 100,
'proposer': 'amoeba',
'weight_decay': 0.0005},
'final_test_acc': 93.27,
'final_train_acc': 99.91,
'final_train_loss': 0.006,
'flops': 664.400586,
'id': 1,
'iter_time': 0.281,
'parameters': 4.190314,
'seed': 1}
[8]:
# count number
print('NDS (amoeba) count:', len(list(query_nds_trial_stats(None, 'amoeba', None, None, None, None, None))))
NDS (amoeba) count: 5107
[9]:
print('Elapsed time: ', time.time() - ti, 'seconds')
Elapsed time: 1.9107539653778076 seconds
Introduction¶
To imporve the reproducibility of NAS algorithms as well as reducing computing resource requirements, researchers proposed a series of NAS benchmarks such as NAS-Bench-101, NAS-Bench-201, NDS, etc. NNI provides a query interface for users to acquire these benchmarks. Within just a few lines of code, researcher are able to evaluate their NAS algorithms easily and fairly by utilizing these benchmarks.
Prerequisites¶
- Please prepare a folder to household all the benchmark databases. By default, it can be found at
${HOME}/.nni/nasbenchmark. You can place it anywhere you like, and specify it inNASBENCHMARK_DIRbefore importing NNI. - Please install
peeweeviapip install peewee, which NNI uses to connect to database.
Data Preparation¶
To avoid storage and legality issues, we do not provide any prepared databases. Please follow the following steps.
- Clone NNI to your machine and enter
examples/nas/benchmarksdirectory.
git clone -b ${NNI_VERSION} https://github.com/microsoft/nni
cd nni/examples/nas/benchmarks
Replace ${NNI_VERSION} with a released version name or branch name, e.g., v1.7.
- Install dependencies via
pip3 install -r xxx.requirements.txt.xxxcan benasbench101,nasbench201ornds. - Generate the database via
./xxx.sh. The directory that stores the benchmark file can be configured withNASBENCHMARK_DIRenvironment variable, which defaults to~/.nni/nasbenchmark. Note that the NAS-Bench-201 dataset will be downloaded from a google drive.
Please make sure there is at least 10GB free disk space and note that the conversion process can take up to hours to complete.
Example Usages¶
Please refer to examples usages of Benchmarks API.
NAS-Bench-101¶
NAS-Bench-101 contains 423,624 unique neural networks, combined with 4 variations in number of epochs (4, 12, 36, 108), each of which is trained 3 times. It is a cell-wise search space, which constructs and stacks a cell by enumerating DAGs with at most 7 operators, and no more than 9 connections. All operators can be chosen from CONV3X3_BN_RELU, CONV1X1_BN_RELU and MAXPOOL3X3, except the first operator (always INPUT) and last operator (always OUTPUT).
Notably, NAS-Bench-101 eliminates invalid cells (e.g., there is no path from input to output, or there is redundant computation). Furthermore, isomorphic cells are de-duplicated, i.e., all the remaining cells are computationally unique.
API Documentation¶
-
nni.nas.benchmarks.nasbench101.query_nb101_trial_stats(arch, num_epochs, isomorphism=True, reduction=None)[source]¶ Query trial stats of NAS-Bench-101 given conditions.
Parameters: - arch (dict or None) – If a dict, it is in the format that is described in
nni.nas.benchmark.nasbench101.Nb101TrialConfig. Only trial stats matched will be returned. If none, architecture will be a wildcard. - num_epochs (int or None) – If int, matching results will be returned. Otherwise a wildcard.
- isomorphism (boolean) – Whether to match essentially-same architecture, i.e., architecture with the same graph-invariant hash value.
- reduction (str or None) – If ‘none’ or None, all trial stats will be returned directly. If ‘mean’, fields in trial stats will be averaged given the same trial config.
Returns: A generator of
nni.nas.benchmark.nasbench101.Nb101TrialStatsobjects, where each of them has been converted into a dict.Return type: generator of dict
- arch (dict or None) – If a dict, it is in the format that is described in
-
nasbench101.INPUT= 'input'¶
-
nasbench101.OUTPUT= 'output'¶
-
nasbench101.CONV3X3_BN_RELU= 'conv3x3-bn-relu'¶
-
nasbench101.CONV1X1_BN_RELU= 'conv1x1-bn-relu'¶
-
nasbench101.MAXPOOL3X3= 'maxpool3x3'¶
-
class
nni.nas.benchmarks.nasbench101.Nb101TrialConfig(*args, **kwargs)[source]¶ Trial config for NAS-Bench-101.
-
arch¶ A dict with keys
op1,op2, … andinput1,input2, … Vertices are enumerate from 0. Since node 0 is input node, it is skipped in this dict. Eachopis one ofnni.nas.benchmark.nasbench101.CONV3X3_BN_RELU,nni.nas.benchmark.nasbench101.CONV1X1_BN_RELU, andnni.nas.benchmark.nasbench101.MAXPOOL3X3. Eachinputis a list of previous nodes. For exampleinput5can be[0, 1, 3].Type: dict
-
num_vertices¶ Number of vertices (nodes) in one cell. Should be less than or equal to 7 in default setup.
Type: int
-
hash¶ Graph-invariant MD5 string for this architecture.
Type: str
-
num_epochs¶ Number of epochs planned for this trial. Should be one of 4, 12, 36, 108 in default setup.
Type: int
-
-
class
nni.nas.benchmarks.nasbench101.Nb101TrialStats(*args, **kwargs)[source]¶ Computation statistics for NAS-Bench-101. Each corresponds to one trial. Each config has multiple trials with different random seeds, but unfortunately seed for each trial is unavailable. NAS-Bench-101 trains and evaluates on CIFAR-10 by default. The original training set is divided into 40k training images and 10k validation images, and the original validation set is used for test only.
-
config¶ Setup for this trial data.
Type: Nb101TrialConfig
-
train_acc¶ Final accuracy on training data, ranging from 0 to 100.
Type: float
-
valid_acc¶ Final accuracy on validation data, ranging from 0 to 100.
Type: float
-
test_acc¶ Final accuracy on test data, ranging from 0 to 100.
Type: float
-
parameters¶ Number of trainable parameters in million.
Type: float
-
training_time¶ Duration of training in seconds.
Type: float
-
-
class
nni.nas.benchmarks.nasbench101.Nb101IntermediateStats(*args, **kwargs)[source]¶ Intermediate statistics for NAS-Bench-101.
-
trial¶ The exact trial where the intermediate result is produced.
Type: Nb101TrialStats
-
current_epoch¶ Elapsed epochs when evaluation is done.
Type: int
-
train_acc¶ Intermediate accuracy on training data, ranging from 0 to 100.
Type: float
-
valid_acc¶ Intermediate accuracy on validation data, ranging from 0 to 100.
Type: float
-
test_acc¶ Intermediate accuracy on test data, ranging from 0 to 100.
Type: float
-
training_time¶ Time elapsed in seconds.
Type: float
-
-
nni.nas.benchmarks.nasbench101.graph_util.nasbench_format_to_architecture_repr(adjacency_matrix, labeling)[source]¶ Computes a graph-invariance MD5 hash of the matrix and label pair. Imported from NAS-Bench-101 repo.
Parameters: - adjacency_matrix (np.ndarray) – A 2D array of shape NxN, where N is the number of vertices.
matrix[u][v]is 1 if there is a direct edge from u to v, otherwise it will be 0. - labeling (list of str) – A list of str that starts with input and ends with output. The intermediate nodes are chosen from candidate operators.
Returns: Converted number of vertices and architecture.
Return type: tuple and int and dict
- adjacency_matrix (np.ndarray) – A 2D array of shape NxN, where N is the number of vertices.
-
nni.nas.benchmarks.nasbench101.graph_util.infer_num_vertices(architecture)[source]¶ Infer number of vertices from an architecture dict.
Parameters: architecture (dict) – Architecture in NNI format. Returns: Number of vertices. Return type: int
-
nni.nas.benchmarks.nasbench101.graph_util.hash_module(architecture, vertices)[source]¶ Computes a graph-invariance MD5 hash of the matrix and label pair. This snippet is modified from code in NAS-Bench-101 repo.
Parameters: - matrix (np.ndarray) – Square upper-triangular adjacency matrix.
- labeling (list of int) – Labels of length equal to both dimensions of matrix.
Returns: MD5 hash of the matrix and labeling.
Return type: str
NAS-Bench-201¶
Paper link Open-source API Implementations
NAS-Bench-201 is a cell-wise search space that views nodes as tensors and edges as operators. The search space contains all possible densely-connected DAGs with 4 nodes, resulting in 15,625 candidates in total. Each operator (i.e., edge) is selected from a pre-defined operator set (NONE, SKIP_CONNECT, CONV_1X1, CONV_3X3 and AVG_POOL_3X3). Training appraoches vary in the dataset used (CIFAR-10, CIFAR-100, ImageNet) and number of epochs scheduled (12 and 200). Each combination of architecture and training approach is repeated 1 - 3 times with different random seeds.
API Documentation¶
-
nni.nas.benchmarks.nasbench201.query_nb201_trial_stats(arch, num_epochs, dataset, reduction=None)[source]¶ Query trial stats of NAS-Bench-201 given conditions.
Parameters: - arch (dict or None) – If a dict, it is in the format that is described in
nni.nas.benchmark.nasbench201.Nb201TrialConfig. Only trial stats matched will be returned. If none, architecture will be a wildcard. - num_epochs (int or None) – If int, matching results will be returned. Otherwise a wildcard.
- dataset (str or None) – If specified, can be one of the dataset available in
nni.nas.benchmark.nasbench201.Nb201TrialConfig. Otherwise a wildcard. - reduction (str or None) – If ‘none’ or None, all trial stats will be returned directly. If ‘mean’, fields in trial stats will be averaged given the same trial config.
Returns: A generator of
nni.nas.benchmark.nasbench201.Nb201TrialStatsobjects, where each of them has been converted into a dict.Return type: generator of dict
- arch (dict or None) – If a dict, it is in the format that is described in
-
nasbench201.NONE= 'none'¶
-
nasbench201.SKIP_CONNECT= 'skip_connect'¶
-
nasbench201.CONV_1X1= 'conv_1x1'¶
-
nasbench201.CONV_3X3= 'conv_3x3'¶
-
nasbench201.AVG_POOL_3X3= 'avg_pool_3x3'¶
-
class
nni.nas.benchmarks.nasbench201.Nb201TrialConfig(*args, **kwargs)[source]¶ Trial config for NAS-Bench-201.
-
arch¶ A dict with keys
0_1,0_2,0_3,1_2,1_3,2_3, each of which is an operator chosen fromnni.nas.benchmark.nasbench201.NONE,nni.nas.benchmark.nasbench201.SKIP_CONNECT,nni.nas.benchmark.nasbench201.CONV_1X1,nni.nas.benchmark.nasbench201.CONV_3X3andnni.nas.benchmark.nasbench201.AVG_POOL_3X3.Type: dict
-
num_epochs¶ Number of epochs planned for this trial. Should be one of 12 and 200.
Type: int
-
num_channels¶ Number of channels for initial convolution. 16 by default.
Type: int
-
num_cells¶ Number of cells per stage. 5 by default.
Type: int
-
dataset¶ Dataset used for training and evaluation. NAS-Bench-201 provides the following 4 options:
cifar10-valid(training data is splited into 25k for training and 25k for validation, validation data is used for test),cifar10(training data is used in training, validation data is splited into 25k for validation and 25k for testing),cifar100(same protocol ascifar10), andimagenet16-120(a subset of 120 classes in ImageNet, downscaled to 16x16, using training data for training, 6k images from validation set for validation and the other 6k for testing).Type: str
-
-
class
nni.nas.benchmarks.nasbench201.Nb201TrialStats(*args, **kwargs)[source]¶ Computation statistics for NAS-Bench-201. Each corresponds to one trial.
-
config¶ Setup for this trial data.
Type: Nb201TrialConfig
-
seed¶ Random seed selected, for reproduction.
Type: int
-
train_acc¶ Final accuracy on training data, ranging from 0 to 100.
Type: float
-
valid_acc¶ Final accuracy on validation data, ranging from 0 to 100.
Type: float
-
test_acc¶ Final accuracy on test data, ranging from 0 to 100.
Type: float
-
ori_test_acc¶ Test accuracy on original validation set (10k for CIFAR and 12k for Imagenet16-120), ranging from 0 to 100.
Type: float
-
train_loss¶ Final cross entropy loss on training data. Note that loss could be NaN, in which case this attributed will be None.
Type: float or None
-
valid_loss¶ Final cross entropy loss on validation data.
Type: float or None
-
test_loss¶ Final cross entropy loss on test data.
Type: float or None
-
ori_test_loss¶ Final cross entropy loss on original validation set.
Type: float or None
-
parameters¶ Number of trainable parameters in million.
Type: float
-
latency¶ Latency in seconds.
Type: float
-
flops¶ FLOPs in million.
Type: float
-
training_time¶ Duration of training in seconds.
Type: float
-
valid_evaluation_time¶ Time elapsed to evaluate on validation set.
Type: float
-
test_evaluation_time¶ Time elapsed to evaluate on test set.
Type: float
-
ori_test_evaluation_time¶ Time elapsed to evaluate on original test set.
Type: float
-
-
class
nni.nas.benchmarks.nasbench201.Nb201IntermediateStats(*args, **kwargs)[source]¶ Intermediate statistics for NAS-Bench-201.
-
trial¶ Corresponding trial.
Type: Nb201TrialStats
-
current_epoch¶ Elapsed epochs.
Type: int
-
train_acc¶ Current accuracy on training data, ranging from 0 to 100.
Type: float
-
valid_acc¶ Current accuracy on validation data, ranging from 0 to 100.
Type: float
-
test_acc¶ Current accuracy on test data, ranging from 0 to 100.
Type: float
-
ori_test_acc¶ Test accuracy on original validation set (10k for CIFAR and 12k for Imagenet16-120), ranging from 0 to 100.
Type: float
-
train_loss¶ Current cross entropy loss on training data.
Type: float or None
-
valid_loss¶ Current cross entropy loss on validation data.
Type: float or None
-
test_loss¶ Current cross entropy loss on test data.
Type: float or None
-
ori_test_loss¶ Current cross entropy loss on original validation set.
Type: float or None
-
NDS¶
On Network Design Spaces for Visual Recognition released trial statistics of over 100,000 configurations (models + hyper-parameters) sampled from multiple model families, including vanilla (feedforward network loosely inspired by VGG), ResNet and ResNeXt (residual basic block and residual bottleneck block) and NAS cells (following popular design from NASNet, Ameoba, PNAS, ENAS and DARTS). Most configurations are trained only once with a fixed seed, except a few that are trained twice or three times.
Instead of storing results obtained with different configurations in separate files, we dump them into one single database to enable comparison in multiple dimensions. Specifically, we use model_family to distinguish model types, model_spec for all hyper-parameters needed to build this model, cell_spec for detailed information on operators and connections if it is a NAS cell, generator to denote the sampling policy through which this configuration is generated. Refer to API documentation for details.
Available Operators¶
Here is a list of available operators used in NDS.
-
constants.NONE= 'none'¶
-
constants.SKIP_CONNECT= 'skip_connect'¶
-
constants.AVG_POOL_3X3= 'avg_pool_3x3'¶
-
constants.MAX_POOL_3X3= 'max_pool_3x3'¶
-
constants.MAX_POOL_5X5= 'max_pool_5x5'¶
-
constants.MAX_POOL_7X7= 'max_pool_7x7'¶
-
constants.CONV_1X1= 'conv_1x1'¶
-
constants.CONV_3X3= 'conv_3x3'¶
-
constants.CONV_3X1_1X3= 'conv_3x1_1x3'¶
-
constants.CONV_7X1_1X7= 'conv_7x1_1x7'¶
-
constants.DIL_CONV_3X3= 'dil_conv_3x3'¶
-
constants.DIL_CONV_5X5= 'dil_conv_5x5'¶
-
constants.SEP_CONV_3X3= 'sep_conv_3x3'¶
-
constants.SEP_CONV_5X5= 'sep_conv_5x5'¶
-
constants.SEP_CONV_7X7= 'sep_conv_7x7'¶
-
constants.DIL_SEP_CONV_3X3= 'dil_sep_conv_3x3'¶
API Documentation¶
-
nni.nas.benchmarks.nds.query_nds_trial_stats(model_family, proposer, generator, model_spec, cell_spec, dataset, num_epochs=None, reduction=None)[source]¶ Query trial stats of NDS given conditions.
Parameters: - model_family (str or None) – If str, can be one of the model families available in
nni.nas.benchmark.nds.NdsTrialConfig. Otherwise a wildcard. - proposer (str or None) – If str, can be one of the proposers available in
nni.nas.benchmark.nds.NdsTrialConfig. Otherwise a wildcard. - generator (str or None) – If str, can be one of the generators available in
nni.nas.benchmark.nds.NdsTrialConfig. Otherwise a wildcard. - model_spec (dict or None) – If specified, can be one of the model spec available in
nni.nas.benchmark.nds.NdsTrialConfig. Otherwise a wildcard. - cell_spec (dict or None) – If specified, can be one of the cell spec available in
nni.nas.benchmark.nds.NdsTrialConfig. Otherwise a wildcard. - dataset (str or None) – If str, can be one of the datasets available in
nni.nas.benchmark.nds.NdsTrialConfig. Otherwise a wildcard. - num_epochs (float or None) – If int, matching results will be returned. Otherwise a wildcard.
- reduction (str or None) – If ‘none’ or None, all trial stats will be returned directly. If ‘mean’, fields in trial stats will be averaged given the same trial config.
Returns: A generator of
nni.nas.benchmark.nds.NdsTrialStatsobjects, where each of them has been converted into a dict.Return type: generator of dict
- model_family (str or None) – If str, can be one of the model families available in
-
class
nni.nas.benchmarks.nds.NdsTrialConfig(*args, **kwargs)[source]¶ Trial config for NDS.
-
model_family¶ Could be
nas_cell,residual_bottleneck,residual_basicorvanilla.Type: str
-
model_spec¶ If
model_familyisnas_cell, it containsnum_nodes_normal,num_nodes_reduce,depth,width,auxanddrop_prob. Ifmodel_familyisresidual_bottleneck, it containsbot_muls,ds(depths),num_gs(number of groups) andss(strides). Ifmodel_familyisresidual_basicorvanilla, it containsds,ssandws.Type: dict
-
cell_spec¶ If
model_familyis notnas_cellit will be an empty dict. Otherwise, it specifies<normal/reduce>_<i>_<op/input>_<x/y>, where i ranges from 0 tonum_nodes_<normal/reduce> - 1. If it is anop, the value is chosen from the constants specified previously likenni.nas.benchmark.nds.CONV_1X1. If it is i’sinput, the value range from 0 toi + 1, asnas_celluses previous two nodes as inputs, and node 0 is actually the second node. Refer to NASNet paper for details. Finally, another two key-value pairsnormal_concatandreduce_concatspecify which nodes are eventually concatenated into output.Type: dict
-
dataset¶ Dataset used. Could be
cifar10orimagenet.Type: str
-
generator¶ Can be one of
randomwhich generates configurations at random, while keeping learning rate and weight decay fixed,fix_w_dwhich further keepswidthanddepthfixed, only applicable fornas_cell.tune_lr_wdwhich further tunes learning rate and weight decay.Type: str
-
proposer¶ Paper who has proposed the distribution for random sampling. Available proposers include
nasnet,darts,enas,pnas,amoeba,vanilla,resnext-a,resnext-b,resnet,resnet-b(ResNet with bottleneck). See NDS paper for details.Type: str
-
base_lr¶ Initial learning rate.
Type: float
-
weight_decay¶ L2 weight decay applied on weights.
Type: float
-
num_epochs¶ Number of epochs scheduled, during which learning rate will decay to 0 following cosine annealing.
Type: int
-
-
class
nni.nas.benchmarks.nds.NdsTrialStats(*args, **kwargs)[source]¶ Computation statistics for NDS. Each corresponds to one trial.
-
config¶ Corresponding config for trial.
Type: NdsTrialConfig
-
seed¶ Random seed selected, for reproduction.
Type: int
-
final_train_acc¶ Final accuracy on training data, ranging from 0 to 100.
Type: float
-
final_train_loss¶ Final cross entropy loss on training data. Could be NaN (None).
Type: float or None
-
final_test_acc¶ Final accuracy on test data, ranging from 0 to 100.
Type: float
-
best_train_acc¶ Best accuracy on training data, ranging from 0 to 100.
Type: float
-
best_train_loss¶ Best cross entropy loss on training data. Could be NaN (None).
Type: float or None
-
best_test_acc¶ Best accuracy on test data, ranging from 0 to 100.
Type: float
-
parameters¶ Number of trainable parameters in million.
Type: float
-
flops¶ FLOPs in million.
Type: float
-
iter_time¶ Seconds elapsed for each iteration.
Type: float
-
-
class
nni.nas.benchmarks.nds.NdsIntermediateStats(*args, **kwargs)[source]¶ Intermediate statistics for NDS.
-
trial¶ Corresponding trial.
Type: NdsTrialStats
-
current_epoch¶ Elapsed epochs.
Type: int
-
train_loss¶ Current cross entropy loss on training data. Can be NaN (None).
Type: float or None
-
train_acc¶ Current accuracy on training data, ranging from 0 to 100.
Type: float
-
test_acc¶ Current accuracy on test data, ranging from 0 to 100.
Type: float
-
NAS Reference¶
Contents
Mutables¶
-
class
nni.nas.pytorch.mutables.Mutable(key=None)[source]¶ Mutable is designed to function as a normal layer, with all necessary operators’ weights. States and weights of architectures should be included in mutator, instead of the layer itself.
Mutable has a key, which marks the identity of the mutable. This key can be used by users to share decisions among different mutables. In mutator’s implementation, mutators should use the key to distinguish different mutables. Mutables that share the same key should be “similar” to each other.
Currently the default scope for keys is global. By default, the keys uses a global counter from 1 to produce unique ids.
Parameters: key (str) – The key of mutable. Notes
The counter is program level, but mutables are model level. In case multiple models are defined, and you want to have counter starting from 1 in the second model, it’s recommended to assign keys manually instead of using automatic keys.
-
key¶ Read-only property of key.
-
name¶ After the search space is parsed, it will be the module name of the mutable.
-
-
class
nni.nas.pytorch.mutables.LayerChoice(op_candidates, reduction='sum', return_mask=False, key=None)[source]¶ Layer choice selects one of the
op_candidates, then apply it on inputs and return results. In rare cases, it can also select zero or many.Layer choice does not allow itself to be nested.
Parameters: - op_candidates (list of nn.Module or OrderedDict) – A module list to be selected from.
- reduction (str) –
mean,concat,sumornone. Policy if multiples are selected. Ifnone, a list is returned.meanreturns the average.sumreturns the sum.concatconcatenate the list at dimension 1. - return_mask (bool) – If
return_mask, return output tensor and a mask. Otherwise return tensor only. - key (str) – Key of the input choice.
-
length¶ Deprecated. Number of ops to choose from.
len(layer_choice)is recommended.Type: int
-
names¶ Names of candidates.
Type: list of str
-
choices¶ Deprecated. A list of all candidate modules in the layer choice module.
list(layer_choice)is recommended, which will serve the same purpose.Type: list of Module
Notes
op_candidatescan be a list of modules or a ordered dict of named modules, for example,self.op_choice = LayerChoice(OrderedDict([ ("conv3x3", nn.Conv2d(3, 16, 128)), ("conv5x5", nn.Conv2d(5, 16, 128)), ("conv7x7", nn.Conv2d(7, 16, 128)) ]))
Elements in layer choice can be modified or deleted. Use
del self.op_choice["conv5x5"]orself.op_choice[1] = nn.Conv3d(...). Adding more choices is not supported yet.
-
class
nni.nas.pytorch.mutables.InputChoice(n_candidates=None, choose_from=None, n_chosen=None, reduction='sum', return_mask=False, key=None)[source]¶ Input choice selects
n_choseninputs fromchoose_from(containsn_candidateskeys). For beginners, usen_candidatesinstead ofchoose_fromis a safe option. To get the most power out of it, you might want to know aboutchoose_from.The keys in
choose_fromcan be keys that appear in past mutables, orNO_KEYif there are no suitable ones. The keys are designed to be the keys of the sources. To help mutators make better decisions, mutators might be interested in how the tensors to choose from come into place. For example, the tensor is the output of some operator, some node, some cell, or some module. If this operator happens to be a mutable (e.g.,LayerChoiceorInputChoice), it has a key naturally that can be used as a source key. If it’s a module/submodule, it needs to be annotated with a key: that’s where aMutableScopeis needed.In the example below,
input_choiceis a 4-choose-any. The first 3 is semantically output of cell1, output of cell2, output of cell3 with respectively. Notice that an extra max pooling is followed by cell1, indicating x1 is not “actually” the direct output of cell1.class Cell(MutableScope): pass class Net(nn.Module): def __init__(self): self.cell1 = Cell("cell1") self.cell2 = Cell("cell2") self.op = LayerChoice([conv3x3(), conv5x5()], key="op") self.input_choice = InputChoice(choose_from=["cell1", "cell2", "op", InputChoice.NO_KEY]) def forward(self, x): x1 = max_pooling(self.cell1(x)) x2 = self.cell2(x) x3 = self.op(x) x4 = torch.zeros_like(x) return self.input_choice([x1, x2, x3, x4])
Parameters: - n_candidates (int) – Number of inputs to choose from.
- choose_from (list of str) – List of source keys to choose from. At least of one of
choose_fromandn_candidatesmust be fulfilled. Ifn_candidateshas a value butchoose_fromis None, it will be automatically treated asn_candidatesnumber of empty string. - n_chosen (int) – Recommended inputs to choose. If None, mutator is instructed to select any.
- reduction (str) –
mean,concat,sumornone. SeeLayerChoice. - return_mask (bool) – If
return_mask, return output tensor and a mask. Otherwise return tensor only. - key (str) – Key of the input choice.
-
forward(optional_inputs)[source]¶ Forward method of LayerChoice.
Parameters: optional_inputs (list or dict) – Recommended to be a dict. As a dict, inputs will be converted to a list that follows the order of choose_fromin initialization. As a list, inputs must follow the semantic order that is the same aschoose_from.Returns: Output and selection mask. If return_maskisFalse, only output is returned.Return type: tuple of tensors
-
class
nni.nas.pytorch.mutables.MutableScope(key)[source]¶ Mutable scope marks a subgraph/submodule to help mutators make better decisions.
If not annotated with mutable scope, search space will be flattened as a list. However, some mutators might need to leverage the concept of a “cell”. So if a module is defined as a mutable scope, everything in it will look like “sub-search-space” in the scope. Scopes can be nested.
There are two ways mutators can use mutable scope. One is to traverse the search space as a tree during initialization and reset. The other is to implement enter_mutable_scope and exit_mutable_scope. They are called before and after the forward method of the class inheriting mutable scope.
Mutable scopes are also mutables that are listed in the mutator.mutables (search space), but they are not supposed to appear in the dict of choices.
Parameters: key (str) – Key of mutable scope.
Mutators¶
-
class
nni.nas.pytorch.base_mutator.BaseMutator(model)[source]¶ A mutator is responsible for mutating a graph by obtaining the search space from the network and implementing callbacks that are called in
forwardin mutables.Parameters: model (nn.Module) – PyTorch model to apply mutator on. -
enter_mutable_scope(mutable_scope)[source]¶ Callback when forward of a MutableScope is entered.
Parameters: mutable_scope (MutableScope) – The mutable scope that is entered.
-
exit_mutable_scope(mutable_scope)[source]¶ Callback when forward of a MutableScope is exited.
Parameters: mutable_scope (MutableScope) – The mutable scope that is exited.
-
export()[source]¶ Export the data of all decisions. This should output the decisions of all the mutables, so that the whole network can be fully determined with these decisions for further training from scratch.
Returns: Mappings from mutable keys to decisions. Return type: dict
-
mutables¶ A generator of all modules inheriting
Mutable. Modules are yielded in the order that they are defined in__init__. For mutables with their keys appearing multiple times, only the first one will appear.
-
on_forward_input_choice(mutable, tensor_list)[source]¶ Callbacks of forward in InputChoice.
Parameters: - mutable (InputChoice) – Mutable that is called.
- tensor_list (list of torch.Tensor) – The arguments mutable is called with.
Returns: Output tensor and mask.
Return type: tuple of torch.Tensor and torch.Tensor
-
on_forward_layer_choice(mutable, *args, **kwargs)[source]¶ Callbacks of forward in LayerChoice.
Parameters: - mutable (LayerChoice) – Module whose forward is called.
- args (list of torch.Tensor) – The arguments of its forward function.
- kwargs (dict) – The keyword arguments of its forward function.
Returns: Output tensor and mask.
Return type: tuple of torch.Tensor and torch.Tensor
-
-
class
nni.nas.pytorch.mutator.Mutator(model)[source]¶ -
export()[source]¶ Resample (for final) and return results.
Returns: A mapping from key of mutables to decisions. Return type: dict
-
graph(inputs)[source]¶ Return model supernet graph.
Parameters: inputs (tuple of tensor) – Inputs that will be feeded into the network. Returns: Containing node, in Tensorboard GraphDef format. Additional keymutableis a map from key to list of modules.Return type: dict
-
on_forward_input_choice(mutable, tensor_list)[source]¶ On default, this method retrieves the decision obtained previously, and select certain tensors. Then it will reduce the list of all tensor outputs with the policy specified in mutable.reduction.
Parameters: - mutable (InputChoice) – Input choice module.
- tensor_list (list of torch.Tensor) – Tensor list to apply the decision on.
Returns: Output and mask.
Return type: tuple of torch.Tensor and torch.Tensor
-
on_forward_layer_choice(mutable, *args, **kwargs)[source]¶ On default, this method retrieves the decision obtained previously, and select certain operations. Only operations with non-zero weight will be executed. The results will be added to a list. Then it will reduce the list of all tensor outputs with the policy specified in mutable.reduction.
Parameters: - mutable (LayerChoice) – Layer choice module.
- args (list of torch.Tensor) – Inputs
- kwargs (dict) – Inputs
Returns: Output and mask.
Return type: tuple of torch.Tensor and torch.Tensor
-
reset()[source]¶ Reset the mutator by call the sample_search to resample (for search). Stores the result in a local variable so that on_forward_layer_choice and on_forward_input_choice can use the decision directly.
-
sample_final()[source]¶ Override to implement this method to iterate over mutables and make decisions that is final for export and retraining.
Returns: A mapping from key of mutables to decisions. Return type: dict
-
Random Mutator¶
-
class
nni.nas.pytorch.random.RandomMutator(model)[source]¶ Random mutator that samples a random candidate in the search space each time
reset(). It uses random function in PyTorch, so users can set seed in PyTorch to ensure deterministic behavior.-
sample_final()[source]¶ Same as
sample_search().
-
Utilities¶
-
class
nni.nas.pytorch.utils.StructuredMutableTreeNode(mutable)[source]¶ A structured representation of a search space. A search space comes with a root (with None stored in its mutable), and a bunch of children in its children. This tree can be seen as a “flattened” version of the module tree. Since nested mutable entity is not supported yet, the following must be true: each subtree corresponds to a
MutableScopeand each leaf corresponds to aMutable(other thanMutableScope).Parameters: mutable (nni.nas.pytorch.mutables.Mutable) – The mutable that current node is linked with. -
traverse(order='pre', deduplicate=True, memo=None)[source]¶ Return a generator that generates a list of mutables in this tree.
Parameters: - order (str) – pre or post. If pre, current mutable is yield before children. Otherwise after.
- deduplicate (bool) – If true, mutables with the same key will not appear after the first appearance.
- memo (dict) – An auxiliary dict that memorize keys seen before, so that deduplication is possible.
Returns: Return type: generator of Mutable
-
Trainers¶
Trainer¶
-
class
nni.nas.pytorch.base_trainer.BaseTrainer[source]¶
-
class
nni.nas.pytorch.trainer.Trainer(model, mutator, loss, metrics, optimizer, num_epochs, dataset_train, dataset_valid, batch_size, workers, device, log_frequency, callbacks)[source]¶ A trainer with some helper functions implemented. To implement a new trainer, users need to implement
train_one_epoch(),validate_one_epoch()andcheckpoint().Parameters: - model (nn.Module) – Model with mutables.
- mutator (BaseMutator) – A mutator object that has been initialized with the model.
- loss (callable) – Called with logits and targets. Returns a loss tensor. See PyTorch loss functions for examples.
- metrics (callable) –
Called with logits and targets. Returns a dict that maps metrics keys to metrics data. For example,
def metrics_fn(output, target): return {"acc1": accuracy(output, target, topk=1), "acc5": accuracy(output, target, topk=5)}
- optimizer (Optimizer) – Optimizer that optimizes the model.
- num_epochs (int) – Number of epochs of training.
- dataset_train (torch.utils.data.Dataset) – Dataset of training. If not otherwise specified,
dataset_trainanddataset_validshould be standard PyTorch Dataset. See torch.utils.data for examples. - dataset_valid (torch.utils.data.Dataset) – Dataset of validation/testing.
- batch_size (int) – Batch size.
- workers (int) – Number of workers used in data preprocessing.
- device (torch.device) – Device object. Either
torch.device("cuda")ortorch.device("cpu"). WhenNone, trainer will automatic detects GPU and selects GPU first. - log_frequency (int) – Number of mini-batches to log metrics.
- callbacks (list of Callback) – Callbacks to plug into the trainer. See Callbacks.
-
enable_visualization()[source]¶ Enable visualization. Write graph and training log to folder
logs/<timestamp>.
-
export(file)[source]¶ Call
mutator.export()and dump the architecture tofile.Parameters: file (str) – A file path. Expected to be a JSON.
-
train(validate=True)[source]¶ Train
num_epochs. Trigger callbacks at the start and the end of each epoch.Parameters: validate (bool) – If true, will do validation every epoch.
Retrain¶
-
nni.nas.pytorch.fixed.apply_fixed_architecture(model, fixed_arc)[source]¶ Load architecture from fixed_arc and apply to model.
Parameters: - model (torch.nn.Module) – Model with mutables.
- fixed_arc (str or dict) – Path to the JSON that stores the architecture, or dict that stores the exported architecture.
Returns: Mutator that is responsible for fixes the graph.
Return type:
-
class
nni.nas.pytorch.fixed.FixedArchitecture(model, fixed_arc, strict=True)[source]¶ Fixed architecture mutator that always selects a certain graph.
Parameters: - model (nn.Module) – A mutable network.
- fixed_arc (dict) – Preloaded architecture object.
- strict (bool) – Force everything that appears in
fixed_arcto be used at least once.
-
replace_layer_choice(module=None, prefix='')[source]¶ Replace layer choices with selected candidates. It’s done with best effort. In case of weighted choices or multiple choices. if some of the choices on weighted with zero, delete them. If single choice, replace the module with a normal module.
Parameters: - module (nn.Module) – Module to be processed.
- prefix (str) – Module name under global namespace.
Distributed NAS¶
-
nni.nas.pytorch.classic_nas.get_and_apply_next_architecture(model)[source]¶ Wrapper of
ClassicMutatorto make it more meaningful, similar toget_next_parameterfor HPO.Tt will generate search space based on
model. If envNNI_GEN_SEARCH_SPACEexists, this is in dry run mode for generating search space for the experiment. If not, there are still two mode, one is nni experiment mode where users usennictlto start an experiment. The other is standalone mode where users directly run the trial command, this mode chooses the first one(s) for each LayerChoice and InputChoice.Parameters: model (nn.Module) – User’s model with search space (e.g., LayerChoice, InputChoice) embedded in it.
-
class
nni.nas.pytorch.classic_nas.mutator.ClassicMutator(model)[source]¶ This mutator is to apply the architecture chosen from tuner. It implements the forward function of LayerChoice and InputChoice, to only activate the chosen ones.
Parameters: model (nn.Module) – User’s model with search space (e.g., LayerChoice, InputChoice) embedded in it. -
sample_search()[source]¶ See
sample_final().
-
Callbacks¶
-
class
nni.nas.pytorch.callbacks.Callback[source]¶ Callback provides an easy way to react to events like begin/end of epochs.
-
build(model, mutator, trainer)[source]¶ Callback needs to be built with model, mutator, trainer, to get updates from them.
Parameters: - model (nn.Module) – Model to be trained.
- mutator (nn.Module) – Mutator that mutates the model.
- trainer (BaseTrainer) – Trainer that is to call the callback.
-
-
class
nni.nas.pytorch.callbacks.LRSchedulerCallback(scheduler, mode='epoch')[source]¶ Calls scheduler on every epoch ends.
Parameters: scheduler (LRScheduler) – Scheduler to be called.
-
class
nni.nas.pytorch.callbacks.ArchitectureCheckpoint(checkpoint_dir)[source]¶ Calls
trainer.export()on every epoch ends.Parameters: checkpoint_dir (str) – Location to save checkpoints.
Utilities¶
-
class
nni.nas.pytorch.utils.AverageMeterGroup[source]¶ Average meter group for multiple average meters.
Model Compression¶
NNI provides an easy-to-use toolkit to help user design and use compression algorithms. It supports Tensorflow and PyTorch with unified interface. For users to compress their models, they only need to add several lines in their code. There are some popular model compression algorithms built-in in NNI. Users could further use NNI’s auto tuning power to find the best compressed model, which is detailed in Auto Model Compression. On the other hand, users could easily customize their new compression algorithms using NNI’s interface.
For details, please refer to the following tutorials:
Model Compression with NNI¶
Contents
As larger neural networks with more layers and nodes are considered, reducing their storage and computational cost becomes critical, especially for some real-time applications. Model compression can be used to address this problem.
NNI provides a model compression toolkit to help user compress and speed up their model with state-of-the-art compression algorithms and strategies. There are several core features supported by NNI model compression:
- Support many popular pruning and quantization algorithms.
- Automate model pruning and quantization process with state-of-the-art strategies and NNI’s auto tuning power.
- Speed up a compressed model to make it have lower inference latency and also make it become smaller.
- Provide friendly and easy-to-use compression utilities for users to dive into the compression process and results.
- Concise interface for users to customize their own compression algorithms.
Note that the interface and APIs are unified for both PyTorch and TensorFlow, currently only PyTorch version has been supported, TensorFlow version will be supported in future.
Supported Algorithms¶
The algorithms include pruning algorithms and quantization algorithms.
Pruning Algorithms¶
Pruning algorithms compress the original network by removing redundant weights or channels of layers, which can reduce model complexity and address the over-fitting issue.
| Name | Brief Introduction of Algorithm |
|---|---|
| Level Pruner | Pruning the specified ratio on each weight based on absolute values of weights |
| AGP Pruner | Automated gradual pruning (To prune, or not to prune: exploring the efficacy of pruning for model compression) Reference Paper |
| Lottery Ticket Pruner | The pruning process used by "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks". It prunes a model iteratively. Reference Paper |
| FPGM Pruner | Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration Reference Paper |
| L1Filter Pruner | Pruning filters with the smallest L1 norm of weights in convolution layers (Pruning Filters for Efficient Convnets) Reference Paper |
| L2Filter Pruner | Pruning filters with the smallest L2 norm of weights in convolution layers |
| ActivationAPoZRankFilterPruner | Pruning filters based on the metric APoZ (average percentage of zeros) which measures the percentage of zeros in activations of (convolutional) layers. Reference Paper |
| ActivationMeanRankFilterPruner | Pruning filters based on the metric that calculates the smallest mean value of output activations |
| Slim Pruner | Pruning channels in convolution layers by pruning scaling factors in BN layers(Learning Efficient Convolutional Networks through Network Slimming) Reference Paper |
| TaylorFO Pruner | Pruning filters based on the first order taylor expansion on weights(Importance Estimation for Neural Network Pruning) Reference Paper |
| ADMM Pruner | Pruning based on ADMM optimization technique Reference Paper |
| NetAdapt Pruner | Automatically simplify a pretrained network to meet the resource budget by iterative pruning Reference Paper |
| SimulatedAnnealing Pruner | Automatic pruning with a guided heuristic search method, Simulated Annealing algorithm Reference Paper |
| AutoCompress Pruner | Automatic pruning by iteratively call SimulatedAnnealing Pruner and ADMM Pruner Reference Paper |
Quantization Algorithms¶
Quantization algorithms compress the original network by reducing the number of bits required to represent weights or activations, which can reduce the computations and the inference time.
| Name | Brief Introduction of Algorithm |
|---|---|
| Naive Quantizer | Quantize weights to default 8 bits |
| QAT Quantizer | Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. Reference Paper |
| DoReFa Quantizer | DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. Reference Paper |
| BNN Quantizer | Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. Reference Paper |
Automatic Model Compression¶
Given targeted compression ratio, it is pretty hard to obtain the best compressed ratio in a one shot manner. An automatic model compression algorithm usually need to explore the compression space by compressing different layers with different sparsities. NNI provides such algorithms to free users from specifying sparsity of each layer in a model. Moreover, users could leverage NNI’s auto tuning power to automatically compress a model. Detailed document can be found here.
Model Speedup¶
The final goal of model compression is to reduce inference latency and model size. However, existing model compression algorithms mainly use simulation to check the performance (e.g., accuracy) of compressed model, for example, using masks for pruning algorithms, and storing quantized values still in float32 for quantization algorithms. Given the output masks and quantization bits produced by those algorithms, NNI can really speed up the model. The detailed tutorial of Model Speedup can be found here.
Compression Utilities¶
Compression utilities include some useful tools for users to understand and analyze the model they want to compress. For example, users could check sensitivity of each layer to pruning. Users could easily calculate the FLOPs and parameter size of a model. Please refer to here for a complete list of compression utilities.
Customize Your Own Compression Algorithms¶
NNI model compression leaves simple interface for users to customize a new compression algorithm. The design philosophy of the interface is making users focus on the compression logic while hiding framework specific implementation details from users. The detailed tutorial for customizing a new compression algorithm (pruning algorithm or quantization algorithm) can be found here.
Reference and Feedback¶
- To report a bug for this feature in GitHub;
- To file a feature or improvement request for this feature in GitHub;
- To know more about Feature Engineering with NNI;
- To know more about NAS with NNI;
- To know more about Hyperparameter Tuning with NNI;
Tutorial for Model Compression¶
Contents
In this tutorial, we use the first section to quickly go through the usage of model compression on NNI. Then use the second section to explain more details of the usage.
Quick Start to Compress a Model¶
NNI provides very simple APIs for compressing a model. The compression includes pruning algorithms and quantization algorithms. The usage of them are the same, thus, here we use slim pruner as an example to show the usage.
Write configuration¶
Write a configuration to specify the layers that you want to prune. The following configuration means pruning all the BatchNorm2ds to sparsity 0.7 while keeping other layers unpruned.
configure_list = [{
'sparsity': 0.7,
'op_types': ['BatchNorm2d'],
}]
The specification of configuration can be found here. Note that different pruners may have their own defined fields in configuration, for exmaple start_epoch in AGP pruner. Please refer to each pruner’s usage for details, and adjust the configuration accordingly.
Choose a compression algorithm¶
Choose a pruner to prune your model. First instantiate the chosen pruner with your model and configuration as arguments, then invoke compress() to compress your model.
pruner = SlimPruner(model, configure_list)
model = pruner.compress()
Then, you can train your model using traditional training approach (e.g., SGD), pruning is applied transparently during the training. Some pruners prune once at the beginning, the following training can be seen as fine-tune. Some pruners prune your model iteratively, the masks are adjusted epoch by epoch during training.
Export compression result¶
After training, you get accuracy of the pruned model. You can export model weights to a file, and the generated masks to a file as well. Exporting onnx model is also supported.
pruner.export_model(model_path='pruned_vgg19_cifar10.pth', mask_path='mask_vgg19_cifar10.pth')
The complete code of model compression examples can be found here.
Speed up the model¶
Masks do not provide real speedup of your model. The model should be speeded up based on the exported masks, thus, we provide an API to speed up your model as shown below. After invoking apply_compression_results on your model, your model becomes a smaller one with shorter inference latency.
from nni.compression.torch import apply_compression_results
apply_compression_results(model, 'mask_vgg19_cifar10.pth')
Please refer to here for detailed description.
Detailed Usage Guide¶
The example code for users to apply model compression on a user model can be found below:
PyTorch code
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(model, config_list)
pruner.compress()
Tensorflow code
from nni.compression.tensorflow import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(tf.get_default_graph(), config_list)
pruner.compress()
You can use other compression algorithms in the package of nni.compression. The algorithms are implemented in both PyTorch and TensorFlow (partial support on TensorFlow), under nni.compression.torch and nni.compression.tensorflow respectively. You can refer to Pruner and Quantizer for detail description of supported algorithms. Also if you want to use knowledge distillation, you can refer to KDExample
A compression algorithm is first instantiated with a config_list passed in. The specification of this config_list will be described later.
The function call pruner.compress() modifies user defined model (in Tensorflow the model can be obtained with tf.get_default_graph(), while in PyTorch the model is the defined model class), and the model is modified with masks inserted. Then when you run the model, the masks take effect. The masks can be adjusted at runtime by the algorithms.
Note that, pruner.compress simply adds masks on model weights, it does not include fine tuning logic. If users want to fine tune the compressed model, they need to write the fine tune logic by themselves after pruner.compress.
Specification of config_list¶
Users can specify the configuration (i.e., config_list) for a compression algorithm. For example,when compressing a model, users may want to specify the sparsity ratio, to specify different ratios for different types of operations, to exclude certain types of operations, or to compress only a certain types of operations. For users to express these kinds of requirements, we define a configuration specification. It can be seen as a python list object, where each element is a dict object.
The dicts in the list are applied one by one, that is, the configurations in latter dict will overwrite the configurations in former ones on the operations that are within the scope of both of them.
There are different keys in a dict. Some of them are common keys supported by all the compression algorithms:
- op_types: This is to specify what types of operations to be compressed. ‘default’ means following the algorithm’s default setting.
- op_names: This is to specify by name what operations to be compressed. If this field is omitted, operations will not be filtered by it.
- exclude: Default is False. If this field is True, it means the operations with specified types and names will be excluded from the compression.
Some other keys are often specific to a certain algorithms, users can refer to pruning algorithms and quantization algorithms for the keys allowed by each algorithm.
A simple example of configuration is shown below:
[
{
'sparsity': 0.8,
'op_types': ['default']
},
{
'sparsity': 0.6,
'op_names': ['op_name1', 'op_name2']
},
{
'exclude': True,
'op_names': ['op_name3']
}
]
It means following the algorithm’s default setting for compressed operations with sparsity 0.8, but for op_name1 and op_name2 use sparsity 0.6, and do not compress op_name3.
Quantization specific keys¶
If you use quantization algorithms, you need to specify more keys. If you use pruning algorithms, you can safely skip these keys
- quant_types : list of string.
Type of quantization you want to apply, currently support ‘weight’, ‘input’, ‘output’. ‘weight’ means applying quantization operation to the weight parameter of modules. ‘input’ means applying quantization operation to the input of module forward method. ‘output’ means applying quantization operation to the output of module forward method, which is often called as ‘activation’ in some papers.
- quant_bits : int or dict of {str : int}
bits length of quantization, key is the quantization type, value is the quantization bits length, eg.
{
quant_bits: {
'weight': 8,
'output': 4,
},
}
when the value is int type, all quantization types share same bits length. eg.
{
quant_bits: 8, # weight or output quantization are all 8 bits
}
APIs for Updating Fine Tuning Status¶
Some compression algorithms use epochs to control the progress of compression (e.g. AGP), and some algorithms need to do something after every minibatch. Therefore, we provide another two APIs for users to invoke: pruner.update_epoch(epoch) and pruner.step().
update_epoch should be invoked in every epoch, while step should be invoked after each minibatch. Note that most algorithms do not require calling the two APIs. Please refer to each algorithm’s document for details. For the algorithms that do not need them, calling them is allowed but has no effect.
Export Compressed Model¶
You can easily export the compressed model using the following API if you are pruning your model, state_dict of the sparse model weights will be stored in model.pth, which can be loaded by torch.load('model.pth'). In this exported model.pth, the masked weights are zero.
pruner.export_model(model_path='model.pth')
mask_dict and pruned model in onnx format(input_shape need to be specified) can also be exported like this:
pruner.export_model(model_path='model.pth', mask_path='mask.pth', onnx_path='model.onnx', input_shape=[1, 1, 28, 28])
If you want to really speed up the compressed model, please refer to NNI model speedup for details.
Supported Pruning Algorithms on NNI¶
We provide several pruning algorithms that support fine-grained weight pruning and structural filter pruning. Fine-grained Pruning generally results in unstructured models, which need specialized haredware or software to speed up the sparse network. Filter Pruning achieves acceleratation by removing the entire filter. We also provide an algorithm to control the pruning schedule.
Fine-grained Pruning
Filter Pruning
- Slim Pruner
- FPGM Pruner
- L1Filter Pruner
- L2Filter Pruner
- APoZ Rank Pruner
- Activation Mean Rank Pruner
- Taylor FO On Weight Pruner
Pruning Schedule
Others
Level Pruner¶
This is one basic one-shot pruner: you can set a target sparsity level (expressed as a fraction, 0.6 means we will prune 60%).
We first sort the weights in the specified layer by their absolute values. And then mask to zero the smallest magnitude weights until the desired sparsity level is reached.
Usage¶
Tensorflow code
from nni.compression.tensorflow import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(model_graph, config_list)
pruner.compress()
PyTorch code
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(model, config_list)
pruner.compress()
User configuration for Level Pruner¶
- sparsity: This is to specify the sparsity operations to be compressed to
Slim Pruner¶
This is an one-shot pruner, In ‘Learning Efficient Convolutional Networks through Network Slimming’, authors Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan and Changshui Zhang.

Slim Pruner prunes channels in the convolution layers by masking corresponding scaling factors in the later BN layers, L1 regularization on the scaling factors should be applied in batch normalization (BN) layers while training, scaling factors of BN layers are globally ranked while pruning, so the sparse model can be automatically found given sparsity.
Usage¶
PyTorch code
from nni.compression.torch import SlimPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['BatchNorm2d'] }]
pruner = SlimPruner(model, config_list)
pruner.compress()
User configuration for Slim Pruner¶
- sparsity: This is to specify the sparsity operations to be compressed to
- op_types: Only BatchNorm2d is supported in Slim Pruner
Reproduced Experiment¶
We implemented one of the experiments in ‘Learning Efficient Convolutional Networks through Network Slimming’, we pruned $70%$ channels in the VGGNet for CIFAR-10 in the paper, in which $88.5%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
|---|---|---|---|
| VGGNet | 6.34/6.40 | 20.04M | |
| Pruned-VGGNet | 6.20/6.26 | 2.03M | 88.5% |
The experiments code can be found at examples/model_compress
FPGM Pruner¶
This is an one-shot pruner, FPGM Pruner is an implementation of paper Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration
FPGMPruner prune filters with the smallest geometric median

Previous works utilized “smaller-norm-less-important” criterion to prune filters with smaller norm values in a convolutional neural network. In this paper, we analyze this norm-based criterion and point out that its effectiveness depends on two requirements that are not always met: (1) the norm deviation of the filters should be large; (2) the minimum norm of the filters should be small. To solve this problem, we propose a novel filter pruning method, namely Filter Pruning via Geometric Median (FPGM), to compress the model regardless of those two requirements. Unlike previous methods, FPGM compresses CNN models by pruning filters with redundancy, rather than those with “relatively less” importance.
Usage¶
Tensorflow code
from nni.compression.tensorflow import FPGMPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2D']
}]
pruner = FPGMPruner(model, config_list)
pruner.compress()
PyTorch code
from nni.compression.torch import FPGMPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = FPGMPruner(model, config_list)
pruner.compress()
User configuration for FPGM Pruner¶
- sparsity: How much percentage of convolutional filters are to be pruned.
- op_types: Only Conv2d is supported in L1Filter Pruner
L1Filter Pruner¶
This is an one-shot pruner, In ‘PRUNING FILTERS FOR EFFICIENT CONVNETS’, authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.

L1Filter Pruner prunes filters in the convolution layers
The procedure of pruning m filters from the ith convolutional layer is as follows:
- For each filter
, calculate the sum of its absolute kernel weights
- Sort the filters by
.
- Prune
filters with the smallest sum values and their corresponding feature maps. The kernels in the next convolutional layer corresponding to the pruned feature maps are also removed.
- A new kernel matrix is created for both the
th and
th layers, and the remaining kernel weights are copied to the new model.
Usage¶
PyTorch code
from nni.compression.torch import L1FilterPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }]
pruner = L1FilterPruner(model, config_list)
pruner.compress()
User configuration for L1Filter Pruner¶
- sparsity: This is to specify the sparsity operations to be compressed to
- op_types: Only Conv2d is supported in L1Filter Pruner
Reproduced Experiment¶
We implemented one of the experiments in ‘PRUNING FILTERS FOR EFFICIENT CONVNETS’ with L1FilterPruner, we pruned VGG-16 for CIFAR-10 to VGG-16-pruned-A in the paper, in which $64%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
|---|---|---|---|
| VGG-16 | 6.75/6.49 | 1.5x10^7 | |
| VGG-16-pruned-A | 6.60/6.47 | 5.4x10^6 | 64.0% |
The experiments code can be found at examples/model_compress
L2Filter Pruner¶
This is a structured pruning algorithm that prunes the filters with the smallest L2 norm of the weights. It is implemented as a one-shot pruner.
Usage¶
PyTorch code
from nni.compression.torch import L2FilterPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['Conv2d'] }]
pruner = L2FilterPruner(model, config_list)
pruner.compress()
User configuration for L2Filter Pruner¶
- sparsity: This is to specify the sparsity operations to be compressed to
- op_types: Only Conv2d is supported in L2Filter Pruner
ActivationAPoZRankFilterPruner¶
ActivationAPoZRankFilterPruner is a pruner which prunes the filters with the smallest importance criterion APoZ calculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterion APoZ is explained in the paper Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures.
The APoZ is defined as:

Usage¶
PyTorch code
from nni.compression.torch import ActivationAPoZRankFilterPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = ActivationAPoZRankFilterPruner(model, config_list, statistics_batch_num=1)
pruner.compress()
Note: ActivationAPoZRankFilterPruner is used to prune convolutional layers within deep neural networks, therefore the op_types field supports only convolutional layers.
You can view example for more information
User configuration for ActivationAPoZRankFilterPruner¶
- sparsity: How much percentage of convolutional filters are to be pruned.
- op_types: Only Conv2d is supported in ActivationAPoZRankFilterPruner
ActivationMeanRankFilterPruner¶
ActivationMeanRankFilterPruner is a pruner which prunes the filters with the smallest importance criterion mean activation calculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterion mean activation is explained in section 2.2 of the paperPruning Convolutional Neural Networks for Resource Efficient Inference. Other pruning criteria mentioned in this paper will be supported in future release.
Usage¶
PyTorch code
from nni.compression.torch import ActivationMeanRankFilterPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = ActivationMeanRankFilterPruner(model, config_list, statistics_batch_num=1)
pruner.compress()
Note: ActivationMeanRankFilterPruner is used to prune convolutional layers within deep neural networks, therefore the op_types field supports only convolutional layers.
You can view example for more information
User configuration for ActivationMeanRankFilterPruner¶
- sparsity: How much percentage of convolutional filters are to be pruned.
- op_types: Only Conv2d is supported in ActivationMeanRankFilterPruner.
TaylorFOWeightFilterPruner¶
TaylorFOWeightFilterPruner is a pruner which prunes convolutional layers based on estimated importance calculated from the first order taylor expansion on weights to achieve a preset level of network sparsity. The estimated importance of filters is defined as the paper Importance Estimation for Neural Network Pruning. Other pruning criteria mentioned in this paper will be supported in future release.

Usage¶
PyTorch code
from nni.compression.torch import TaylorFOWeightFilterPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = TaylorFOWeightFilterPruner(model, config_list, statistics_batch_num=1)
pruner.compress()
You can view example for more information
User configuration for TaylorFOWeightFilterPruner¶
- sparsity: How much percentage of convolutional filters are to be pruned.
- op_types: Currently only Conv2d is supported in TaylorFOWeightFilterPruner.
AGP Pruner¶
This is an iterative pruner, In To prune, or not to prune: exploring the efficacy of pruning for model compression, authors Michael Zhu and Suyog Gupta provide an algorithm to prune the weight gradually.
We introduce a new automated gradual pruning algorithm in which the sparsity is increased from an initial sparsity value si (usually 0) to a final sparsity value sf over a span of n pruning steps, starting at training step t0 and with pruning frequency ∆t:The binary weight masks are updated every ∆t steps as the network is trained to gradually increase the sparsity of the network while allowing the network training steps to recover from any pruning-induced loss in accuracy. In our experience, varying the pruning frequency ∆t between 100 and 1000 training steps had a negligible impact on the final model quality. Once the model achieves the target sparsity sf , the weight masks are no longer updated. The intuition behind this sparsity function in equation
Usage¶
You can prune all weight from 0% to 80% sparsity in 10 epoch with the code below.
PyTorch code
from nni.compression.torch import AGP_Pruner
config_list = [{
'initial_sparsity': 0,
'final_sparsity': 0.8,
'start_epoch': 0,
'end_epoch': 10,
'frequency': 1,
'op_types': ['default']
}]
# load a pretrained model or train a model before using a pruner
# model = MyModel()
# model.load_state_dict(torch.load('mycheckpoint.pth'))
# AGP pruner prunes model while fine tuning the model by adding a hook on
# optimizer.step(), so an optimizer is required to prune the model.
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
pruner = AGP_Pruner(model, config_list, optimizer, pruning_algorithm='level')
pruner.compress()
AGP pruner uses LevelPruner algorithms to prune the weight by default, however you can set pruning_algorithm parameter to other values to use other pruning algorithms:
level: LevelPrunerslim: SlimPrunerl1: L1FilterPrunerl2: L2FilterPrunerfpgm: FPGMPrunertaylorfo: TaylorFOWeightFilterPrunerapoz: ActivationAPoZRankFilterPrunermean_activation: ActivationMeanRankFilterPruner
You should add code below to update epoch number when you finish one epoch in your training code.
PyTorch code
pruner.update_epoch(epoch)
You can view example for more information
User configuration for AGP Pruner¶
- initial_sparsity: This is to specify the sparsity when compressor starts to compress
- final_sparsity: This is to specify the sparsity when compressor finishes to compress
- start_epoch: This is to specify the epoch number when compressor starts to compress, default start from epoch 0
- end_epoch: This is to specify the epoch number when compressor finishes to compress
- frequency: This is to specify every frequency number epochs compressor compress once, default frequency=1
NetAdapt Pruner¶
NetAdapt allows a user to automatically simplify a pretrained network to meet the resource budget. Given the overall sparsity, NetAdapt will automatically generate the sparsities distribution among different layers by iterative pruning.
For more details, please refer to NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications.

Usage¶
PyTorch code
from nni.compression.torch import NetAdaptPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = NetAdaptPruner(model, config_list, short_term_fine_tuner=short_term_fine_tuner, evaluator=evaluator,base_algo='l1', experiment_data_dir='./')
pruner.compress()
You can view example for more information.
User configuration for NetAdapt Pruner¶
sparsity: The target overall sparsity.
op_types: The operation type to prune. If
base_algoisl1orl2, then onlyConv2dis supported asop_types.short_term_fine_tuner: Function to short-term fine tune the masked model. This function should include
modelas the only parameter, and fine tune the model for a short term after each pruning iteration.Example:
>>> def short_term_fine_tuner(model, epoch=3): >>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") >>> train_loader = ... >>> criterion = torch.nn.CrossEntropyLoss() >>> optimizer = torch.optim.SGD(model.parameters(), lr=0.01) >>> model.train() >>> for _ in range(epoch): >>> for batch_idx, (data, target) in enumerate(train_loader): >>> data, target = data.to(device), target.to(device) >>> optimizer.zero_grad() >>> output = model(data) >>> loss = criterion(output, target) >>> loss.backward() >>> optimizer.step()
evaluator: Function to evaluate the masked model. This function should include
modelas the only parameter, and returns a scalar value.Example::
>>> def evaluator(model): >>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") >>> val_loader = ... >>> model.eval() >>> correct = 0 >>> with torch.no_grad(): >>> for data, target in val_loader: >>> data, target = data.to(device), target.to(device) >>> output = model(data) >>> # get the index of the max log-probability >>> pred = output.argmax(dim=1, keepdim=True) >>> correct += pred.eq(target.view_as(pred)).sum().item() >>> accuracy = correct / len(val_loader.dataset) >>> return accuracy
optimize_mode: Optimize mode,
maximizeorminimize, by defaultmaximize.base_algo: Base pruning algorithm.
level,l1orl2, by defaultl1. Given the sparsity distribution among the ops, the assignedbase_algois used to decide which filters/channels/weights to prune.sparsity_per_iteration: The sparsity to prune in each iteration. NetAdapt Pruner prune the model by the same level in each iteration to meet the resource budget progressively.
experiment_data_dir: PATH to save experiment data, including the config_list generated for the base pruning algorithm and the performance of the pruned model.
SimulatedAnnealing Pruner¶
We implement a guided heuristic search method, Simulated Annealing (SA) algorithm, with enhancement on guided search based on prior experience. The enhanced SA technique is based on the observation that a DNN layer with more number of weights often has a higher degree of model compression with less impact on overall accuracy.
- Randomly initialize a pruning rate distribution (sparsities).
- While current_temperature < stop_temperature:
- generate a perturbation to current distribution
- Perform fast evaluation on the perturbated distribution
- accept the perturbation according to the performance and probability, if not accepted, return to step 1
- cool down, current_temperature <- current_temperature * cool_down_rate
For more details, please refer to AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates.
Usage¶
PyTorch code
from nni.compression.torch import SimulatedAnnealingPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = SimulatedAnnealingPruner(model, config_list, evaluator=evaluator, base_algo='l1', cool_down_rate=0.9, experiment_data_dir='./')
pruner.compress()
You can view example for more information.
User configuration for SimulatedAnnealing Pruner¶
sparsity: The target overall sparsity.
op_types: The operation type to prune. If
base_algoisl1orl2, then onlyConv2dis supported asop_types.evaluator: Function to evaluate the masked model. This function should include
modelas the only parameter, and returns a scalar value. Example::>>> def evaluator(model): >>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") >>> val_loader = ... >>> model.eval() >>> correct = 0 >>> with torch.no_grad(): >>> for data, target in val_loader: >>> data, target = data.to(device), target.to(device) >>> output = model(data) >>> # get the index of the max log-probability >>> pred = output.argmax(dim=1, keepdim=True) >>> correct += pred.eq(target.view_as(pred)).sum().item() >>> accuracy = correct / len(val_loader.dataset) >>> return accuracy
optimize_mode: Optimize mode,
maximizeorminimize, by defaultmaximize.base_algo: Base pruning algorithm.
level,l1orl2, by defaultl1. Given the sparsity distribution among the ops, the assignedbase_algois used to decide which filters/channels/weights to prune.start_temperature: Simualated Annealing related parameter.
stop_temperature: Simualated Annealing related parameter.
cool_down_rate: Simualated Annealing related parameter.
perturbation_magnitude: Initial perturbation magnitude to the sparsities. The magnitude decreases with current temperature.
experiment_data_dir: PATH to save experiment data, including the config_list generated for the base pruning algorithm, the performance of the pruned model and the pruning history.
AutoCompress Pruner¶
For each round, AutoCompressPruner prune the model for the same sparsity to achive the overall sparsity:
1. Generate sparsities distribution using SimualtedAnnealingPruner
2. Perform ADMM-based structured pruning to generate pruning result for the next round.
Here we use speedup to perform real pruning.
For more details, please refer to AutoCompress: An Automatic DNN Structured Pruning Framework for Ultra-High Compression Rates.
Usage¶
PyTorch code
from nni.compression.torch import ADMMPruner
config_list = [{
'sparsity': 0.5,
'op_types': ['Conv2d']
}]
pruner = AutoCompressPruner(
model, config_list, trainer=trainer, evaluator=evaluator,
dummy_input=dummy_input, num_iterations=3, optimize_mode='maximize', base_algo='l1',
cool_down_rate=0.9, admm_num_iterations=30, admm_training_epochs=5, experiment_data_dir='./')
pruner.compress()
You can view example for more information.
User configuration for AutoCompress Pruner¶
sparsity: The target overall sparsity.
op_types: The operation type to prune. If
base_algoisl1orl2, then onlyConv2dis supported asop_types.trainer: Function used for the first subproblem. Users should write this function as a normal function to train the Pytorch model and include
model, optimizer, criterion, epoch, callbackas function arguments. Herecallbackacts as an L2 regulizer as presented in the formula (7) of the original paper. The logic ofcallbackis implemented inside the Pruner, users are just required to insertcallback()betweenloss.backward()andoptimizer.step(). Example:>>> def trainer(model, criterion, optimizer, epoch, callback): >>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") >>> train_loader = ... >>> model.train() >>> for batch_idx, (data, target) in enumerate(train_loader): >>> data, target = data.to(device), target.to(device) >>> optimizer.zero_grad() >>> output = model(data) >>> loss = criterion(output, target) >>> loss.backward() >>> # callback should be inserted between loss.backward() and optimizer.step() >>> if callback: >>> callback() >>> optimizer.step()
evaluator: Function to evaluate the masked model. This function should include
modelas the only parameter, and returns a scalar value. Example::>>> def evaluator(model): >>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") >>> val_loader = ... >>> model.eval() >>> correct = 0 >>> with torch.no_grad(): >>> for data, target in val_loader: >>> data, target = data.to(device), target.to(device) >>> output = model(data) >>> # get the index of the max log-probability >>> pred = output.argmax(dim=1, keepdim=True) >>> correct += pred.eq(target.view_as(pred)).sum().item() >>> accuracy = correct / len(val_loader.dataset) >>> return accuracy
dummy_input: The dummy input for model speed up, users should put it on right device before pass in.
iterations: The number of overall iterations.
optimize_mode: Optimize mode,
maximizeorminimize, by defaultmaximize.base_algo: Base pruning algorithm.
level,l1orl2, by defaultl1. Given the sparsity distribution among the ops, the assignedbase_algois used to decide which filters/channels/weights to prune.start_temperature: Simualated Annealing related parameter.
stop_temperature: Simualated Annealing related parameter.
cool_down_rate: Simualated Annealing related parameter.
perturbation_magnitude: Initial perturbation magnitude to the sparsities. The magnitude decreases with current temperature.
admm_num_iterations: Number of iterations of ADMM Pruner.
admm_training_epochs: Training epochs of the first optimization subproblem of ADMMPruner.
experiment_data_dir: PATH to store temporary experiment data.
ADMM Pruner¶
Alternating Direction Method of Multipliers (ADMM) is a mathematical optimization technique, by decomposing the original nonconvex problem into two subproblems that can be solved iteratively. In weight pruning problem, these two subproblems are solved via 1) gradient descent algorithm and 2) Euclidean projection respectively.
During the process of solving these two subproblems, the weights of the original model will be changed. An one-shot pruner will then be applied to prune the model according to the config list given.
This solution framework applies both to non-structured and different variations of structured pruning schemes.
For more details, please refer to A Systematic DNN Weight Pruning Framework using Alternating Direction Method of Multipliers.
Usage¶
PyTorch code
from nni.compression.torch import ADMMPruner
config_list = [{
'sparsity': 0.8,
'op_types': ['Conv2d'],
'op_names': ['conv1']
}, {
'sparsity': 0.92,
'op_types': ['Conv2d'],
'op_names': ['conv2']
}]
pruner = ADMMPruner(model, config_list, trainer=trainer, num_iterations=30, epochs=5)
pruner.compress()
You can view example for more information.
User configuration for ADMM Pruner¶
sparsity: This is to specify the sparsity operations to be compressed to.
op_types: The operation type to prune. If
base_algoisl1orl2, then onlyConv2dis supported asop_types.trainer: Function used for the first subproblem in ADMM optimization, attention, this is not used for fine-tuning. Users should write this function as a normal function to train the Pytorch model and include
model, optimizer, criterion, epoch, callbackas function arguments. Herecallbackacts as an L2 regulizer as presented in the formula (7) of the original paper. The logic ofcallbackis implemented inside the Pruner, users are just required to insertcallback()betweenloss.backward()andoptimizer.step().Example:
>>> def trainer(model, criterion, optimizer, epoch, callback): >>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") >>> train_loader = ... >>> model.train() >>> for batch_idx, (data, target) in enumerate(train_loader): >>> data, target = data.to(device), target.to(device) >>> optimizer.zero_grad() >>> output = model(data) >>> loss = criterion(output, target) >>> loss.backward() >>> # callback should be inserted between loss.backward() and optimizer.step() >>> if callback: >>> callback() >>> optimizer.step()
num_iterations: Total number of iterations.
training_epochs: Training epochs of the first subproblem.
row: Penalty parameters for ADMM training.
base_algo: Base pruning algorithm.
level,l1orl2, by defaultl1. Given the sparsity distribution among the ops, the assignedbase_algois used to decide which filters/channels/weights to prune.
Lottery Ticket Hypothesis¶
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, authors Jonathan Frankle and Michael Carbin,provides comprehensive measurement and analysis, and articulate the lottery ticket hypothesis: dense, randomly-initialized, feed-forward networks contain subnetworks (winning tickets) that – when trained in isolation – reach test accuracy comparable to the original network in a similar number of iterations.
In this paper, the authors use the following process to prune a model, called iterative prunning:
- Randomly initialize a neural network f(x;theta_0) (where theta_0 follows D_{theta}).
- Train the network for j iterations, arriving at parameters theta_j.
- Prune p% of the parameters in theta_j, creating a mask m.
- Reset the remaining parameters to their values in theta_0, creating the winning ticket f(x;m*theta_0).
- Repeat step 2, 3, and 4.
If the configured final sparsity is P (e.g., 0.8) and there are n times iterative pruning, each iterative pruning prunes 1-(1-P)^(1/n) of the weights that survive the previous round.
Usage¶
PyTorch code
from nni.compression.torch import LotteryTicketPruner
config_list = [{
'prune_iterations': 5,
'sparsity': 0.8,
'op_types': ['default']
}]
pruner = LotteryTicketPruner(model, config_list, optimizer)
pruner.compress()
for _ in pruner.get_prune_iterations():
pruner.prune_iteration_start()
for epoch in range(epoch_num):
...
The above configuration means that there are 5 times of iterative pruning. As the 5 times iterative pruning are executed in the same run, LotteryTicketPruner needs model and optimizer (Note that should add lr_scheduler if used) to reset their states every time a new prune iteration starts. Please use get_prune_iterations to get the pruning iterations, and invoke prune_iteration_start at the beginning of each iteration. epoch_num is better to be large enough for model convergence, because the hypothesis is that the performance (accuracy) got in latter rounds with high sparsity could be comparable with that got in the first round.
Tensorflow version will be supported later.
User configuration for LotteryTicketPruner¶
- prune_iterations: The number of rounds for the iterative pruning, i.e., the number of iterative pruning.
- sparsity: The final sparsity when the compression is done.
Reproduced Experiment¶
We try to reproduce the experiment result of the fully connected network on MNIST using the same configuration as in the paper. The code can be referred here. In this experiment, we prune 10 times, for each pruning we train the pruned model for 50 epochs.

The above figure shows the result of the fully connected network. round0-sparsity-0.0 is the performance without pruning. Consistent with the paper, pruning around 80% also obtain similar performance compared to non-pruning, and converges a little faster. If pruning too much, e.g., larger than 94%, the accuracy becomes lower and convergence becomes a little slower. A little different from the paper, the trend of the data in the paper is relatively more clear.
Supported Quantization Algorithms on NNI¶
Index of supported quantization algorithms
Naive Quantizer¶
We provide Naive Quantizer to quantizer weight to default 8 bits, you can use it to test quantize algorithm without any configure.
QAT Quantizer¶
In Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference, authors Benoit Jacob and Skirmantas Kligys provide an algorithm to quantize the model with training.
We propose an approach that simulates quantization effects in the forward pass of training. Backpropagation still happens as usual, and all weights and biases are stored in floating point so that they can be easily nudged by small amounts. The forward propagation pass however simulates quantized inference as it will happen in the inference engine, by implementing in floating-point arithmetic the rounding behavior of the quantization scheme
- Weights are quantized before they are convolved with the input. If batch normalization (see [17]) is used for the layer, the batch normalization parameters are “folded into” the weights before quantization.
- Activations are quantized at points where they would be during inference, e.g. after the activation function is applied to a convolutional or fully connected layer’s output, or after a bypass connection adds or concatenates the outputs of several layers together such as in ResNets.
Usage¶
You can quantize your model to 8 bits with the code below before your training code.
PyTorch code
from nni.compression.torch import QAT_Quantizer
model = Mnist()
config_list = [{
'quant_types': ['weight'],
'quant_bits': {
'weight': 8,
}, # you can just use `int` here because all `quan_types` share same bits length, see config for `ReLu6` below.
'op_types':['Conv2d', 'Linear']
}, {
'quant_types': ['output'],
'quant_bits': 8,
'quant_start_step': 7000,
'op_types':['ReLU6']
}]
quantizer = QAT_Quantizer(model, config_list)
quantizer.compress()
You can view example for more information
User configuration for QAT Quantizer¶
common configuration needed by compression algorithms can be found at Specification of config_list.
configuration needed by this algorithm :
- quant_start_step: int
disable quantization until model are run by certain number of steps, this allows the network to enter a more stable state where activation quantization ranges do not exclude a significant fraction of values, default value is 0
note¶
batch normalization folding is currently not supported.
DoReFa Quantizer¶
In DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients, authors Shuchang Zhou and Yuxin Wu provide an algorithm named DoReFa to quantize the weight, activation and gradients with training.
Usage¶
To implement DoReFa Quantizer, you can add code below before your training code
PyTorch code
from nni.compression.torch import DoReFaQuantizer
config_list = [{
'quant_types': ['weight'],
'quant_bits': 8,
'op_types': 'default'
}]
quantizer = DoReFaQuantizer(model, config_list)
quantizer.compress()
You can view example for more information
User configuration for DoReFa Quantizer¶
common configuration needed by compression algorithms can be found at Specification of config_list.
configuration needed by this algorithm :
BNN Quantizer¶
We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time. At training-time the binary weights and activations are used for computing the parameters gradients. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which is expected to substantially improve power-efficiency.
Usage¶
PyTorch code
from nni.compression.torch import BNNQuantizer
model = VGG_Cifar10(num_classes=10)
configure_list = [{
'quant_bits': 1,
'quant_types': ['weight'],
'op_types': ['Conv2d', 'Linear'],
'op_names': ['features.0', 'features.3', 'features.7', 'features.10', 'features.14', 'features.17', 'classifier.0', 'classifier.3']
}, {
'quant_bits': 1,
'quant_types': ['output'],
'op_types': ['Hardtanh'],
'op_names': ['features.6', 'features.9', 'features.13', 'features.16', 'features.20', 'classifier.2', 'classifier.5']
}]
quantizer = BNNQuantizer(model, configure_list)
model = quantizer.compress()
You can view example examples/model_compress/BNN_quantizer_cifar10.py for more information.
User configuration for BNN Quantizer¶
common configuration needed by compression algorithms can be found at Specification of config_list.
configuration needed by this algorithm :
Experiment¶
We implemented one of the experiments in Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1, we quantized the VGGNet for CIFAR-10 in the paper. Our experiments results are as follows:
| Model | Accuracy |
|---|---|
| VGGNet | 86.93% |
The experiments code can be found at examples/model_compress/BNN_quantizer_cifar10.py
Automatic Model Compression on NNI¶
It’s convenient to implement auto model compression with NNI compression and NNI tuners
First, model compression with NNI¶
You can easily compress a model with NNI compression. Take pruning for example, you can prune a pretrained model with LevelPruner like this
from nni.compression.torch import LevelPruner
config_list = [{ 'sparsity': 0.8, 'op_types': ['default'] }]
pruner = LevelPruner(model, config_list)
pruner.compress()
The ‘default’ op_type stands for the module types defined in default_layers.py for pytorch.
Therefore { 'sparsity': 0.8, 'op_types': ['default'] }means that all layers with specified op_types will be compressed with the same 0.8 sparsity. When pruner.compress() called, the model is compressed with masks and after that you can normally fine tune this model and pruned weights won’t be updated which have been masked.
Then, make this automatic¶
The previous example manually choosed LevelPruner and pruned all layers with the same sparsity, this is obviously sub-optimal because different layers may have different redundancy. Layer sparsity should be carefully tuned to achieve least model performance degradation and this can be done with NNI tuners.
The first thing we need to do is to design a search space, here we use a nested search space which contains choosing pruning algorithm and optimizing layer sparsity.
{
"prune_method": {
"_type": "choice",
"_value": [
{
"_name": "agp",
"conv0_sparsity": {
"_type": "uniform",
"_value": [
0.1,
0.9
]
},
"conv1_sparsity": {
"_type": "uniform",
"_value": [
0.1,
0.9
]
},
},
{
"_name": "level",
"conv0_sparsity": {
"_type": "uniform",
"_value": [
0.1,
0.9
]
},
"conv1_sparsity": {
"_type": "uniform",
"_value": [
0.01,
0.9
]
},
}
]
}
}
Then we need to modify our codes for few lines
import nni
from nni.compression.torch import *
params = nni.get_parameters()
conv0_sparsity = params['prune_method']['conv0_sparsity']
conv1_sparsity = params['prune_method']['conv1_sparsity']
# these raw sparsity should be scaled if you need total sparsity constrained
config_list_level = [{ 'sparsity': conv0_sparsity, 'op_name': 'conv0' },
{ 'sparsity': conv1_sparsity, 'op_name': 'conv1' }]
config_list_agp = [{'initial_sparsity': 0, 'final_sparsity': conv0_sparsity,
'start_epoch': 0, 'end_epoch': 3,
'frequency': 1,'op_name': 'conv0' },
{'initial_sparsity': 0, 'final_sparsity': conv1_sparsity,
'start_epoch': 0, 'end_epoch': 3,
'frequency': 1,'op_name': 'conv1' },]
PRUNERS = {'level':LevelPruner(model, config_list_level), 'agp':AGP_Pruner(model, config_list_agp)}
pruner = PRUNERS(params['prune_method']['_name'])
pruner.compress()
... # fine tuning
acc = evaluate(model) # evaluation
nni.report_final_results(acc)
Last, define our task and automatically tuning pruning methods with layers sparsity
authorName: default
experimentName: Auto_Compression
trialConcurrency: 2
maxExecDuration: 100h
maxTrialNum: 500
#choice: local, remote, pai
trainingServicePlatform: local
#choice: true, false
useAnnotation: False
searchSpacePath: search_space.json
tuner:
#choice: TPE, Random, Anneal...
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: bash run_prune.sh
codeDir: .
gpuNum: 1
Speed up Masked Model¶
This feature is in Beta version.
Introduction¶
Pruning algorithms usually use weight masks to simulate the real pruning. Masks can be used to check model performance of a specific pruning (or sparsity), but there is no real speedup. Since model speedup is the ultimate goal of model pruning, we try to provide a tool to users to convert a model to a smaller one based on user provided masks (the masks come from the pruning algorithms).
There are two types of pruning. One is fine-grained pruning, it does not change the shape of weights, and input/output tensors. Sparse kernel is required to speed up a fine-grained pruned layer. The other is coarse-grained pruning (e.g., channels), shape of weights and input/output tensors usually change due to such pruning. To speed up this kind of pruning, there is no need to use sparse kernel, just replace the pruned layer with smaller one. Since the support of sparse kernels in community is limited, we only support the speedup of coarse-grained pruning and leave the support of fine-grained pruning in future.
Design and Implementation¶
To speed up a model, the pruned layers should be replaced, either replaced with smaller layer for coarse-grained mask, or replaced with sparse kernel for fine-grained mask. Coarse-grained mask usually changes the shape of weights or input/output tensors, thus, we should do shape inference to check are there other unpruned layers should be replaced as well due to shape change. Therefore, in our design, there are two main steps: first, do shape inference to find out all the modules that should be replaced; second, replace the modules. The first step requires topology (i.e., connections) of the model, we use jit.trace to obtain the model graph for PyTorch.
For each module, we should prepare four functions, three for shape inference and one for module replacement. The three shape inference functions are: given weight shape infer input/output shape, given input shape infer weight/output shape, given output shape infer weight/input shape. The module replacement function returns a newly created module which is smaller.
Usage¶
from nni.compression.torch import ModelSpeedup
# model: the model you want to speed up
# dummy_input: dummy input of the model, given to `jit.trace`
# masks_file: the mask file created by pruning algorithms
m_speedup = ModelSpeedup(model, dummy_input.to(device), masks_file)
m_speedup.speedup_model()
dummy_input = dummy_input.to(device)
start = time.time()
out = model(dummy_input)
print('elapsed time: ', time.time() - start)
For complete examples please refer to the code
NOTE: The current implementation supports PyTorch 1.3.1 or newer.
Limitations¶
Since every module requires four functions for shape inference and module replacement, this is a large amount of work, we only implemented the ones that are required by the examples. If you want to speed up your own model which cannot supported by the current implementation, you are welcome to contribute.
For PyTorch we can only replace modules, if functions in forward should be replaced, our current implementation does not work. One workaround is make the function a PyTorch module.
Speedup Results of Examples¶
The code of these experiments can be found here.
slim pruner example¶
on one V100 GPU,
input tensor: torch.randn(64, 3, 32, 32)
| Times | Mask Latency | Speedup Latency |
|---|---|---|
| 1 | 0.01197 | 0.005107 |
| 2 | 0.02019 | 0.008769 |
| 4 | 0.02733 | 0.014809 |
| 8 | 0.04310 | 0.027441 |
| 16 | 0.07731 | 0.05008 |
| 32 | 0.14464 | 0.10027 |
fpgm pruner example¶
on cpu,
input tensor: torch.randn(64, 1, 28, 28),
too large variance
| Times | Mask Latency | Speedup Latency |
|---|---|---|
| 1 | 0.01383 | 0.01839 |
| 2 | 0.01167 | 0.003558 |
| 4 | 0.01636 | 0.01088 |
| 40 | 0.14412 | 0.08268 |
| 40 | 1.29385 | 0.14408 |
| 40 | 0.41035 | 0.46162 |
| 400 | 6.29020 | 5.82143 |
l1filter pruner example¶
on one V100 GPU,
input tensor: torch.randn(64, 3, 32, 32)
| Times | Mask Latency | Speedup Latency |
|---|---|---|
| 1 | 0.01026 | 0.003677 |
| 2 | 0.01657 | 0.008161 |
| 4 | 0.02458 | 0.020018 |
| 8 | 0.03498 | 0.025504 |
| 16 | 0.06757 | 0.047523 |
| 32 | 0.10487 | 0.086442 |
APoZ pruner example¶
on one V100 GPU,
input tensor: torch.randn(64, 3, 32, 32)
| Times | Mask Latency | Speedup Latency |
|---|---|---|
| 1 | 0.01389 | 0.004208 |
| 2 | 0.01628 | 0.008310 |
| 4 | 0.02521 | 0.014008 |
| 8 | 0.03386 | 0.023923 |
| 16 | 0.06042 | 0.046183 |
| 32 | 0.12421 | 0.087113 |
Analysis Utils for Model Compression¶
Contents
We provide several easy-to-use tools for users to analyze their model during model compression.
Sensitivity Analysis¶
First, we provide a sensitivity analysis tool (SensitivityAnalysis) for users to analyze the sensitivity of each convolutional layer in their model. Specifically, the SensitiviyAnalysis gradually prune each layer of the model, and test the accuracy of the model at the same time. Note that, SensitivityAnalysis only prunes a layer once a time, and the other layers are set to their original weights. According to the accuracies of different convolutional layers under different sparsities, we can easily find out which layers the model accuracy is more sensitive to.
Usage¶
The following codes show the basic usage of the SensitivityAnalysis.
from nni.compression.torch.utils.sensitivity_analysis import SensitivityAnalysis
def val(model):
model.eval()
total = 0
correct = 0
with torch.no_grad():
for batchid, (data, label) in enumerate(val_loader):
data, label = data.cuda(), label.cuda()
out = model(data)
_, predicted = out.max(1)
total += data.size(0)
correct += predicted.eq(label).sum().item()
return correct / total
s_analyzer = SensitivityAnalysis(model=net, val_func=val)
sensitivity = s_analyzer.analysis(val_args=[net])
os.makedir(outdir)
s_analyzer.export(os.path.join(outdir, filename))
Two key parameters of SensitivityAnalysis are model, and val_func. model is the neural network that to be analyzed and the val_func is the validation function that returns the model accuracy/loss/ or other metrics on the validation dataset. Due to different scenarios may have different ways to calculate the loss/accuracy, so users should prepare a function that returns the model accuracy/loss on the dataset and pass it to SensitivityAnalysis.
SensitivityAnalysis can export the sensitivity results as a csv file usage is shown in the example above.
Futhermore, users can specify the sparsities values used to prune for each layer by optional parameter sparsities.
s_analyzer = SensitivityAnalysis(model=net, val_func=val, sparsities=[0.25, 0.5, 0.75])
the SensitivityAnalysis will prune 25% 50% 75% weights gradually for each layer, and record the model’s accuracy at the same time (SensitivityAnalysis only prune a layer once a time, the other layers are set to their original weights). If the sparsities is not set, SensitivityAnalysis will use the numpy.arange(0.1, 1.0, 0.1) as the default sparsity values.
Users can also speed up the progress of sensitivity analysis by the early_stop_mode and early_stop_value option. By default, the SensitivityAnalysis will test the accuracy under all sparsities for each layer. In contrast, when the early_stop_mode and early_stop_value are set, the sensitivity analysis for a layer will stop, when the accuracy/loss has already met the threshold set by early_stop_value. We support four early stop modes: minimize, maximize, dropped, raised.
minimize: The analysis stops when the validation metric return by the val_func lower than early_stop_value.
maximize: The analysis stops when the validation metric return by the val_func larger than early_stop_value.
dropped: The analysis stops when the validation metric has dropped by early_stop_value.
raised: The analysis stops when the validation metric has raised by early_stop_value.
s_analyzer = SensitivityAnalysis(model=net, val_func=val, sparsities=[0.25, 0.5, 0.75], early_stop_mode='dropped', early_stop_value=0.1)
If users only want to analyze several specified convolutional layers, users can specify the target conv layers by the specified_layers in analysis function. specified_layers is a list that consists of the Pytorch module names of the conv layers. For example
sensitivity = s_analyzer.analysis(val_args=[net], specified_layers=['Conv1'])
In this example, only the Conv1 layer is analyzed. In addtion, users can quickly and easily achieve the analysis parallelization by launching multiple processes and assigning different conv layers of the same model to each process.
Output example¶
The following lines are the example csv file exported from SensitivityAnalysis. The first line is constructed by ‘layername’ and sparsity list. Here the sparsity value means how much weight SensitivityAnalysis prune for each layer. Each line below records the model accuracy when this layer is under different sparsities. Note that, due to the early_stop option, some layers may not have model accuracies/losses under all sparsities, for example, its accuracy drop has already exceeded the threshold set by the user.
layername,0.05,0.1,0.2,0.3,0.4,0.5,0.7,0.85,0.95
features.0,0.54566,0.46308,0.06978,0.0374,0.03024,0.01512,0.00866,0.00492,0.00184
features.3,0.54878,0.51184,0.37978,0.19814,0.07178,0.02114,0.00438,0.00442,0.00142
features.6,0.55128,0.53566,0.4887,0.4167,0.31178,0.19152,0.08612,0.01258,0.00236
features.8,0.55696,0.54194,0.48892,0.42986,0.33048,0.2266,0.09566,0.02348,0.0056
features.10,0.55468,0.5394,0.49576,0.4291,0.3591,0.28138,0.14256,0.05446,0.01578
Topology Analysis¶
We also provide several tools for the topology analysis during the model compression. These tools are to help users compress their model better. Because of the complex topology of the network, when compressing the model, users often need to spend a lot of effort to check whether the compression configuration is reasonable. So we provide these tools for topology analysis to reduce the burden on users.
ChannelDependency¶
Complicated models may have residual connection/concat operations in their models. When the user prunes these models, they need to be careful about the channel-count dependencies between the convolution layers in the model. Taking the following residual block in the resnet18 as an example. The output features of the layer2.0.conv2 and layer2.0.downsample.0 are added together, so the number of the output channels of layer2.0.conv2 and layer2.0.downsample.0 should be the same, or there may be a tensor shape conflict.

If the layers have channel dependency are assigned with different sparsities (here we only discuss the structured pruning by L1FilterPruner/L2FilterPruner), then there will be a shape conflict during these layers. Even the pruned model with mask works fine, the pruned model cannot be speedup to the final model directly that runs on the devices, because there will be a shape conflict when the model tries to add/concat the outputs of these layers. This tool is to find the layers that have channel count dependencies to help users better prune their model.
Usage¶
from nni.compression.torch.utils.shape_dependency import ChannelDependency
data = torch.ones(1, 3, 224, 224).cuda()
channel_depen = ChannelDependency(net, data)
channel_depen.export('dependency.csv')
Output Example¶
The following lines are the output example of torchvision.models.resnet18 exported by ChannelDependency. The layers at the same line have output channel dependencies with each other. For example, layer1.1.conv2, conv1, and layer1.0.conv2 have output channel dependencies with each other, which means the output channel(filters) numbers of these three layers should be same with each other, otherwise, the model may have shape conflict.
Dependency Set,Convolutional Layers
Set 1,layer1.1.conv2,layer1.0.conv2,conv1
Set 2,layer1.0.conv1
Set 3,layer1.1.conv1
Set 4,layer2.0.conv1
Set 5,layer2.1.conv2,layer2.0.conv2,layer2.0.downsample.0
Set 6,layer2.1.conv1
Set 7,layer3.0.conv1
Set 8,layer3.0.downsample.0,layer3.1.conv2,layer3.0.conv2
Set 9,layer3.1.conv1
Set 10,layer4.0.conv1
Set 11,layer4.0.downsample.0,layer4.1.conv2,layer4.0.conv2
Set 12,layer4.1.conv1
MaskConflict¶
When the masks of different layers in a model have conflict (for example, assigning different sparsities for the layers that have channel dependency), we can fix the mask conflict by MaskConflict. Specifically, the MaskConflict loads the masks exported by the pruners(L1FilterPruner, etc), and check if there is mask conflict, if so, MaskConflict sets the conflicting masks to the same value.
from nni.compression.torch.utils.mask_conflict import fix_mask_conflict
fixed_mask = fix_mask_conflict('./resnet18_mask', net, data)
Model FLOPs/Parameters Counter¶
We provide a model counter for calculating the model FLOPs and parameters. This counter supports calculating FLOPs/parameters of a normal model without masks, it can also calculates FLOPs/parameters of a model with mask wrappers, which helps users easily check model complexity during model compression on NNI. Note that, for sturctured pruning, we only identify the remained filters according to its mask, which not taking the pruned input channels into consideration, so the calculated FLOPs will be larger than real number (i.e., the number calculated after Model Speedup).
Framework overview of model compression¶
Contents
Below picture shows the components overview of model compression framework.

There are 3 major components/classes in NNI model compression framework: Compressor, Pruner and Quantizer. Let’s look at them in detail one by one:
Compressor¶
Compressor is the base class for pruner and quntizer, it provides a unified interface for pruner and quantizer for end users, so that pruner and quantizer can be used in the same way. For example, to use a pruner:
from nni.compression.torch import LevelPruner
# load a pretrained model or train a model before using a pruner
configure_list = [{
'sparsity': 0.7,
'op_types': ['Conv2d', 'Linear'],
}]
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
pruner = LevelPruner(model, configure_list, optimizer)
model = pruner.compress()
# model is ready for pruning, now start finetune the model,
# the model will be pruned during training automatically
To use a quantizer:
from nni.compression.torch import DoReFaQuantizer
configure_list = [{
'quant_types': ['weight'],
'quant_bits': {
'weight': 8,
},
'op_types':['Conv2d', 'Linear']
}]
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-4)
quantizer = DoReFaQuantizer(model, configure_list, optimizer)
quantizer.compress()
View example code for more information.
Compressor class provides some utility methods for subclass and users:
Set wrapper attribute¶
Sometimes calc_mask must save some state data, therefore users can use set_wrappers_attribute API to register attribute just like how buffers are registered in PyTorch modules. These buffers will be registered to module wrapper. Users can access these buffers through module wrapper.
In above example, we use set_wrappers_attribute to set a buffer if_calculated which is used as flag indicating if the mask of a layer is already calculated.
Collect data during forward¶
Sometimes users want to collect some data during the modules’ forward method, for example, the mean value of the activation. This can be done by adding a customized collector to module.
class MyMasker(WeightMasker):
def __init__(self, model, pruner):
super().__init__(model, pruner)
# Set attribute `collected_activation` for all wrappers to store
# activations for each layer
self.pruner.set_wrappers_attribute("collected_activation", [])
self.activation = torch.nn.functional.relu
def collector(wrapper, input_, output):
# The collected activation can be accessed via each wrapper's collected_activation
# attribute
wrapper.collected_activation.append(self.activation(output.detach().cpu()))
self.pruner.hook_id = self.pruner.add_activation_collector(collector)
The collector function will be called each time the forward method runs.
Users can also remove this collector like this:
# Save the collector identifier
collector_id = self.pruner.add_activation_collector(collector)
# When the collector is not used any more, it can be remove using
# the saved collector identifier
self.pruner.remove_activation_collector(collector_id)
Pruner¶
A pruner receives model, config_list and optimizer as arguments. It prunes the model per the config_list during training loop by adding a hook on optimizer.step().
Pruner class is a subclass of Compressor, so it contains everything in the Compressor class and some additional components only for pruning, it contains:
Weight masker¶
A weight masker is the implementation of pruning algorithms, it can prune a specified layer wrapped by module wrapper with specified sparsity.
Pruning module wrapper¶
A pruning module wrapper is a module containing:
- the origin module
- some buffers used by
calc_mask - a new forward method that applies masks before running the original forward method.
the reasons to use module wrapper:
- some buffers are needed by
calc_maskto calculate masks and these buffers should be registered inmodule wrapperso that the original modules are not contaminated. - a new
forwardmethod is needed to apply masks to weight before calling the realforwardmethod.
Pruning hook¶
A pruning hook is installed on a pruner when the pruner is constructed, it is used to call pruner’s calc_mask method at optimizer.step() is invoked.
Quantizer¶
Quantizer class is also a subclass of Compressor, it is used to compress models by reducing the number of bits required to represent weights or activations, which can reduce the computations and the inference time. It contains:
Quantization module wrapper¶
Each module/layer of the model to be quantized is wrapped by a quantization module wrapper, it provides a new forward method to quantize the original module’s weight, input and output.
Quantization hook¶
A quantization hook is installed on a quntizer when it is constructed, it is call at optimizer.step().
Quantization methods¶
Quantizer class provides following methods for subclass to implement quantization algorithms:
class Quantizer(Compressor):
"""
Base quantizer for pytorch quantizer
"""
def quantize_weight(self, weight, wrapper, **kwargs):
"""
quantize should overload this method to quantize weight.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
weight : Tensor
weight that needs to be quantized
wrapper : QuantizerModuleWrapper
the wrapper for origin module
"""
raise NotImplementedError('Quantizer must overload quantize_weight()')
def quantize_output(self, output, wrapper, **kwargs):
"""
quantize should overload this method to quantize output.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
output : Tensor
output that needs to be quantized
wrapper : QuantizerModuleWrapper
the wrapper for origin module
"""
raise NotImplementedError('Quantizer must overload quantize_output()')
def quantize_input(self, *inputs, wrapper, **kwargs):
"""
quantize should overload this method to quantize input.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
inputs : Tensor
inputs that needs to be quantized
wrapper : QuantizerModuleWrapper
the wrapper for origin module
"""
raise NotImplementedError('Quantizer must overload quantize_input()')
Multi-GPU support¶
On multi-GPU training, buffers and parameters are copied to multiple GPU every time the forward method runs on multiple GPU. If buffers and parameters are updated in the forward method, an in-place update is needed to ensure the update is effective.
Since calc_mask is called in the optimizer.step method, which happens after the forward method and happens only on one GPU, it supports multi-GPU naturally.
Customize New Compression Algorithm¶
Contents
In order to simplify the process of writing new compression algorithms, we have designed simple and flexible programming interface, which covers pruning and quantization. Below, we first demonstrate how to customize a new pruning algorithm and then demonstrate how to customize a new quantization algorithm.
Important Note To better understand how to customize new pruning/quantization algorithms, users should first understand the framework that supports various pruning algorithms in NNI. Reference Framework overview of model compression
Customize a new pruning algorithm¶
Implementing a new pruning algorithm requires implementing a weight masker class which shoud be a subclass of WeightMasker, and a pruner class, which should be a subclass Pruner.
An implementation of weight masker may look like this:
class MyMasker(WeightMasker):
def __init__(self, model, pruner):
super().__init__(model, pruner)
# You can do some initialization here, such as collecting some statistics data
# if it is necessary for your algorithms to calculate the masks.
def calc_mask(self, sparsity, wrapper, wrapper_idx=None):
# calculate the masks based on the wrapper.weight, and sparsity,
# and anything else
# mask = ...
return {'weight_mask': mask}
You can reference nni provided weight masker implementations to implement your own weight masker.
A basic pruner looks likes this:
class MyPruner(Pruner):
def __init__(self, model, config_list, optimizer):
super().__init__(model, config_list, optimizer)
self.set_wrappers_attribute("if_calculated", False)
# construct a weight masker instance
self.masker = MyMasker(model, self)
def calc_mask(self, wrapper, wrapper_idx=None):
sparsity = wrapper.config['sparsity']
if wrapper.if_calculated:
# Already pruned, do not prune again as a one-shot pruner
return None
else:
# call your masker to actually calcuate the mask for this layer
masks = self.masker.calc_mask(sparsity=sparsity, wrapper=wrapper, wrapper_idx=wrapper_idx)
wrapper.if_calculated = True
return masks
Reference nni provided pruner implementations to implement your own pruner class.
Customize a new quantization algorithm¶
To write a new quantization algorithm, you can write a class that inherits nni.compression.torch.Quantizer. Then, override the member functions with the logic of your algorithm. The member function to override is quantize_weight. quantize_weight directly returns the quantized weights rather than mask, because for quantization the quantized weights cannot be obtained by applying mask.
from nni.compression.torch import Quantizer
class YourQuantizer(Quantizer):
def __init__(self, model, config_list):
"""
Suggest you to use the NNI defined spec for config
"""
super().__init__(model, config_list)
def quantize_weight(self, weight, config, **kwargs):
"""
quantize should overload this method to quantize weight tensors.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
weight : Tensor
weight that needs to be quantized
config : dict
the configuration for weight quantization
"""
# Put your code to generate `new_weight` here
return new_weight
def quantize_output(self, output, config, **kwargs):
"""
quantize should overload this method to quantize output.
This method is effectively hooked to `:meth:`forward` of the model.
Parameters
----------
output : Tensor
output that needs to be quantized
config : dict
the configuration for output quantization
"""
# Put your code to generate `new_output` here
return new_output
def quantize_input(self, *inputs, config, **kwargs):
"""
quantize should overload this method to quantize input.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
inputs : Tensor
inputs that needs to be quantized
config : dict
the configuration for inputs quantization
"""
# Put your code to generate `new_input` here
return new_input
def update_epoch(self, epoch_num):
pass
def step(self):
"""
Can do some processing based on the model or weights binded
in the func bind_model
"""
pass
Customize backward function¶
Sometimes it’s necessary for a quantization operation to have a customized backward function, such as Straight-Through Estimator, user can customize a backward function as follow:
from nni.compression.torch.compressor import Quantizer, QuantGrad, QuantType
class ClipGrad(QuantGrad):
@staticmethod
def quant_backward(tensor, grad_output, quant_type):
"""
This method should be overrided by subclass to provide customized backward function,
default implementation is Straight-Through Estimator
Parameters
----------
tensor : Tensor
input of quantization operation
grad_output : Tensor
gradient of the output of quantization operation
quant_type : QuantType
the type of quantization, it can be `QuantType.QUANT_INPUT`, `QuantType.QUANT_WEIGHT`, `QuantType.QUANT_OUTPUT`,
you can define different behavior for different types.
Returns
-------
tensor
gradient of the input of quantization operation
"""
# for quant_output function, set grad to zero if the absolute value of tensor is larger than 1
if quant_type == QuantType.QUANT_OUTPUT:
grad_output[torch.abs(tensor) > 1] = 0
return grad_output
class YourQuantizer(Quantizer):
def __init__(self, model, config_list):
super().__init__(model, config_list)
# set your customized backward function to overwrite default backward function
self.quant_grad = ClipGrad
If you do not customize QuantGrad, the default backward is Straight-Through Estimator.
Coming Soon …
Feature Engineering¶
We are glad to introduce Feature Engineering toolkit on top of NNI, it’s still in the experiment phase which might evolve based on usage feedback. We’d like to invite you to use, feedback and even contribute.
For details, please refer to the following tutorials:
Feature Engineering with NNI¶
We are glad to announce the alpha release for Feature Engineering toolkit on top of NNI, it’s still in the experiment phase which might evolve based on user feedback. We’d like to invite you to use, feedback and even contribute.
For now, we support the following feature selector:
These selectors are suitable for tabular data(which means it doesn’t include image, speech and text data).
In addition, those selector only for feature selection. If you want to:
- generate high-order combined features on nni while doing feature selection;
- leverage your distributed resources; you could try this example.
How to use?¶
from nni.feature_engineering.gradient_selector import FeatureGradientSelector
# from nni.feature_engineering.gbdt_selector import GBDTSelector
# load data
...
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# initlize a selector
fgs = FeatureGradientSelector(...)
# fit data
fgs.fit(X_train, y_train)
# get improtant features
# will return the index with important feature here.
print(fgs.get_selected_features(...))
...
When using the built-in Selector, you first need to import a feature selector, and initialize it. You could call the function fit in the selector to pass the data to the selector. After that, you could use get_seleteced_features to get important features. The function parameters in different selectors might be different, so you need to check the docs before using it.
How to customize?¶
NNI provides state-of-the-art feature selector algorithm in the builtin-selector. NNI also supports to build a feature selector by yourself.
If you want to implement a customized feature selector, you need to:
- Inherit the base FeatureSelector class
- Implement fit and get_selected_features function
- Integrate with sklearn (Optional)
Here is an example:
1. Inherit the base Featureselector Class
from nni.feature_engineering.feature_selector import FeatureSelector
class CustomizedSelector(FeatureSelector):
def __init__(self, ...):
...
2. Implement fit and get_selected_features Function
from nni.tuner import Tuner
from nni.feature_engineering.feature_selector import FeatureSelector
class CustomizedSelector(FeatureSelector):
def __init__(self, ...):
...
def fit(self, X, y, **kwargs):
"""
Fit the training data to FeatureSelector
Parameters
------------
X : array-like numpy matrix
The training input samples, which shape is [n_samples, n_features].
y: array-like numpy matrix
The target values (class labels in classification, real numbers in regression). Which shape is [n_samples].
"""
self.X = X
self.y = y
...
def get_selected_features(self):
"""
Get important feature
Returns
-------
list :
Return the index of the important feature.
"""
...
return self.selected_features_
...
3. Integrate with Sklearn
sklearn.pipeline.Pipeline can connect models in series, such as feature selector, normalization, and classification/regression to form a typical machine learning problem workflow.
The following step could help us to better integrate with sklearn, which means we could treat the customized feature selector as a mudule of the pipeline.
- Inherit the calss sklearn.base.BaseEstimator
- Implement get_params and set_params function in BaseEstimator
- Inherit the class sklearn.feature_selection.base.SelectorMixin
- Implement get_support, transform and inverse_transform Function in SelectorMixin
Here is an example:
1. Inherit the BaseEstimator Class and its Function
from sklearn.base import BaseEstimator
from nni.feature_engineering.feature_selector import FeatureSelector
class CustomizedSelector(FeatureSelector, BaseEstimator):
def __init__(self, ...):
...
def get_params(self, ...):
"""
Get parameters for this estimator.
"""
params = self.__dict__
params = {key: val for (key, val) in params.items()
if not key.endswith('_')}
return params
def set_params(self, **params):
"""
Set the parameters of this estimator.
"""
for param in params:
if hasattr(self, param):
setattr(self, param, params[param])
return self
2. Inherit the SelectorMixin Class and its Function
from sklearn.base import BaseEstimator
from sklearn.feature_selection.base import SelectorMixin
from nni.feature_engineering.feature_selector import FeatureSelector
class CustomizedSelector(FeatureSelector, BaseEstimator, SelectorMixin):
def __init__(self, ...):
...
def get_params(self, ...):
"""
Get parameters for this estimator.
"""
params = self.__dict__
params = {key: val for (key, val) in params.items()
if not key.endswith('_')}
return params
def set_params(self, **params):
"""
Set the parameters of this estimator.
"""
for param in params:
if hasattr(self, param):
setattr(self, param, params[param])
return self
def get_support(self, indices=False):
"""
Get a mask, or integer index, of the features selected.
Parameters
----------
indices : bool
Default False. If True, the return value will be an array of integers, rather than a boolean mask.
Returns
-------
list :
returns support: An index that selects the retained features from a feature vector.
If indices are False, this is a boolean array of shape [# input features], in which an element is True iff its corresponding feature is selected for retention.
If indices are True, this is an integer array of shape [# output features] whose values
are indices into the input feature vector.
"""
...
return mask
def transform(self, X):
"""Reduce X to the selected features.
Parameters
----------
X : array
which shape is [n_samples, n_features]
Returns
-------
X_r : array
which shape is [n_samples, n_selected_features]
The input samples with only the selected features.
"""
...
return X_r
def inverse_transform(self, X):
"""
Reverse the transformation operation
Parameters
----------
X : array
shape is [n_samples, n_selected_features]
Returns
-------
X_r : array
shape is [n_samples, n_original_features]
"""
...
return X_r
After integrating with Sklearn, we could use the feature selector as follows:
from sklearn.linear_model import LogisticRegression
# load data
...
X_train, y_train = ...
# build a ppipeline
pipeline = make_pipeline(XXXSelector(...), LogisticRegression())
pipeline = make_pipeline(SelectFromModel(ExtraTreesClassifier(n_estimators=50)), LogisticRegression())
pipeline.fit(X_train, y_train)
# score
print("Pipeline Score: ", pipeline.score(X_train, y_train))
Benchmark¶
Baseline means without any feature selection, we directly pass the data to LogisticRegression. For this benchmark, we only use 10% data from the train as test data. For the GradientFeatureSelector, we only take the top20 features. The metric is the mean accuracy on the given test data and labels.
| Dataset | All Features + LR (acc, time, memory) | GradientFeatureSelector + LR (acc, time, memory) | TreeBasedClassifier + LR (acc, time, memory) | #Train | #Feature |
|---|---|---|---|---|---|
| colon-cancer | 0.7547, 890ms, 348MiB | 0.7368, 363ms, 286MiB | 0.7223, 171ms, 1171 MiB | 62 | 2,000 |
| gisette | 0.9725, 215ms, 584MiB | 0.89416, 446ms, 397MiB | 0.9792, 911ms, 234MiB | 6,000 | 5,000 |
| avazu | 0.8834, N/A, N/A | N/A, N/A, N/A | N/A, N/A, N/A | 40,428,967 | 1,000,000 |
| rcv1 | 0.9644, 557ms, 241MiB | 0.7333, 401ms, 281MiB | 0.9615, 752ms, 284MiB | 20,242 | 47,236 |
| news20.binary | 0.9208, 707ms, 361MiB | 0.6870, 565ms, 371MiB | 0.9070, 904ms, 364MiB | 19,996 | 1,355,191 |
| real-sim | 0.9681, 433ms, 274MiB | 0.7969, 251ms, 274MiB | 0.9591, 643ms, 367MiB | 72,309 | 20,958 |
The dataset of benchmark could be download in here
The code could be refenrence /examples/feature_engineering/gradient_feature_selector/benchmark_test.py.
Reference and Feedback¶
- To report a bug for this feature in GitHub;
- To file a feature or improvement request for this feature in GitHub;
- To know more about Neural Architecture Search with NNI;
- To know more about Model Compression with NNI;
- To know more about Hyperparameter Tuning with NNI;
GradientFeatureSelector¶
The algorithm in GradinetFeatureSelector comes from “Feature Gradients: Scalable Feature Selection via Discrete Relaxation”.
GradientFeatureSelector, a gradient-based search algorithm for feature selection.
- This approach extends a recent result on the estimation of learnability in the sublinear data regime by showing that the calculation can be performed iteratively (i.e., in mini-batches) and in linear time and space with respect to both the number of features D and the sample size N.
- This, along with a discrete-to-continuous relaxation of the search domain, allows for an efficient, gradient-based search algorithm among feature subsets for very large datasets.
- Crucially, this algorithm is capable of finding higher-order correlations between features and targets for both the N > D and N < D regimes, as opposed to approaches that do not consider such interactions and/or only consider one regime.
Usage¶
from nni.feature_engineering.gradient_selector import FeatureGradientSelector
# load data
...
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# initlize a selector
fgs = FeatureGradientSelector(n_features=10)
# fit data
fgs.fit(X_train, y_train)
# get improtant features
# will return the index with important feature here.
print(fgs.get_selected_features())
...
And you could reference the examples in /examples/feature_engineering/gradient_feature_selector/, too.
Parameters of class FeatureGradientSelector constructor
- order (int, optional, default = 4) - What order of interactions to include. Higher orders may be more accurate but increase the run time. 12 is the maximum allowed order.
- penatly (int, optional, default = 1) - Constant that multiplies the regularization term.
- n_features (int, optional, default = None) - If None, will automatically choose number of features based on search. Otherwise, the number of top features to select.
- max_features (int, optional, default = None) - If not None, will use the ‘elbow method’ to determine the number of features with max_features as the upper limit.
- learning_rate (float, optional, default = 1e-1) - learning rate
- init (zero, on, off, onhigh, offhigh, or sklearn, optional, default = zero) - How to initialize the vector of scores. ‘zero’ is the default.
- n_epochs (int, optional, default = 1) - number of epochs to run
- shuffle (bool, optional, default = True) - Shuffle “rows” prior to an epoch.
- batch_size (int, optional, default = 1000) - Nnumber of “rows” to process at a time.
- target_batch_size (int, optional, default = 1000) - Number of “rows” to accumulate gradients over. Useful when many rows will not fit into memory but are needed for accurate estimation.
- classification (bool, optional, default = True) - If True, problem is classification, else regression.
- ordinal (bool, optional, default = True) - If True, problem is ordinal classification. Requires classification to be True.
- balanced (bool, optional, default = True) - If true, each class is weighted equally in optimization, otherwise weighted is done via support of each class. Requires classification to be True.
- prerocess (str, optional, default = ‘zscore’) - ‘zscore’ which refers to centering and normalizing data to unit variance or ‘center’ which only centers the data to 0 mean.
- soft_grouping (bool, optional, default = True) - If True, groups represent features that come from the same source. Used to encourage sparsity of groups and features within groups.
- verbose (int, optional, default = 0) - Controls the verbosity when fitting. Set to 0 for no printing 1 or higher for printing every verbose number of gradient steps.
- device (str, optional, default = ‘cpu’) - ‘cpu’ to run on CPU and ‘cuda’ to run on GPU. Runs much faster on GPU
Requirement of fit FuncArgs
- X (array-like, require) - The training input samples which shape = [n_samples, n_features]
- y (array-like, require) - The target values (class labels in classification, real numbers in regression) which shape = [n_samples].
- groups (array-like, optional, default = None) - Groups of columns that must be selected as a unit. e.g. [0, 0, 1, 2] specifies the first two columns are part of a group. Which shape is [n_features].
Requirement of get_selected_features FuncArgs
For now, the get_selected_features function has no parameters.
GBDTSelector¶
GBDTSelector is based on LightGBM, which is a gradient boosting framework that uses tree-based learning algorithms.
When passing the data into the GBDT model, the model will construct the boosting tree. And the feature importance comes from the score in construction, which indicates how useful or valuable each feature was in the construction of the boosted decision trees within the model.
We could use this method as a strong baseline in Feature Selector, especially when using the GBDT model as a classifier or regressor.
For now, we support the importance_type is split and gain. But we will support customized importance_type in the future, which means the user could define how to calculate the feature score by themselves.
Usage¶
First you need to install dependency:
pip install lightgbm
Then
from nni.feature_engineering.gbdt_selector import GBDTSelector
# load data
...
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# initlize a selector
fgs = GBDTSelector()
# fit data
fgs.fit(X_train, y_train, ...)
# get improtant features
# will return the index with important feature here.
print(fgs.get_selected_features(10))
...
And you could reference the examples in /examples/feature_engineering/gbdt_selector/, too.
Requirement of fit FuncArgs
- X (array-like, require) - The training input samples which shape = [n_samples, n_features]
- y (array-like, require) - The target values (class labels in classification, real numbers in regression) which shape = [n_samples].
- lgb_params (dict, require) - The parameters for lightgbm model. The detail you could reference here
- eval_ratio (float, require) - The ratio of data size. It’s used for split the eval data and train data from self.X.
- early_stopping_rounds (int, require) - The early stopping setting in lightgbm. The detail you could reference here.
- importance_type (str, require) - could be ‘split’ or ‘gain’. The ‘split’ means ‘ result contains numbers of times the feature is used in a model’ and the ‘gain’ means ‘result contains total gains of splits which use the feature’. The detail you could reference in here.
- num_boost_round (int, require) - number of boost round. The detail you could reference here.
Requirement of get_selected_features FuncArgs
- topk (int, require) - the topK impotance features you want to selected.
References¶
nnictl¶
Introduction¶
nnictl is a command line tool, which can be used to control experiments, such as start/stop/resume an experiment, start/stop NNIBoard, etc.
Commands¶
nnictl support commands:
- nnictl create
- nnictl resume
- nnictl view
- nnictl stop
- nnictl update
- nnictl trial
- nnictl top
- nnictl experiment
- nnictl platform
- nnictl config
- nnictl log
- nnictl webui
- nnictl tensorboard
- nnictl package
- nnictl ss_gen
- nnictl –version
Manage an experiment¶
nnictl create¶
Description
You can use this command to create a new experiment, using the configuration specified in config file.
After this command is successfully done, the context will be set as this experiment, which means the following command you issued is associated with this experiment, unless you explicitly changes the context(not supported yet).
Usage
nnictl create [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| --config, -c | True | YAML configure file of the experiment | |
| --port, -p | False | the port of restful server | |
| --debug, -d | False | set debug mode | |
| --foreground, -f | False | set foreground mode, print log content to terminal |
Examples
create a new experiment with the default port: 8080
nnictl create --config nni/examples/trials/mnist-tfv1/config.yml
create a new experiment with specified port 8088
nnictl create --config nni/examples/trials/mnist-tfv1/config.yml --port 8088create a new experiment with specified port 8088 and debug mode
nnictl create --config nni/examples/trials/mnist-tfv1/config.yml --port 8088 --debug
Note:
Debug mode will disable version check function in Trialkeeper.
nnictl resume¶
Description
You can use this command to resume a stopped experiment.
Usage
nnictl resume [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | True | The id of the experiment you want to resume | |
| --port, -p | False | Rest port of the experiment you want to resume | |
| --debug, -d | False | set debug mode | |
| --foreground, -f | False | set foreground mode, print log content to terminal |
Example
resume an experiment with specified port 8088
nnictl resume [experiment_id] --port 8088
nnictl view¶
Description
You can use this command to view a stopped experiment.
Usage
nnictl view [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | True | The id of the experiment you want to view | |
| --port, -p | False | Rest port of the experiment you want to view |
Example
view an experiment with specified port 8088
nnictl view [experiment_id] --port 8088
nnictl stop¶
Description
You can use this command to stop a running experiment or multiple experiments.
Usage
nnictl stop [Options]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | The id of the experiment you want to stop | |
| --port, -p | False | Rest port of the experiment you want to stop | |
| --all, -a | False | Stop all of experiments |
Details & Examples
If there is no id specified, and there is an experiment running, stop the running experiment, or print error message.
nnictl stop
If there is an id specified, and the id matches the running experiment, nnictl will stop the corresponding experiment, or will print error message.
nnictl stop [experiment_id]
If there is a port specified, and an experiment is running on that port, the experiment will be stopped.
nnictl stop --port 8080Users could use ‘nnictl stop –all’ to stop all experiments.
nnictl stop --all
If the id ends with *, nnictl will stop all experiments whose ids matchs the regular.
If the id does not exist but match the prefix of an experiment id, nnictl will stop the matched experiment.
If the id does not exist but match multiple prefix of the experiment ids, nnictl will give id information.
nnictl update¶
nnictl update searchspace
Description
You can use this command to update an experiment’s search space.
Usage
nnictl update searchspace [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --filename, -f | True | the file storing your new search space |
Example
update experiment's new search space with file dir 'examples/trials/mnist-tfv1/search_space.json'nnictl update searchspace [experiment_id] --filename examples/trials/mnist-tfv1/search_space.json
nnictl update concurrency
Description
You can use this command to update an experiment’s concurrency.
Usage
nnictl update concurrency [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --value, -v | True | the number of allowed concurrent trials |
Example
update experiment’s concurrency
nnictl update concurrency [experiment_id] --value [concurrency_number]
nnictl update duration
Description
You can use this command to update an experiment’s duration.
Usage
nnictl update duration [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --value, -v | True | the experiment duration will be NUMBER seconds. SUFFIX may be 's' for seconds (the default), 'm' for minutes, 'h' for hours or 'd' for days. |
Example
update experiment’s duration
nnictl update duration [experiment_id] --value [duration]
nnictl update trialnum
Description
You can use this command to update an experiment’s maxtrialnum.
Usage
nnictl update trialnum [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --value, -v | True | the new number of maxtrialnum you want to set |
Example
update experiment’s trial num
nnictl update trialnum --id [experiment_id] --value [trial_num]
nnictl trial¶
nnictl trial ls
Description
You can use this command to show trial’s information.
Usage
nnictl trial ls
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set |
nnictl trial kill
Description
You can use this command to kill a trial job.
Usage
nnictl trial kill [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | Experiment ID of the trial | |
| --trial_id, -T | True | ID of the trial you want to kill. |
Example
kill trail job
nnictl trial [trial_id] --experiment [experiment_id]
nnictl top¶
Description
Monitor all of running experiments.
Usage
nnictl top
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --time, -t | False | The interval to update the experiment status, the unit of time is second, and the default value is 3 second. |
Manage experiment information¶
nnictl experiment show
Description
Show the information of experiment.
Usage
nnictl experiment show
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set |
nnictl experiment status
Description
Show the status of experiment.
Usage
nnictl experiment status
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set |
nnictl experiment list
Description
Show the information of all the (running) experiments.
Usage
nnictl experiment list [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| --all | False | list all of experiments |
nnictl experiment delete
Description
Delete one or all experiments, it includes log, result, environment information and cache. It uses to delete useless experiment result, or save disk space.
Usage
nnictl experiment delete [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment | |
| --all | False | delete all of experiments |
nnictl experiment export
Description
You can use this command to export reward & hyper-parameter of trial jobs to a csv file.
Usage
nnictl experiment export [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment | |
| --filename, -f | True | File path of the output file | |
| --type | True | Type of output file, only support "csv" and "json" |
- Examples
export all trial data in an experiment as json format
nnictl experiment export [experiment_id] --filename [file_path] --type json
nnictl experiment import
Description
You can use this command to import several prior or supplementary trial hyperparameters & results for NNI hyperparameter tuning. The data are fed to the tuning algorithm (e.g., tuner or advisor).
Usage
nnictl experiment import [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | The id of the experiment you want to import data into | |
| --filename, -f | True | a file with data you want to import in json format |
Details
NNI supports users to import their own data, please express the data in the correct format. An example is shown below:
[ {"parameter": {"x": 0.5, "y": 0.9}, "value": 0.03}, {"parameter": {"x": 0.4, "y": 0.8}, "value": 0.05}, {"parameter": {"x": 0.3, "y": 0.7}, "value": 0.04} ]
Every element in the top level list is a sample. For our built-in tuners/advisors, each sample should have at least two keys:
parameterandvalue. Theparametermust match this experiment’s search space, that is, all the keys (or hyperparameters) inparametermust match the keys in the search space. Otherwise, tuner/advisor may have unpredictable behavior.Valueshould follow the same rule of the input innni.report_final_result, that is, either a number or a dict with a key nameddefault. For your customized tuner/advisor, the file could have any json content depending on how you implement the corresponding methods (e.g.,import_data).You also can use nnictl experiment export to export a valid json file including previous experiment trial hyperparameters and results.
Currently, following tuner and advisor support import data:
builtinTunerName: TPE, Anneal, GridSearch, MetisTuner builtinAdvisorName: BOHB
If you want to import data to BOHB advisor, user are suggested to add “TRIAL_BUDGET” in parameter as NNI do, otherwise, BOHB will use max_budget as “TRIAL_BUDGET”. Here is an example:
[ {"parameter": {"x": 0.5, "y": 0.9, "TRIAL_BUDGET": 27}, "value": 0.03} ]
Examples
import data to a running experiment
nnictl experiment import [experiment_id] -f experiment_data.json
Manage platform information¶
nnictl platform clean
Description
It uses to clean up disk on a target platform. The provided YAML file includes the information of target platform, and it follows the same schema as the NNI configuration file.
Note
if the target platform is being used by other users, it may cause unexpected errors to others.
Usage
nnictl platform clean [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| --config | True | the path of yaml config file used when create an experiment |
Manage log¶
nnictl log stdout
Description
Show the stdout log content.
Usage
nnictl log stdout [options]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --head, -h | False | show head lines of stdout | |
| --tail, -t | False | show tail lines of stdout | |
| --path, -p | False | show the path of stdout file |
Example
Show the tail of stdout log content
nnictl log stdout [experiment_id] --tail [lines_number]
nnictl log stderr
Description
Show the stderr log content.
Usage
nnictl log stderr [options]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --head, -h | False | show head lines of stderr | |
| --tail, -t | False | show tail lines of stderr | |
| --path, -p | False | show the path of stderr file |
nnictl log trial
Description
Show trial log path.
Usage
nnictl log trial [options]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | Experiment ID of the trial | |
| --trial_id, -T | False | ID of the trial to be found the log path, required when id is not empty. |
Manage tensorboard¶
nnictl tensorboard start
Description
Start the tensorboard process.
Usage
nnictl tensorboard start
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set | |
| --trial_id, -T | False | ID of the trial | |
| --port | False | 6006 | The port of the tensorboard process |
Detail
- NNICTL support tensorboard function in local and remote platform for the moment, other platforms will be supported later.
- If you want to use tensorboard, you need to write your tensorboard log data to environment variable [NNI_OUTPUT_DIR] path.
- In local mode, nnictl will set –logdir=[NNI_OUTPUT_DIR] directly and start a tensorboard process.
- In remote mode, nnictl will create a ssh client to copy log data from remote machine to local temp directory firstly, and then start a tensorboard process in your local machine. You need to notice that nnictl only copy the log data one time when you use the command, if you want to see the later result of tensorboard, you should execute nnictl tensorboard command again.
- If there is only one trial job, you don’t need to set trial id. If there are multiple trial jobs running, you should set the trial id, or you could use [nnictl tensorboard start –trial_id all] to map –logdir to all trial log paths.
nnictl tensorboard stop
Description
Stop all of the tensorboard process.
Usage
nnictl tensorboard stop
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| id | False | ID of the experiment you want to set |
Manage package¶
nnictl package install
Description
Install a package (customized algorithms or nni provided algorithms) as builtin tuner/assessor/advisor.
Usage
nnictl package install --name <package name>
The available
<package name>can be checked viannictl package listcommand.or
nnictl package install <installation source>
Reference Install customized algorithms to prepare the installation source.
Example
Install SMAC tuner
nnictl package install --name SMAC
Install a customized tuner
nnictl package install nni/examples/tuners/customized_tuner/dist/demo_tuner-0.1-py3-none-any.whl
nnictl package show
Description
Show the detailed information of specified packages.
Usage
nnictl package show <package name>
Example
nnictl package show SMAC
nnictl package list
Description
List the installed/all packages.
Usage
nnictl package list [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| --all | False | List all packages |
Example
List installed packages
nnictl package list
List all packages
nnictl package list --all
nnictl package uninstall
Description
Uninstall a package.
Usage
nnictl package uninstall <package name>
Example Uninstall SMAC package
nnictl package uninstall SMAC
Generate search space¶
nnictl ss_gen
Description
Generate search space from user trial code which uses NNI NAS APIs.
Usage
nnictl ss_gen [OPTIONS]
Options
| Name, shorthand | Required | Default | Description |
|---|---|---|---|
| --trial_command | True | The command of the trial code | |
| --trial_dir | False | ./ | The directory of the trial code |
| --file | False | nni_auto_gen_search_space.json | The file for storing generated search space |
Example
Generate a search space
nnictl ss_gen --trial_command="python3 mnist.py" --trial_dir=./ --file=ss.json
Check NNI version¶
nnictl –version
Description
Describe the current version of NNI installed.
Usage
nnictl --version
Experiment Config Reference¶
A config file is needed when creating an experiment. The path of the config file is provided to nnictl.
The config file is in YAML format.
This document describes the rules to write the config file, and provides some examples and templates.
- Experiment Config Reference
- Template
- Configuration Spec
- Examples
Template¶
- Light weight (without Annotation and Assessor)
authorName:
experimentName:
trialConcurrency:
maxExecDuration:
maxTrialNum:
#choice: local, remote, pai, kubeflow
trainingServicePlatform:
searchSpacePath:
#choice: true, false, default: false
useAnnotation:
#choice: true, false, default: false
multiThread:
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName:
classArgs:
#choice: maximize, minimize
optimize_mode:
gpuIndices:
trial:
command:
codeDir:
gpuNum:
#machineList can be empty if the platform is local
machineList:
- ip:
port:
username:
passwd:
- Use Assessor
authorName:
experimentName:
trialConcurrency:
maxExecDuration:
maxTrialNum:
#choice: local, remote, pai, kubeflow
trainingServicePlatform:
searchSpacePath:
#choice: true, false, default: false
useAnnotation:
#choice: true, false, default: false
multiThread:
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName:
classArgs:
#choice: maximize, minimize
optimize_mode:
gpuIndices:
assessor:
#choice: Medianstop
builtinAssessorName:
classArgs:
#choice: maximize, minimize
optimize_mode:
trial:
command:
codeDir:
gpuNum:
#machineList can be empty if the platform is local
machineList:
- ip:
port:
username:
passwd:
- Use Annotation
authorName:
experimentName:
trialConcurrency:
maxExecDuration:
maxTrialNum:
#choice: local, remote, pai, kubeflow
trainingServicePlatform:
#choice: true, false, default: false
useAnnotation:
#choice: true, false, default: false
multiThread:
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName:
classArgs:
#choice: maximize, minimize
optimize_mode:
gpuIndices:
assessor:
#choice: Medianstop
builtinAssessorName:
classArgs:
#choice: maximize, minimize
optimize_mode:
trial:
command:
codeDir:
gpuNum:
#machineList can be empty if the platform is local
machineList:
- ip:
port:
username:
passwd:
Configuration Spec¶
authorName¶
Required. String.
The name of the author who create the experiment.
TBD: add default value.
trialConcurrency¶
Required. Integer between 1 and 99999.
Specifies the max num of trial jobs run simultaneously.
If trialGpuNum is bigger than the free gpu numbers, and the trial jobs running simultaneously can not reach trialConcurrency number, some trial jobs will be put into a queue to wait for gpu allocation.
maxExecDuration¶
Optional. String. Default: 999d.
maxExecDuration specifies the max duration time of an experiment. The unit of the time is {s, m, h, d}, which means {seconds, minutes, hours, days}.
Note: The maxExecDuration spec set the time of an experiment, not a trial job. If the experiment reach the max duration time, the experiment will not stop, but could not submit new trial jobs any more.
versionCheck¶
Optional. Bool. Default: true.
NNI will check the version of nniManager process and the version of trialKeeper in remote, pai and kubernetes platform. If you want to disable version check, you could set versionCheck be false.
debug¶
Optional. Bool. Default: false.
Debug mode will set versionCheck to false and set logLevel to be ‘debug’.
maxTrialNum¶
Optional. Integer between 1 and 99999. Default: 99999.
Specifies the max number of trial jobs created by NNI, including succeeded and failed jobs.
trainingServicePlatform¶
Required. String.
Specifies the platform to run the experiment, including local, remote, pai, kubeflow, frameworkcontroller.
- local run an experiment on local ubuntu machine.
- remote submit trial jobs to remote ubuntu machines, and machineList field should be filed in order to set up SSH connection to remote machine.
- pai submit trial jobs to OpenPAI of Microsoft. For more details of pai configuration, please refer to Guide to PAI Mode
- kubeflow submit trial jobs to kubeflow, NNI support kubeflow based on normal kubernetes and azure kubernetes. For detail please refer to Kubeflow Docs
- TODO: explain frameworkcontroller.
searchSpacePath¶
Optional. Path to existing file.
Specifies the path of search space file, which should be a valid path in the local linux machine.
The only exception that searchSpacePath can be not fulfilled is when useAnnotation=True.
useAnnotation¶
Optional. Bool. Default: false.
Use annotation to analysis trial code and generate search space.
Note: if useAnnotation is true, the searchSpacePath field should be removed.
multiThread¶
Optional. Bool. Default: false.
Enable multi-thread mode for dispatcher. If multiThread is enabled, dispatcher will start a thread to process each command from NNI Manager.
nniManagerIp¶
Optional. String. Default: eth0 device IP.
Set the IP address of the machine on which NNI manager process runs. This field is optional, and if it’s not set, eth0 device IP will be used instead.
Note: run ifconfig on NNI manager’s machine to check if eth0 device exists. If not, nniManagerIp is recommended to set explicitly.
logDir¶
Optional. Path to a directory. Default: <user home directory>/nni/experiment.
Configures the directory to store logs and data of the experiment.
logLevel¶
Optional. String. Default: info.
Sets log level for the experiment. Available log levels are: trace, debug, info, warning, error, fatal.
logCollection¶
Optional. http or none. Default: none.
Set the way to collect log in remote, pai, kubeflow, frameworkcontroller platform. There are two ways to collect log, one way is from http, trial keeper will post log content back from http request in this way, but this way may slow down the speed to process logs in trialKeeper. The other way is none, trial keeper will not post log content back, and only post job metrics. If your log content is too big, you could consider setting this param be none.
tuner¶
Required.
Specifies the tuner algorithm in the experiment, there are two kinds of ways to set tuner. One way is to use tuner provided by NNI sdk (built-in tuners), in which case you need to set builtinTunerName and classArgs. Another way is to use users’ own tuner file, in which case codeDirectory, classFileName, className and classArgs are needed. Users must choose exactly one way.
builtinTunerName¶
Required if using built-in tuners. String.
Specifies the name of system tuner, NNI sdk provides different tuners introduced here.
codeDir¶
Required if using customized tuners. Path relative to the location of config file.
Specifies the directory of tuner code.
classFileName¶
Required if using customized tuners. File path relative to codeDir.
Specifies the name of tuner file.
classArgs¶
Optional. Key-value pairs. Default: empty.
Specifies the arguments of tuner algorithm. Please refer to this file for the configurable arguments of each built-in tuner.
gpuIndices¶
Optional. String. Default: empty.
Specifies the GPUs that can be used by the tuner process. Single or multiple GPU indices can be specified. Multiple GPU indices are separated by comma ,. For example, 1, or 0,1,3. If the field is not set, no GPU will be visible to tuner (by setting CUDA_VISIBLE_DEVICES to be an empty string).
includeIntermediateResults¶
Optional. Bool. Default: false.
If includeIntermediateResults is true, the last intermediate result of the trial that is early stopped by assessor is sent to tuner as final result.
assessor¶
Specifies the assessor algorithm to run an experiment. Similar to tuners, there are two kinds of ways to set assessor. One way is to use assessor provided by NNI sdk. Users need to set builtinAssessorName and classArgs. Another way is to use users’ own assessor file, and users need to set codeDirectory, classFileName, className and classArgs. Users must choose exactly one way.
By default, there is no assessor enabled.
builtinAssessorName¶
Required if using built-in assessors. String.
Specifies the name of built-in assessor, NNI sdk provides different assessors introduced here.
codeDir¶
Required if using customized assessors. Path relative to the location of config file.
Specifies the directory of assessor code.
classFileName¶
Required if using customized assessors. File path relative to codeDir.
Specifies the name of assessor file.
classArgs¶
Optional. Key-value pairs. Default: empty.
Specifies the arguments of assessor algorithm.
advisor¶
Optional.
Specifies the advisor algorithm in the experiment. Similar to tuners and assessors, there are two kinds of ways to specify advisor. One way is to use advisor provided by NNI sdk, need to set builtinAdvisorName and classArgs. Another way is to use users’ own advisor file, and need to set codeDirectory, classFileName, className and classArgs.
When advisor is enabled, settings of tuners and advisors will be bypassed.
codeDir¶
Required if using customized advisors. Path relative to the location of config file.
Specifies the directory of advisor code.
classFileName¶
Required if using customized advisors. File path relative to codeDir.
Specifies the name of advisor file.
gpuIndices¶
Optional. String. Default: empty.
Specifies the GPUs that can be used. Single or multiple GPU indices can be specified. Multiple GPU indices are separated by comma ,. For example, 1, or 0,1,3. If the field is not set, no GPU will be visible to tuner (by setting CUDA_VISIBLE_DEVICES to be an empty string).
trial¶
Required. Key-value pairs.
In local and remote mode, the following keys are required.
- command: Required string. Specifies the command to run trial process.
- codeDir: Required string. Specifies the directory of your own trial file. This directory will be automatically uploaded in remote mode.
- gpuNum: Optional integer. Specifies the num of gpu to run the trial process. Default value is 0.
In PAI mode, the following keys are required.
- command: Required string. Specifies the command to run trial process.
- codeDir: Required string. Specifies the directory of the own trial file. Files in the directory will be uploaded in PAI mode.
- gpuNum: Required integer. Specifies the num of gpu to run the trial process. Default value is 0.
- cpuNum: Required integer. Specifies the cpu number of cpu to be used in pai container.
- memoryMB: Required integer. Set the memory size to be used in pai container, in megabytes.
- image: Required string. Set the image to be used in pai.
- authFile: Optional string. Used to provide Docker registry which needs authentication for image pull in PAI. Reference.
- shmMB: Optional integer. Shared memory size of container.
- portList: List of key-values pairs with
label,beginAt,portNumber. See job tutorial of PAI for details.
In Kubeflow mode, the following keys are required.
- codeDir: The local directory where the code files are in.
- ps: An optional configuration for kubeflow’s tensorflow-operator, which includes
- replicas: The replica number of ps role.
- command: The run script in ps’s container.
- gpuNum: The gpu number to be used in ps container.
- cpuNum: The cpu number to be used in ps container.
- memoryMB: The memory size of the container.
- image: The image to be used in ps.
- worker: An optional configuration for kubeflow’s tensorflow-operator.
- replicas: The replica number of worker role.
- command: The run script in worker’s container.
- gpuNum: The gpu number to be used in worker container.
- cpuNum: The cpu number to be used in worker container.
- memoryMB: The memory size of the container.
- image: The image to be used in worker.
localConfig¶
Optional in local mode. Key-value pairs.
Only applicable if trainingServicePlatform is set to local, otherwise there should not be localConfig section in configuration file.
gpuIndices¶
Optional. String. Default: none.
Used to specify designated GPU devices for NNI, if it is set, only the specified GPU devices are used for NNI trial jobs. Single or multiple GPU indices can be specified. Multiple GPU indices should be separated with comma (,), such as 1 or 0,1,3. By default, all GPUs available will be used.
maxTrialNumPerGpu¶
Optional. Integer. Default: 1.
Used to specify the max concurrency trial number on a GPU device.
useActiveGpu¶
Optional. Bool. Default: false.
Used to specify whether to use a GPU if there is another process. By default, NNI will use the GPU only if there is no other active process in the GPU. If useActiveGpu is set to true, NNI will use the GPU regardless of another processes. This field is not applicable for NNI on Windows.
machineList¶
Required in remote mode. A list of key-value pairs with the following keys.
ip¶
Required. IP address or host name that is accessible from the current machine.
The IP address or host name of remote machine.
passwd¶
Required if authentication with username/password. String.
Specifies the password of the account.
sshKeyPath¶
Required if authentication with ssh key. Path to private key file.
If users use ssh key to login remote machine, sshKeyPath should be a valid path to a ssh key file.
Note: if users set passwd and sshKeyPath simultaneously, NNI will try passwd first.
passphrase¶
Optional. String.
Used to protect ssh key, which could be empty if users don’t have passphrase.
gpuIndices¶
Optional. String. Default: none.
Used to specify designated GPU devices for NNI, if it is set, only the specified GPU devices are used for NNI trial jobs. Single or multiple GPU indices can be specified. Multiple GPU indices should be separated with comma (,), such as 1 or 0,1,3. By default, all GPUs available will be used.
maxTrialNumPerGpu¶
Optional. Integer. Default: 99999.
Used to specify the max concurrency trial number on a GPU device.
useActiveGpu¶
Optional. Bool. Default: false.
Used to specify whether to use a GPU if there is another process. By default, NNI will use the GPU only if there is no other active process in the GPU. If useActiveGpu is set to true, NNI will use the GPU regardless of another processes. This field is not applicable for NNI on Windows.
kubeflowConfig¶
operator¶
Required. String. Has to be tf-operator or pytorch-operator.
Specifies the kubeflow’s operator to be used, NNI support tf-operator in current version.
storage¶
Optional. String. Default. nfs.
Specifies the storage type of kubeflow, including nfs and azureStorage.
nfs¶
Required if using nfs. Key-value pairs.
- server is the host of nfs server.
- path is the mounted path of nfs.
keyVault¶
Required if using azure storage. Key-value pairs.
Set keyVault to storage the private key of your azure storage account. Refer to https://docs.microsoft.com/en-us/azure/key-vault/key-vault-manage-with-cli2.
- vaultName is the value of
--vault-nameused in az command. - name is the value of
--nameused in az command.
azureStorage¶
Required if using azure storage. Key-value pairs.
Set azure storage account to store code files.
- accountName is the name of azure storage account.
- azureShare is the share of the azure file storage.
uploadRetryCount¶
Required if using azure storage. Integer between 1 and 99999.
If upload files to azure storage failed, NNI will retry the process of uploading, this field will specify the number of attempts to re-upload files.
paiConfig¶
token¶
Required if using token authentication. String.
Personal access token that can be retrieved from PAI portal.
reuse¶
Optional. Bool. default: false. It’s an experimental feature.
If it’s true, NNI will reuse OpenPAI jobs to run as many as possible trials. It can save time of creating new jobs. User needs to make sure each trial can run independent in same job, for example, avoid loading checkpoint from previous trials.
Examples¶
Local mode¶
If users want to run trial jobs in local machine, and use annotation to generate search space, could use the following config:
authorName: test
experimentName: test_experiment
trialConcurrency: 3
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai, kubeflow
trainingServicePlatform: local
#choice: true, false
useAnnotation: true
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: /nni/mnist
gpuNum: 0
You can add assessor configuration.
authorName: test
experimentName: test_experiment
trialConcurrency: 3
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai, kubeflow
trainingServicePlatform: local
searchSpacePath: /nni/search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
assessor:
#choice: Medianstop
builtinAssessorName: Medianstop
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: /nni/mnist
gpuNum: 0
Or you could specify your own tuner and assessor file as following,
authorName: test
experimentName: test_experiment
trialConcurrency: 3
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai, kubeflow
trainingServicePlatform: local
searchSpacePath: /nni/search_space.json
#choice: true, false
useAnnotation: false
tuner:
codeDir: /nni/tuner
classFileName: mytuner.py
className: MyTuner
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
assessor:
codeDir: /nni/assessor
classFileName: myassessor.py
className: MyAssessor
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: /nni/mnist
gpuNum: 0
Remote mode¶
If run trial jobs in remote machine, users could specify the remote machine information as following format:
authorName: test
experimentName: test_experiment
trialConcurrency: 3
maxExecDuration: 1h
maxTrialNum: 10
#choice: local, remote, pai, kubeflow
trainingServicePlatform: remote
searchSpacePath: /nni/search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: /nni/mnist
gpuNum: 0
#machineList can be empty if the platform is local
machineList:
- ip: 10.10.10.10
port: 22
username: test
passwd: test
- ip: 10.10.10.11
port: 22
username: test
passwd: test
- ip: 10.10.10.12
port: 22
username: test
sshKeyPath: /nni/sshkey
passphrase: qwert
PAI mode¶
authorName: test
experimentName: nni_test1
trialConcurrency: 1
maxExecDuration:500h
maxTrialNum: 1
#choice: local, remote, pai, kubeflow
trainingServicePlatform: pai
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
command: python3 main.py
codeDir: .
gpuNum: 4
cpuNum: 2
memoryMB: 10000
#The docker image to run NNI job on pai
image: msranni/nni:latest
paiConfig:
#The username to login pai
userName: test
#The password to login pai
passWord: test
#The host of restful server of pai
host: 10.10.10.10
Kubeflow mode¶
kubeflow with nfs storage.
authorName: default
experimentName: example_mni
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 1
#choice: local, remote, pai, kubeflow
trainingServicePlatform: kubeflow
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
trial:
codeDir: .
worker:
replicas: 1
command: python3 mnist.py
gpuNum: 0
cpuNum: 1
memoryMB: 8192
image: msranni/nni:latest
kubeflowConfig:
operator: tf-operator
nfs:
server: 10.10.10.10
path: /var/nfs/general
Kubeflow with azure storage¶
authorName: default
experimentName: example_mni
trialConcurrency: 1
maxExecDuration: 1h
maxTrialNum: 1
#choice: local, remote, pai, kubeflow
trainingServicePlatform: kubeflow
searchSpacePath: search_space.json
#choice: true, false
useAnnotation: false
#nniManagerIp: 10.10.10.10
tuner:
#choice: TPE, Random, Anneal, Evolution
builtinTunerName: TPE
classArgs:
#choice: maximize, minimize
optimize_mode: maximize
assessor:
builtinAssessorName: Medianstop
classArgs:
optimize_mode: maximize
trial:
codeDir: .
worker:
replicas: 1
command: python3 mnist.py
gpuNum: 0
cpuNum: 1
memoryMB: 4096
image: msranni/nni:latest
kubeflowConfig:
operator: tf-operator
keyVault:
vaultName: Contoso-Vault
name: AzureStorageAccountKey
azureStorage:
accountName: storage
azureShare: share01
Search Space¶
Overview¶
In NNI, tuner will sample parameters/architecture according to the search space, which is defined as a json file.
To define a search space, users should define the name of variable, the type of sampling strategy and its parameters.
- An example of search space definition as follow:
{
"dropout_rate": {"_type": "uniform", "_value": [0.1, 0.5]},
"conv_size": {"_type": "choice", "_value": [2, 3, 5, 7]},
"hidden_size": {"_type": "choice", "_value": [124, 512, 1024]},
"batch_size": {"_type": "choice", "_value": [50, 250, 500]},
"learning_rate": {"_type": "uniform", "_value": [0.0001, 0.1]}
}
Take the first line as an example. dropout_rate is defined as a variable whose priori distribution is a uniform distribution of a range from 0.1 and 0.5.
Note that the ability of a search space is highly connected with your tuner. We listed the supported types for each builtin tuner below. For a customized tuner, you don’t have to follow our convention and you will have the flexibility to define any type you want.
Types¶
All types of sampling strategies and their parameter are listed here:
{"_type": "choice", "_value": options}- Which means the variable’s value is one of the options. Here
optionsshould be a list of numbers or a list of strings. Using arbitrary objects as members of this list (like sublists, a mixture of numbers and strings, or null values) should work in most cases, but may trigger undefined behaviors. optionscould also be a nested sub-search-space, this sub-search-space takes effect only when the corresponding element is chosen. The variables in this sub-search-space could be seen as conditional variables. Here is an simple example of nested search space definition. If an element in the options list is a dict, it is a sub-search-space, and for our built-in tuners you have to add a key_namein this dict, which helps you to identify which element is chosen. Accordingly, here is a sample which users can get from nni with nested search space definition. Tuners which support nested search space are as follows:- Random Search
- TPE
- Anneal
- Evolution
- Which means the variable’s value is one of the options. Here
{"_type": "randint", "_value": [lower, upper]}- Choosing a random integer from
lower(inclusive) toupper(exclusive). - Note: Different tuners may interpret
randintdifferently. Some (e.g., TPE, GridSearch) treat integers from lower to upper as unordered ones, while others respect the ordering (e.g., SMAC). If you want all the tuners to respect the ordering, please usequniformwithq=1.
- Choosing a random integer from
{"_type": "uniform", "_value": [low, high]}- Which means the variable value is a value uniformly between low and high.
- When optimizing, this variable is constrained to a two-sided interval.
{"_type": "quniform", "_value": [low, high, q]}- Which means the variable value is a value like
clip(round(uniform(low, high) / q) * q, low, high), where the clip operation is used to constraint the generated value in the bound. For example, for_valuespecified as [0, 10, 2.5], possible values are [0, 2.5, 5.0, 7.5, 10.0]; For_valuespecified as [2, 10, 5], possible values are [2, 5, 10]. - Suitable for a discrete value with respect to which the objective is still somewhat “smooth”, but which should be bounded both above and below. If you want to uniformly choose integer from a range [low, high], you can write
_valuelike this:[low, high, 1].
- Which means the variable value is a value like
{"_type": "loguniform", "_value": [low, high]}- Which means the variable value is a value drawn from a range [low, high] according to a loguniform distribution like exp(uniform(log(low), log(high))), so that the logarithm of the return value is uniformly distributed.
- When optimizing, this variable is constrained to be positive.
{"_type": "qloguniform", "_value": [low, high, q]}- Which means the variable value is a value like
clip(round(loguniform(low, high) / q) * q, low, high), where the clip operation is used to constraint the generated value in the bound. - Suitable for a discrete variable with respect to which the objective is “smooth” and gets smoother with the size of the value, but which should be bounded both above and below.
- Which means the variable value is a value like
{"_type": "normal", "_value": [mu, sigma]}- Which means the variable value is a real value that’s normally-distributed with mean mu and standard deviation sigma. When optimizing, this is an unconstrained variable.
{"_type": "qnormal", "_value": [mu, sigma, q]}- Which means the variable value is a value like
round(normal(mu, sigma) / q) * q - Suitable for a discrete variable that probably takes a value around mu, but is fundamentally unbounded.
- Which means the variable value is a value like
{"_type": "lognormal", "_value": [mu, sigma]}- Which means the variable value is a value drawn according to
exp(normal(mu, sigma))so that the logarithm of the return value is normally distributed. When optimizing, this variable is constrained to be positive.
- Which means the variable value is a value drawn according to
{"_type": "qlognormal", "_value": [mu, sigma, q]}- Which means the variable value is a value like
round(exp(normal(mu, sigma)) / q) * q - Suitable for a discrete variable with respect to which the objective is smooth and gets smoother with the size of the variable, which is bounded from one side.
- Which means the variable value is a value like
Search Space Types Supported by Each Tuner¶
| choice | randint | uniform | quniform | loguniform | qloguniform | normal | qnormal | lognormal | qlognormal | |
|---|---|---|---|---|---|---|---|---|---|---|
| TPE Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Random Search Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Anneal Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Evolution Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SMAC Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Batch Tuner | ✓ | |||||||||
| Grid Search Tuner | ✓ | ✓ | ✓ | |||||||
| Hyperband Advisor | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Metis Tuner | ✓ | ✓ | ✓ | ✓ | ||||||
| GP Tuner | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Known Limitations:
- GP Tuner and Metis Tuner support only numerical values in search space (
choicetype values can be no-numeraical with other tuners, e.g. string values). Both GP Tuner and Metis Tuner use Gaussian Process Regressor(GPR). GPR make predictions based on a kernel function and the ‘distance’ between different points, it’s hard to get the true distance between no-numerical values. - Note that for nested search space:
- Only Random Search/TPE/Anneal/Evolution tuner supports nested search space
- We do not support nested search space “Hyper Parameter” in visualization now, the enhancement is being considered in #1110, any suggestions or discussions or contributions are warmly welcomed
NNI Annotation¶
Overview¶
To improve user experience and reduce user effort, we design an annotation grammar. Using NNI annotation, users can adapt their code to NNI just by adding some standalone annotating strings, which does not affect the execution of the original code.
Below is an example:
'''@nni.variable(nni.choice(0.1, 0.01, 0.001), name=learning_rate)'''
learning_rate = 0.1
The meaning of this example is that NNI will choose one of several values (0.1, 0.01, 0.001) to assign to the learning_rate variable. Specifically, this first line is an NNI annotation, which is a single string. Following is an assignment statement. What nni does here is to replace the right value of this assignment statement according to the information provided by the annotation line.
In this way, users could either run the python code directly or launch NNI to tune hyper-parameter in this code, without changing any codes.
Types of Annotation:¶
In NNI, there are mainly four types of annotation:
1. Annotate variables¶
'''@nni.variable(sampling_algo, name)'''
@nni.variable is used in NNI to annotate a variable.
Arguments
- sampling_algo: Sampling algorithm that specifies a search space. User should replace it with a built-in NNI sampling function whose name consists of an
nni.identification and a search space type specified in SearchSpaceSpec such aschoiceoruniform. - name: The name of the variable that the selected value will be assigned to. Note that this argument should be the same as the left value of the following assignment statement.
There are 10 types to express your search space as follows:
@nni.variable(nni.choice(option1,option2,...,optionN),name=variable)Which means the variable value is one of the options, which should be a list The elements of options can themselves be stochastic expressions@nni.variable(nni.randint(lower, upper),name=variable)Which means the variable value is a value like round(uniform(low, high)). For now, the type of chosen value is float. If you want to use integer value, please convert it explicitly.@nni.variable(nni.uniform(low, high),name=variable)Which means the variable value is a value uniformly between low and high.@nni.variable(nni.quniform(low, high, q),name=variable)Which means the variable value is a value like clip(round(uniform(low, high) / q) * q, low, high), where the clip operation is used to constraint the generated value in the bound.@nni.variable(nni.loguniform(low, high),name=variable)Which means the variable value is a value drawn according to exp(uniform(low, high)) so that the logarithm of the return value is uniformly distributed.@nni.variable(nni.qloguniform(low, high, q),name=variable)Which means the variable value is a value like clip(round(loguniform(low, high) / q) * q, low, high), where the clip operation is used to constraint the generated value in the bound.@nni.variable(nni.normal(mu, sigma),name=variable)Which means the variable value is a real value that’s normally-distributed with mean mu and standard deviation sigma.@nni.variable(nni.qnormal(mu, sigma, q),name=variable)Which means the variable value is a value like round(normal(mu, sigma) / q) * q@nni.variable(nni.lognormal(mu, sigma),name=variable)Which means the variable value is a value drawn according to exp(normal(mu, sigma))@nni.variable(nni.qlognormal(mu, sigma, q),name=variable)Which means the variable value is a value like round(exp(normal(mu, sigma)) / q) * q
Below is an example:
'''@nni.variable(nni.choice(0.1, 0.01, 0.001), name=learning_rate)'''
learning_rate = 0.1
2. Annotate functions¶
'''@nni.function_choice(*functions, name)'''
@nni.function_choice is used to choose one from several functions.
Arguments
- functions: Several functions that are waiting to be selected from. Note that it should be a complete function call with arguments. Such as
max_pool(hidden_layer, pool_size). - name: The name of the function that will be replaced in the following assignment statement.
An example here is:
"""@nni.function_choice(max_pool(hidden_layer, pool_size), avg_pool(hidden_layer, pool_size), name=max_pool)"""
h_pooling = max_pool(hidden_layer, pool_size)
3. Annotate intermediate result¶
'''@nni.report_intermediate_result(metrics)'''
@nni.report_intermediate_result is used to report intermediate result, whose usage is the same as nni.report_intermediate_result in the doc of Write a trial run on NNI
4. Annotate final result¶
'''@nni.report_final_result(metrics)'''
@nni.report_final_result is used to report the final result of the current trial, whose usage is the same as nni.report_final_result in the doc of Write a trial run on NNI
Python API Reference¶
Python API Reference of Auto Tune¶
Trial¶
-
nni.get_next_parameter()[source]¶ Get the hyper paremeters generated by tuner. For a multiphase experiment, it returns a new group of hyper parameters at each call of get_next_parameter. For a non-multiphase (multiPhase is not configured or set to False) experiment, it returns hyper parameters only on the first call for each trial job, it returns None since second call. This API should be called only once in each trial job of an experiment which is not specified as multiphase.
Returns: A dict object contains the hyper parameters generated by tuner, the keys of the dict are defined in search space. Returns None if no more hyper parameters can be generated by tuner. Return type: dict
-
nni.get_current_parameter(tag=None)[source]¶ Get current hyper parameters generated by tuner. It returns the same group of hyper parameters as the last call of get_next_parameter returns.
Parameters: tag (str) – hyper parameter key
-
nni.report_intermediate_result(metric)[source]¶ Reports intermediate result to NNI.
Parameters: metric – serializable object.
-
nni.report_final_result(metric)[source]¶ Reports final result to NNI.
Parameters: metric (serializable object) – Usually (for built-in tuners to work), it should be a number, or a dict with key “default” (a number), and any other extra keys.
-
nni.get_experiment_id()[source]¶ Get experiment ID.
Returns: Identifier of current experiment Return type: str
-
nni.get_trial_id()[source]¶ Get trial job ID which is string identifier of a trial job, for example ‘MoXrp’. In one experiment, each trial job has an unique string ID.
Returns: Identifier of current trial job which is calling this API. Return type: str
-
nni.get_sequence_id()[source]¶ Get trial job sequence nubmer. A sequence number is an integer value assigned to each trial job base on the order they are submitted, incremental starting from 0. In one experiment, both trial job ID and sequence number are unique for each trial job, they are of different data types.
Returns: Sequence number of current trial job which is calling this API. Return type: int
Tuner¶
-
class
nni.tuner.Tuner[source]¶ Tuner is an AutoML algorithm, which generates a new configuration for the next try. A new trial will run with this configuration.
This is the abstract base class for all tuners. Tuning algorithms should inherit this class and override
update_search_space(),receive_trial_result(), as well asgenerate_parameters()orgenerate_multiple_parameters().After initializing, NNI will first call
update_search_space()to tell tuner the feasible region, and then callgenerate_parameters()one or more times to request for hyper-parameter configurations.The framework will train several models with given configuration. When one of them is finished, the final accuracy will be reported to
receive_trial_result(). And then another configuration will be reqeusted and trained, util the whole experiment finish.If a tuner want’s to know when a trial ends, it can also override
trial_end().Tuners use parameter ID to track trials. In tuner context, there is a one-to-one mapping between parameter ID and trial. When the framework ask tuner to generate hyper-parameters for a new trial, an ID has already been assigned and can be recorded in
generate_parameters(). Later when the trial ends, the ID will be reported totrial_end(), andreceive_trial_result()if it has a final result. Parameter IDs are unique integers.The type/format of search space and hyper-parameters are not limited, as long as they are JSON-serializable and in sync with trial code. For HPO tuners, however, there is a widely shared common interface, which supports
choice,randint,uniform, and so on. Seedocs/en_US/Tutorial/SearchSpaceSpec.mdfor details of this interface.[WIP] For advanced tuners which take advantage of trials’ intermediate results, an
Advisorinterface is under development.See also
Builtin tuners:
HyperoptTunerEvolutionTunerSMACTunerGridSearchTunerNetworkMorphismTunerMetisTunerPPOTunerGPTuner-
generate_multiple_parameters(parameter_id_list, **kwargs)[source]¶ Callback method which provides multiple sets of hyper-parameters.
This method will get called when the framework is about to launch one or more new trials.
If user does not override this method, it will invoke
generate_parameters()on each parameter ID.See
generate_parameters()for details.User code must override either this method or
generate_parameters().Parameters: - parameter_id_list (list of int) – Unique identifiers for each set of requested hyper-parameters.
These will later be used in
receive_trial_result(). - **kwargs – Unstable parameters which should be ignored by normal users.
Returns: List of hyper-parameters. An empty list indicates there are no more trials.
Return type: list
- parameter_id_list (list of int) – Unique identifiers for each set of requested hyper-parameters.
These will later be used in
-
generate_parameters(parameter_id, **kwargs)[source]¶ Abstract method which provides a set of hyper-parameters.
This method will get called when the framework is about to launch a new trial, if user does not override
generate_multiple_parameters().The return value of this method will be received by trials via
nni.get_next_parameter(). It should fit in the search space, though the framework will not verify this.User code must override either this method or
generate_multiple_parameters().Parameters: - parameter_id (int) – Unique identifier for requested hyper-parameters. This will later be used in
receive_trial_result(). - **kwargs – Unstable parameters which should be ignored by normal users.
Returns: The hyper-parameters, a dict in most cases, but could be any JSON-serializable type when needed.
Return type: any
Raises: nni.NoMoreTrialError– If the search space is fully explored, tuner can raise this exception.- parameter_id (int) – Unique identifier for requested hyper-parameters. This will later be used in
-
receive_trial_result(parameter_id, parameters, value, **kwargs)[source]¶ Abstract method invoked when a trial reports its final result. Must override.
This method only listens to results of algorithm-generated hyper-parameters. Currently customized trials added from web UI will not report result to this method.
Parameters: - parameter_id (int) – Unique identifier of used hyper-parameters, same with
generate_parameters(). - parameters – Hyper-parameters generated by
generate_parameters(). - value – Result from trial (the return value of
nni.report_final_result()). - **kwargs – Unstable parameters which should be ignored by normal users.
- parameter_id (int) – Unique identifier of used hyper-parameters, same with
-
trial_end(parameter_id, success, **kwargs)[source]¶ Abstract method invoked when a trial is completed or terminated. Do nothing by default.
Parameters: - parameter_id (int) – Unique identifier for hyper-parameters used by this trial.
- success (bool) – True if the trial successfully completed; False if failed or terminated.
- **kwargs – Unstable parameters which should be ignored by normal users.
-
update_search_space(search_space)[source]¶ Abstract method for updating the search space. Must override.
Tuners are advised to support updating search space at run-time. If a tuner can only set search space once before generating first hyper-parameters, it should explicitly document this behaviour.
Parameters: search_space – JSON object defined by experiment owner.
-
-
class
nni.hyperopt_tuner.hyperopt_tuner.HyperoptTuner(algorithm_name, optimize_mode='minimize', parallel_optimize=False, constant_liar_type='min')[source]¶ HyperoptTuner is a tuner which using hyperopt algorithm.
-
generate_parameters(parameter_id, **kwargs)[source]¶ Returns a set of trial (hyper-)parameters, as a serializable object.
Parameters: parameter_id (int) – Returns: params Return type: dict
-
get_suggestion(random_search=False)[source]¶ get suggestion from hyperopt
Parameters: random_search (bool) – flag to indicate random search or not (default: {False}) Returns: total_params – parameter suggestion Return type: dict
-
import_data(data)[source]¶ Import additional data for tuning
Parameters: data – a list of dictionarys, each of which has at least two keys, ‘parameter’ and ‘value’
-
miscs_update_idxs_vals(miscs, idxs, vals, assert_all_vals_used=True, idxs_map=None)[source]¶ Unpack the idxs-vals format into the list of dictionaries that is misc.
Parameters: - idxs_map (dict) – idxs_map is a dictionary of id->id mappings so that the misc[‘idxs’] can
- different numbers than the idxs argument. (contain) –
-
-
class
nni.evolution_tuner.evolution_tuner.EvolutionTuner(optimize_mode='maximize', population_size=32)[source]¶ EvolutionTuner is tuner using navie evolution algorithm.
-
generate_parameters(parameter_id, **kwargs)[source]¶ This function will returns a dict of trial (hyper-)parameters, as a serializable object.
Parameters: parameter_id (int) – Returns: A group of candaidte parameters that evolution tuner generated. Return type: dict
-
-
class
nni.gridsearch_tuner.GridSearchTuner[source]¶ GridSearchTuner will search all the possible configures that the user define in the searchSpace. The only acceptable types of search space are
choice,quniform,randintType
choicewill select one of the options. Note that it can also be nested.Type
quniformwill receive three values [low,high,q], where [low,high] specifies a range andqspecifies the interval. It will be sampled in a way that the first sampled value islow, and each of the following values is ‘interval’ larger than the value in front of it.Type
randintgives all possible intergers in range[low,high). Note thathighis not included.-
generate_parameters(parameter_id, **kwargs)[source]¶ Generate parameters for one trial.
Parameters: - parameter_id (int) – The id for the generated hyperparameter
- **kwargs – Not used
Returns: One configuration from the expanded search space.
Return type: dict
Raises: NoMoreTrialError– If all the configurations has been sent, raiseNoMoreTrialError.
-
import_data(data)[source]¶ Import additional data for tuning
Parameters: list – A list of dictionarys, each of which has at least two keys, parameterandvalue
-
receive_trial_result(parameter_id, parameters, value, **kwargs)[source]¶ Receive a trial’s final performance result reported through
report_final_result()by the trial. GridSearchTuner does not need trial’s results.
-
update_search_space(search_space)[source]¶ Check if the search space is valid and expand it: support only
choice,quniform,randint.Parameters: search_space (dict) – The format could be referred to search space spec (https://nni.readthedocs.io/en/latest/Tutorial/SearchSpaceSpec.html).
-
-
class
nni.networkmorphism_tuner.networkmorphism_tuner.NetworkMorphismTuner(task='cv', input_width=32, input_channel=3, n_output_node=10, algorithm_name='Bayesian', optimize_mode='maximize', path='model_path', verbose=True, beta=2.576, t_min=0.0001, max_model_size=16777216, default_model_len=3, default_model_width=64)[source]¶ NetworkMorphismTuner is a tuner which using network morphism techniques.
-
n_classes¶ The class number or output node number (default:
10)Type: int
-
input_shape¶ A tuple including: (input_width, input_width, input_channel)
Type: tuple
-
t_min¶ The minimum temperature for simulated annealing. (default:
Constant.T_MIN)Type: float
-
beta¶ The beta in acquisition function. (default:
Constant.BETA)Type: float
-
algorithm_name¶ algorithm name used in the network morphism (default:
"Bayesian")Type: str
-
optimize_mode¶ optimize mode “minimize” or “maximize” (default:
"minimize")Type: str
-
verbose¶ verbose to print the log (default:
True)Type: bool
-
bo¶ The optimizer used in networkmorphsim tuner.
Type: BayesianOptimizer
-
max_model_size¶ max model size to the graph (default:
Constant.MAX_MODEL_SIZE)Type: int
-
default_model_len¶ default model length (default:
Constant.MODEL_LEN)Type: int
-
default_model_width¶ default model width (default:
Constant.MODEL_WIDTH)Type: int
-
search_space¶ Type: dict
-
add_model(metric_value, model_id)[source]¶ Add model to the history, x_queue and y_queue
Parameters: - metric_value (float) –
- graph (dict) –
- model_id (int) –
Returns: model
Return type: dict
-
generate()[source]¶ Generate the next neural architecture.
Returns: - other_info (any object) – Anything to be saved in the training queue together with the architecture.
- generated_graph (Graph) – An instance of Graph.
-
generate_parameters(parameter_id, **kwargs)[source]¶ Returns a set of trial neural architecture, as a serializable object.
Parameters: parameter_id (int) –
-
get_metric_value_by_id(model_id)[source]¶ Get the model metric valud by its model_id
Parameters: model_id (int) – model index Returns: the model metric Return type: float
-
load_best_model()[source]¶ Get the best model by model id
Returns: load_model – the model graph representation Return type: Graph
-
load_model_by_id(model_id)[source]¶ Get the model by model_id
Parameters: model_id (int) – model index Returns: load_model – the model graph representation Return type: Graph
-
receive_trial_result(parameter_id, parameters, value, **kwargs)[source]¶ Record an observation of the objective function.
Parameters: - parameter_id (int) – the id of a group of paramters that generated by nni manager.
- parameters (dict) – A group of parameters.
- value (dict/float) – if value is dict, it should have “default” key.
-
update(other_info, graph, metric_value, model_id)[source]¶ Update the controller with evaluation result of a neural architecture.
Parameters: - other_info (any object) – In our case it is the father ID in the search tree.
- graph (Graph) – An instance of Graph. The trained neural architecture.
- metric_value (float) – The final evaluated metric value.
- model_id (int) –
-
-
class
nni.metis_tuner.metis_tuner.MetisTuner(optimize_mode='maximize', no_resampling=True, no_candidates=False, selection_num_starting_points=600, cold_start_num=10, exploration_probability=0.9)[source]¶ Metis Tuner
More algorithm information you could reference here: https://www.microsoft.com/en-us/research/publication/metis-robustly-tuning-tail-latencies-cloud-systems/
-
optimize_mode¶ optimize_mode is a string that including two mode “maximize” and “minimize”
Type: str
-
no_resampling¶ True or False. Should Metis consider re-sampling as part of the search strategy? If you are confident that the training dataset is noise-free, then you do not need re-sampling.
Type: bool
-
no_candidates¶ True or False. Should Metis suggest parameters for the next benchmark? If you do not plan to do more benchmarks, Metis can skip this step.
Type: bool
-
selection_num_starting_points¶ How many times Metis should try to find the global optimal in the search space? The higher the number, the longer it takes to output the solution.
Type: int
-
cold_start_num¶ Metis need some trial result to get cold start. when the number of trial result is less than cold_start_num, Metis will randomly sample hyper-parameter for trial.
Type: int
-
exploration_probability¶ The probability of Metis to select parameter from exploration instead of exploitation.
Type: float
-
generate_parameters(parameter_id, **kwargs)[source]¶ Generate next parameter for trial
If the number of trial result is lower than cold start number, metis will first random generate some parameters. Otherwise, metis will choose the parameters by the Gussian Process Model and the Gussian Mixture Model.
Parameters: parameter_id (int) – Returns: result Return type: dict
-
import_data(data)[source]¶ Import additional data for tuning
Parameters: data (a list of dict) – each of which has at least two keys: ‘parameter’ and ‘value’.
-
receive_trial_result(parameter_id, parameters, value, **kwargs)[source]¶ Tuner receive result from trial.
Parameters: - parameter_id (int) – The id of parameters, generated by nni manager.
- parameters (dict) – A group of parameters that trial has tried.
- value (dict/float) – if value is dict, it should have “default” key.
-
-
class
nni.batch_tuner.batch_tuner.BatchTuner[source]¶ BatchTuner is tuner will running all the configure that user want to run batchly.
Examples
The search space only be accepted like:
{'combine_params': { '_type': 'choice', '_value': '[{...}, {...}, {...}]', } }
-
generate_parameters(parameter_id, **kwargs)[source]¶ Returns a dict of trial (hyper-)parameters, as a serializable object.
Parameters: parameter_id (int) – Returns: A candidate parameter group. Return type: dict
-
import_data(data)[source]¶ Import additional data for tuning
Parameters: data – a list of dictionarys, each of which has at least two keys, ‘parameter’ and ‘value’
-
is_valid(search_space)[source]¶ Check the search space is valid: only contains ‘choice’ type
Parameters: search_space (dict) – Returns: If valid, return candidate values; else return None. Return type: None or list
-
receive_trial_result(parameter_id, parameters, value, **kwargs)[source]¶ Abstract method invoked when a trial reports its final result. Must override.
This method only listens to results of algorithm-generated hyper-parameters. Currently customized trials added from web UI will not report result to this method.
Parameters: - parameter_id (int) – Unique identifier of used hyper-parameters, same with
generate_parameters(). - parameters – Hyper-parameters generated by
generate_parameters(). - value – Result from trial (the return value of
nni.report_final_result()). - **kwargs – Unstable parameters which should be ignored by normal users.
- parameter_id (int) – Unique identifier of used hyper-parameters, same with
-
-
class
nni.gp_tuner.gp_tuner.GPTuner(optimize_mode='maximize', utility='ei', kappa=5, xi=0, nu=2.5, alpha=1e-06, cold_start_num=10, selection_num_warm_up=100000, selection_num_starting_points=250)[source]¶ GPTuner is a Bayesian Optimization method where Gaussian Process is used for modeling loss functions.
Parameters: - optimize_mode (str) – optimize mode, ‘maximize’ or ‘minimize’, by default ‘maximize’
- utility (str) – utility function (also called ‘acquisition funcition’) to use, which can be ‘ei’, ‘ucb’ or ‘poi’. By default ‘ei’.
- kappa (float) – value used by utility function ‘ucb’. The bigger kappa is, the more the tuner will be exploratory. By default 5.
- xi (float) – used by utility function ‘ei’ and ‘poi’. The bigger xi is, the more the tuner will be exploratory. By default 0.
- nu (float) – used to specify Matern kernel. The smaller nu, the less smooth the approximated function is. By default 2.5.
- alpha (float) – Used to specify Gaussian Process Regressor. Larger values correspond to increased noise level in the observations. By default 1e-6.
- cold_start_num (int) – Number of random exploration to perform before Gaussian Process. By default 10.
- selection_num_warm_up (int) – Number of random points to evaluate for getting the point which maximizes the acquisition function. By default 100000
- selection_num_starting_points (int) – Number of times to run L-BFGS-B from a random starting point after the warmup. By default 250.
-
generate_parameters(parameter_id, **kwargs)[source]¶ Method which provides one set of hyper-parameters. If the number of trial result is lower than cold_start_number, GPTuner will first randomly generate some parameters. Otherwise, choose the parameters by the Gussian Process Model.
Override of the abstract method in
Tuner.
-
import_data(data)[source]¶ Import additional data for tuning.
Override of the abstract method in
Tuner.
Assessor¶
-
class
nni.assessor.Assessor[source]¶ Assessor analyzes trial’s intermediate results (e.g., periodically evaluated accuracy on test dataset) to tell whether this trial can be early stopped or not.
This is the abstract base class for all assessors. Early stopping algorithms should inherit this class and override
assess_trial()method, which receives intermediate results from trials and give an assessing result.If
assess_trial()returnsAssessResult.Badfor a trial, it hints NNI framework that the trial is likely to result in a poor final accuracy, and therefore should be killed to save resource.If an accessor want’s to be notified when a trial ends, it can also override
trial_end().To write a new assessor, you can reference
MedianstopAssessor’s code as an example.See also
Builtin assessors:
MedianstopAssessorCurvefittingAssessor-
assess_trial(trial_job_id, trial_history)[source]¶ Abstract method for determining whether a trial should be killed. Must override.
The NNI framework has little guarantee on
trial_history. This method is not guaranteed to be invoked for each timetrial_historyget updated. It is also possible that a trial’s history keeps updating after receiving a bad result. And if the trial failed and retried,trial_historymay be inconsistent with its previous value.The only guarantee is that
trial_historyis always growing. It will not be empty and will always be longer than previous value.This is an example of how
assess_trial()get invoked sequentially:trial_job_id | trial_history | return value ------------ | --------------- | ------------ Trial_A | [1.0, 2.0] | Good Trial_B | [1.5, 1.3] | Bad Trial_B | [1.5, 1.3, 1.9] | Good Trial_A | [0.9, 1.8, 2.3] | Good
Parameters: - trial_job_id (str) – Unique identifier of the trial.
- trial_history (list) – Intermediate results of this trial. The element type is decided by trial code.
Returns: Return type:
-
-
class
nni.assessor.AssessResult[source]¶ Enum class for
Assessor.assess_trial()return value.-
Bad= False¶ The trial works poorly and should be early stopped.
-
Good= True¶ The trial works well.
-
-
class
nni.curvefitting_assessor.CurvefittingAssessor(epoch_num=20, start_step=6, threshold=0.95, gap=1)[source]¶ CurvefittingAssessor uses learning curve fitting algorithm to predict the learning curve performance in the future. It stops a pending trial X at step S if the trial’s forecast result at target step is convergence and lower than the best performance in the history.
Parameters: - epoch_num (int) – The total number of epoch
- start_step (int) – only after receiving start_step number of reported intermediate results
- threshold (float) – The threshold that we decide to early stop the worse performance curve.
-
assess_trial(trial_job_id, trial_history)[source]¶ assess whether a trial should be early stop by curve fitting algorithm
Parameters: - trial_job_id (int) – trial job id
- trial_history (list) – The history performance matrix of each trial
Returns: AssessResult.Good or AssessResult.Bad
Return type: bool
Raises: Exception– unrecognize exception in curvefitting_assessor
-
class
nni.medianstop_assessor.MedianstopAssessor(optimize_mode='maximize', start_step=0)[source]¶ MedianstopAssessor is The median stopping rule stops a pending trial X at step S if the trial’s best objective value by step S is strictly worse than the median value of the running averages of all completed trials’ objectives reported up to step S
Parameters: - optimize_mode (str) – optimize mode, ‘maximize’ or ‘minimize’
- start_step (int) – only after receiving start_step number of reported intermediate results
Advisor¶
-
class
nni.msg_dispatcher_base.MsgDispatcherBase[source]¶ This is where tuners and assessors are not defined yet. Inherits this class to make your own advisor.
-
handle_import_data(data)[source]¶ Import previous data when experiment is resumed. :param data: a list of dictionaries, each of which has at least two keys, ‘parameter’ and ‘value’ :type data: list
-
handle_initialize(data)[source]¶ Initialize search space and tuner, if any This method is meant to be called only once for each experiment, after calling this method, dispatcher should send(CommandType.Initialized, ‘’), to set the status of the experiment to be “INITIALIZED”. :param data: search space :type data: dict
-
handle_report_metric_data(data)[source]¶ Called when metric data is reported or new parameters are requested (for multiphase). When new parameters are requested, this method should send a new parameter.
Parameters: data (dict) – a dict which contains ‘parameter_id’, ‘value’, ‘trial_job_id’, ‘type’, ‘sequence’. type: can be MetricType.REQUEST_PARAMETER, MetricType.FINAL or MetricType.PERIODICAL. REQUEST_PARAMETER is used to request new parameters for multiphase trial job. In this case, the dict will contain additional keys: trial_job_id, parameter_index. Refer to msg_dispatcher.py as an example. Raises: ValueError– Data type is not supported
-
handle_request_trial_jobs(data)[source]¶ The message dispatcher is demanded to generate
datatrial jobs. These trial jobs should be sent viasend(CommandType.NewTrialJob, json_tricks.dumps(parameter)), whereparameterwill be received by NNI Manager and eventually accessible to trial jobs as “next parameter”. Semantically, message dispatcher should do thissendexactlydatatimes.The JSON sent by this method should follow the format of
{ "parameter_id": 42 "parameters": { // this will be received by trial }, "parameter_source": "algorithm" // optional }
Parameters: data (int) – number of trial jobs
-
handle_trial_end(data)[source]¶ Called when the state of one of the trials is changed
Parameters: data (dict) – a dict with keys: trial_job_id, event, hyper_params. trial_job_id: the id generated by training service. event: the job’s state. hyper_params: the string that is sent by message dispatcher during the creation of trials.
-
-
class
nni.hyperband_advisor.hyperband_advisor.Hyperband(R=60, eta=3, optimize_mode='maximize')[source]¶ Hyperband inherit from MsgDispatcherBase rather than Tuner, because it integrates both tuner’s functions and assessor’s functions. This is an implementation that could fully leverage available resources, i.e., high parallelism. A single execution of Hyperband takes a finite budget of (s_max + 1)B.
Parameters: - R (int) – the maximum amount of resource that can be allocated to a single configuration
- eta (int) – the variable that controls the proportion of configurations discarded in each round of SuccessiveHalving
- optimize_mode (str) – optimize mode, ‘maximize’ or ‘minimize’
-
handle_import_data(data)[source]¶ Import previous data when experiment is resumed. :param data: a list of dictionaries, each of which has at least two keys, ‘parameter’ and ‘value’ :type data: list
-
handle_initialize(data)[source]¶ callback for initializing the advisor :param data: search space :type data: dict
-
handle_report_metric_data(data)[source]¶ Parameters: data – it is an object which has keys ‘parameter_id’, ‘value’, ‘trial_job_id’, ‘type’, ‘sequence’. Raises: ValueError– Data type not supported
Utilities¶
-
nni.utils.merge_parameter(base_params, override_params)[source]¶ Update the parameters in
base_paramswithoverride_params. Can be useful to override parsed command line arguments.Parameters: - base_params (namespace or dict) – Base parameters. A key-value mapping.
- override_params (dict or None) – Parameters to override. Usually the parameters got from
get_next_parameters(). When it is none, nothing will happen.
Returns: The updated
base_params. Note thatbase_paramswill be updated inplace. The return value is only for convenience.Return type: namespace or dict
Python API Reference of Compression Utilities¶
Contents
Sensitivity Utilities¶
-
class
nni.compression.torch.utils.sensitivity_analysis.SensitivityAnalysis(model, val_func, sparsities=None, prune_type='l1', early_stop_mode=None, early_stop_value=None)[source]¶ -
analysis(val_args=None, val_kwargs=None, specified_layers=None)[source]¶ This function analyze the sensitivity to pruning for each conv layer in the target model. If start and end are not set, we analyze all the conv layers by default. Users can specify several layers to analyze or parallelize the analysis process easily through the start and end parameter.
Parameters: - val_args (list) – args for the val_function
- val_kwargs (dict) – kwargs for the val_funtion
- specified_layers (list) – list of layer names to analyze sensitivity. If this variable is set, then only analyze the conv layers that specified in the list. User can also use this option to parallelize the sensitivity analysis easily.
Returns: sensitivities – dict object that stores the trajectory of the accuracy/loss when the prune ratio changes
Return type: dict
-
export(filepath)[source]¶ Export the results of the sensitivity analysis to a csv file. The firstline of the csv file describe the content structure. The first line is constructed by ‘layername’ and sparsity list. Each line below records the validation metric returned by val_func when this layer is under different sparsities. Note that, due to the early_stop option, some layers may not have the metrics under all sparsities.
layername, 0.25, 0.5, 0.75 conv1, 0.6, 0.55 conv2, 0.61, 0.57, 0.56
Parameters: filepath (str) – Path of the output file
-
Topology Utilities¶
-
class
nni.compression.torch.utils.shape_dependency.ChannelDependency(model=None, dummy_input=None, traced_model=None)[source]¶ -
-
dependency_sets¶ Get the list of the dependency set.
Returns: dependency_sets – list of the dependency sets. For example, [set([‘conv1’, ‘conv2’]), set([‘conv3’, ‘conv4’])] Return type: list
-
export(filepath)[source]¶ export the channel dependencies as a csv file. The layers at the same line have output channel dependencies with each other. For example, layer1.1.conv2, conv1, and layer1.0.conv2 have output channel dependencies with each other, which means the output channel(filters) numbers of these three layers should be same with each other, otherwise the model may has shape conflict.
Output example: Dependency Set,Convolutional Layers Set 1,layer1.1.conv2,layer1.0.conv2,conv1 Set 2,layer1.0.conv1 Set 3,layer1.1.conv1
-
-
class
nni.compression.torch.utils.shape_dependency.GroupDependency(model=None, dummy_input=None, traced_model=None)[source]¶ -
build_dependency()[source]¶ Build the channel dependency for the conv layers in the model. This function return the group number of each conv layers. Note that, here, the group count of conv layers may be larger than their originl groups. This is because that the input channel will also be grouped for the group conv layers. To make this clear, assume we have two group conv layers: conv1(group=2), conv2(group=4). conv2 takes the output features of conv1 as input. Then we have to the filters of conv1 can still be divided into 4 groups after filter pruning, because the input channels of conv2 shoule be divided into 4 groups.
Returns: self.dependency – key: the name of conv layers, value: the minimum value that the number of filters should be divisible to. Return type: dict
-
export(filepath)[source]¶ export the group dependency to a csv file. Each line describes a convolution layer, the first part of each line is the Pytorch module name of the conv layer. The second part of each line is the group count of the filters in this layer. Note that, the group count may be larger than this layers original group number.
output example: Conv layer, Groups Conv1, 1 Conv2, 2 Conv3, 4
-
-
class
nni.compression.torch.utils.mask_conflict.CatMaskPadding(masks, model, dummy_input=None, traced=None)[source]¶
-
class
nni.compression.torch.utils.mask_conflict.GroupMaskConflict(masks, model=None, dummy_input=None, traced=None)[source]¶
Model FLOPs/Parameters Counter¶
-
nni.compression.torch.utils.counter.count_flops_params(model: torch.nn.modules.module.Module, input_size, verbose=True)[source]¶ Count FLOPs and Params of the given model. This function would identify the mask on the module and take the pruned shape into consideration. Note that, for sturctured pruning, we only identify the remained filters according to its mask, which not taking the pruned input channels into consideration, so the calculated FLOPs will be larger than real number.
Parameters: - model (nn.Module) – target model.
- input_size (list, tuple) – the input shape of data
Returns: - flops (float) – total flops of the model
- params – total params of the model
Framework and Library Supports¶
With the built-in Python API, NNI naturally supports the hyper parameter tuning and neural network search for all the AI frameworks and libraries who support Python models(version >= 3.5). NNI had also provided a set of examples and tutorials for some of the popular scenarios to make jump start easier.
Supported AI Frameworks¶
[PyTorch] https://github.com/pytorch/pytorch
[TensorFlow] https://github.com/tensorflow/tensorflow
[Keras] https://github.com/keras-team/keras
[MXNet] https://github.com/apache/incubator-mxnet
[Caffe2] https://github.com/BVLC/caffe
[CNTK (Python language)] https://github.com/microsoft/CNTK
[Spark MLlib] http://spark.apache.org/mllib/
[Chainer] https://chainer.org/
[Theano] https://pypi.org/project/Theano/
You are encouraged to contribute more examples for other NNI users.
Supported Library¶
NNI also supports all libraries written in python.Here are some common libraries, including some algorithms based on GBDT: XGBoost, CatBoost and lightGBM.
[Scikit-learn] https://scikit-learn.org/stable/
[XGBoost] https://xgboost.readthedocs.io/en/latest/
[CatBoost] https://catboost.ai/
[LightGBM] https://lightgbm.readthedocs.io/en/latest/
Here is just a small list of libraries that supported by NNI. If you are interested in NNI, you can refer to the tutorial to complete your own hacks.
In addition to the above examples, we also welcome more and more users to apply NNI to your own work, if you have any doubts, please refer Write a Trial Run on NNI. In particular, if you want to be a contributor of NNI, whether it is the sharing of examples , writing of Tuner or otherwise, we are all looking forward to your participation.More information please refer to here.
Community Sharings¶
In addtion to the official tutorilas and examples, we encourage community contributors to share their AutoML practices especially the NNI usage practices from their experience.
Automatically tuning SVD on NNI¶
In this tutorial, we first introduce a github repo Recommenders. It is a repository that provides examples and best practices for building recommendation systems, provided as Jupyter notebooks. It has various models that are popular and widely deployed in recommendation systems. To provide a complete end-to-end experience, they present each example in five key tasks, as shown below:
- Prepare Data: Preparing and loading data for each recommender algorithm.
- Model: Building models using various classical and deep learning recommender algorithms such as Alternating Least Squares (ALS) or eXtreme Deep Factorization Machines (xDeepFM).
- Evaluate: Evaluating algorithms with offline metrics.
- Model Select and Optimize: Tuning and optimizing hyperparameters for recommender models.
- Operationalize: Operationalizing models in a production environment on Azure.
The fourth task is tuning and optimizing the model’s hyperparameters, this is where NNI could help. To give a concrete example that NNI tunes the models in Recommenders, let’s demonstrate with the model SVD, and data Movielens100k. There are more than 10 hyperparameters to be tuned in this model.
This Jupyter notebook provided by Recommenders is a very detailed step-by-step tutorial for this example. It uses different built-in tuning algorithms in NNI, including Annealing, SMAC, Random Search, TPE, Hyperband, Metis and Evolution. Finally, the results of different tuning algorithms are compared. Please go through this notebook to learn how to use NNI to tune SVD model, then you could further use NNI to tune other models in Recommenders.
Automatically tuning SPTAG with NNI¶
SPTAG (Space Partition Tree And Graph) is a library for large scale vector approximate nearest neighbor search scenario released by Microsoft Research (MSR) and Microsoft Bing.
This library assumes that the samples are represented as vectors and that the vectors can be compared by L2 distances or cosine distances. Vectors returned for a query vector are the vectors that have smallest L2 distance or cosine distances with the query vector. SPTAG provides two methods: kd-tree and relative neighborhood graph (SPTAG-KDT) and balanced k-means tree and relative neighborhood graph (SPTAG-BKT). SPTAG-KDT is advantageous in index building cost, and SPTAG-BKT is advantageous in search accuracy in very high-dimensional data.
In SPTAG, there are tens of parameters that can be tuned for specified scenarios or datasets. NNI is a great tool for automatically tuning those parameters. The authors of SPTAG tried NNI for the auto tuning and found good-performing parameters easily, thus, they shared the practice of tuning SPTAG on NNI in their document here. Please refer to it for detailed tutorial.
Neural Architecture Search Comparison¶
Posted by Anonymous Author
Train and Compare NAS (Neural Architecture Search) models including Autokeras, DARTS, ENAS and NAO.
Their source code link is as below:
- Autokeras: https://github.com/jhfjhfj1/autokeras
- DARTS: https://github.com/quark0/darts
- ENAS: https://github.com/melodyguan/enas
- NAO: https://github.com/renqianluo/NAO
Experiment Description¶
To avoid over-fitting in CIFAR-10, we also compare the models in the other five datasets including Fashion-MNIST, CIFAR-100, OUI-Adience-Age, ImageNet-10-1 (subset of ImageNet), ImageNet-10-2 (another subset of ImageNet). We just sample a subset with 10 different labels from ImageNet to make ImageNet-10-1 or ImageNet-10-2.
| Dataset | Training Size | Numer of Classes | Descriptions |
|---|---|---|---|
| Fashion-MNIST | 60,000 | 10 | T-shirt/top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag and ankle boot. |
| CIFAR-10 | 50,000 | 10 | Airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships and trucks. |
| CIFAR-100 | 50,000 | 100 | Similar to CIFAR-10 but with 100 classes and 600 images each. |
| OUI-Adience-Age | 26,580 | 8 | 8 age groups/labels (0-2, 4-6, 8-13, 15-20, 25-32, 38-43, 48-53, 60-). |
| ImageNet-10-1 | 9,750 | 10 | Coffee mug, computer keyboard, dining table, wardrobe, lawn mower, microphone, swing, sewing machine, odometer and gas pump. |
| ImageNet-10-2 | 9,750 | 10 | Drum, banj, whistle, grand piano, violin, organ, acoustic guitar, trombone, flute and sax. |
We do not change the default fine-tuning technique in their source code. In order to match each task, the codes of input image shape and output numbers are changed.
Search phase time for all NAS methods is two days as well as the retrain time. Average results are reported based on three repeat times. Our evaluation machines have one Nvidia Tesla P100 GPU, 112GB of RAM and one 2.60GHz CPU (Intel E5-2690).
For NAO, it requires too much computing resources, so we only use NAO-WS which provides the pipeline script.
For AutoKeras, we used 0.2.18 version because it was the latest version when we started the experiment.
NAS Performance¶
| NAS | AutoKeras (%) | ENAS (macro) (%) | ENAS (micro) (%) | DARTS (%) | NAO-WS (%) |
|---|---|---|---|---|---|
| Fashion-MNIST | 91.84 | 95.44 | 95.53 | 95.74 | 95.20 |
| CIFAR-10 | 75.78 | 95.68 | 96.16 | 94.23 | 95.64 |
| CIFAR-100 | 43.61 | 78.13 | 78.84 | 79.74 | 75.75 |
| OUI-Adience-Age | 63.20 | 80.34 | 78.55 | 76.83 | 72.96 |
| ImageNet-10-1 | 61.80 | 77.07 | 79.80 | 80.48 | 77.20 |
| ImageNet-10-2 | 37.20 | 58.13 | 56.47 | 60.53 | 61.20 |
Unfortunately, we cannot reproduce all the results in the paper.
The best or average results reported in the paper:
| NAS | AutoKeras(%) | ENAS (macro) (%) | ENAS (micro) (%) | DARTS (%) | NAO-WS (%) |
|---|---|---|---|---|---|
| CIFAR- 10 | 88.56(best) | 96.13(best) | 97.11(best) | 97.17(average) | 96.47(best) |
For AutoKeras, it has relatively worse performance across all datasets due to its random factor on network morphism.
For ENAS, ENAS (macro) shows good results in OUI-Adience-Age and ENAS (micro) shows good results in CIFAR-10.
For DARTS, it has a good performance on some datasets but we found its high variance in other datasets. The difference among three runs of benchmarks can be up to 5.37% in OUI-Adience-Age and 4.36% in ImageNet-10-1.
For NAO-WS, it shows good results in ImageNet-10-2 but it can perform very poorly in OUI-Adience-Age.
Reference¶
- Jin, Haifeng, Qingquan Song, and Xia Hu. “Efficient neural architecture search with network morphism.” arXiv preprint arXiv:1806.10282 (2018).
- Liu, Hanxiao, Karen Simonyan, and Yiming Yang. “Darts: Differentiable architecture search.” arXiv preprint arXiv:1806.09055 (2018).
- Pham, Hieu, et al. “Efficient Neural Architecture Search via Parameters Sharing.” international conference on machine learning (2018): 4092-4101.
- Luo, Renqian, et al. “Neural Architecture Optimization.” neural information processing systems (2018): 7827-7838.
Hyper Parameter Optimization Comparison¶
Posted by Anonymous Author
Comparison of Hyperparameter Optimization (HPO) algorithms on several problems.
Hyperparameter Optimization algorithms are list below:
All algorithms run in NNI local environment.
Machine Environment:
OS: Linux Ubuntu 16.04 LTS
CPU: Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz 2600 MHz
Memory: 112 GB
NNI Version: v0.7
NNI Mode(local|pai|remote): local
Python version: 3.6
Is conda or virtualenv used?: Conda
is running in docker?: no
AutoGBDT Example¶
Search Space¶
{
"num_leaves": {
"_type": "choice",
"_value": [10, 12, 14, 16, 18, 20, 22, 24, 28, 32, 48, 64, 96, 128]
},
"learning_rate": {
"_type": "choice",
"_value": [0.00001, 0.0001, 0.001, 0.01, 0.05, 0.1, 0.2, 0.5]
},
"max_depth": {
"_type": "choice",
"_value": [-1, 2, 3, 4, 5, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 28, 32, 48, 64, 96, 128]
},
"feature_fraction": {
"_type": "choice",
"_value": [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
},
"bagging_fraction": {
"_type": "choice",
"_value": [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
},
"bagging_freq": {
"_type": "choice",
"_value": [1, 2, 4, 8, 10, 12, 14, 16]
}
}
The total search space is 1,204,224, we set the number of maximum trial to 1000. The time limitation is 48 hours.
Results¶
| Algorithm | Best loss | Average of Best 5 Losses | Average of Best 10 Losses |
|---|---|---|---|
| Random Search | 0.418854 | 0.420352 | 0.421553 |
| Random Search | 0.417364 | 0.420024 | 0.420997 |
| Random Search | 0.417861 | 0.419744 | 0.420642 |
| Grid Search | 0.498166 | 0.498166 | 0.498166 |
| Evolution | 0.409887 | 0.409887 | 0.409887 |
| Evolution | 0.413620 | 0.413875 | 0.414067 |
| Evolution | 0.409887 | 0.409887 | 0.409887 |
| Anneal | 0.414877 | 0.417289 | 0.418281 |
| Anneal | 0.409887 | 0.409887 | 0.410118 |
| Anneal | 0.413683 | 0.416949 | 0.417537 |
| Metis | 0.416273 | 0.420411 | 0.422380 |
| Metis | 0.420262 | 0.423175 | 0.424816 |
| Metis | 0.421027 | 0.424172 | 0.425714 |
| TPE | 0.414478 | 0.414478 | 0.414478 |
| TPE | 0.415077 | 0.417986 | 0.418797 |
| TPE | 0.415077 | 0.417009 | 0.418053 |
| SMAC | 0.408386 | 0.408386 | 0.408386 |
| SMAC | 0.414012 | 0.414012 | 0.414012 |
| SMAC | 0.408386 | 0.408386 | 0.408386 |
| BOHB | 0.410464 | 0.415319 | 0.417755 |
| BOHB | 0.418995 | 0.420268 | 0.422604 |
| BOHB | 0.415149 | 0.418072 | 0.418932 |
| HyperBand | 0.414065 | 0.415222 | 0.417628 |
| HyperBand | 0.416807 | 0.417549 | 0.418828 |
| HyperBand | 0.415550 | 0.415977 | 0.417186 |
| GP | 0.414353 | 0.418563 | 0.420263 |
| GP | 0.414395 | 0.418006 | 0.420431 |
| GP | 0.412943 | 0.416566 | 0.418443 |
In this example, all the algorithms are used with default parameters. For Metis, there are about 300 trials because it runs slowly due to its high time complexity O(n^3) in Gaussian Process.
RocksDB Benchmark ‘fillrandom’ and ‘readrandom’¶
Problem Description¶
DB_Bench is the main tool that is used to benchmark RocksDB’s performance. It has so many hapermeter to tune.
The performance of DB_Bench is associated with the machine configuration and installation method. We run the DB_Benchin the Linux machine and install the Rock in shared library.
Machine configuration¶
RocksDB: version 6.1
CPU: 6 * Intel(R) Xeon(R) CPU E5-2690 v4 @ 2.60GHz
CPUCache: 35840 KB
Keys: 16 bytes each
Values: 100 bytes each (50 bytes after compression)
Entries: 1000000
Storage performance¶
Latency: each IO request will take some time to complete, this is called the average latency. There are several factors that would affect this time including network connection quality and hard disk IO performance.
IOPS: IO operations per second, which means the amount of read or write operations that could be done in one seconds time.
IO size: the size of each IO request. Depending on the operating system and the application/service that needs disk access it will issue a request to read or write a certain amount of data at the same time.
**Throughput (in MB/s) = Average IO size x IOPS **
IOPS is related to online processing ability and we use the IOPS as the metric in my experiment.
Search Space¶
{
"max_background_compactions": {
"_type": "quniform",
"_value": [1, 256, 1]
},
"block_size": {
"_type": "quniform",
"_value": [1, 500000, 1]
},
"write_buffer_size": {
"_type": "quniform",
"_value": [1, 130000000, 1]
},
"max_write_buffer_number": {
"_type": "quniform",
"_value": [1, 128, 1]
},
"min_write_buffer_number_to_merge": {
"_type": "quniform",
"_value": [1, 32, 1]
},
"level0_file_num_compaction_trigger": {
"_type": "quniform",
"_value": [1, 256, 1]
},
"level0_slowdown_writes_trigger": {
"_type": "quniform",
"_value": [1, 1024, 1]
},
"level0_stop_writes_trigger": {
"_type": "quniform",
"_value": [1, 1024, 1]
},
"cache_size": {
"_type": "quniform",
"_value": [1, 30000000, 1]
},
"compaction_readahead_size": {
"_type": "quniform",
"_value": [1, 30000000, 1]
},
"new_table_reader_for_compaction_inputs": {
"_type": "randint",
"_value": [1]
}
}
The search space is enormous (about 10^40) and we set the maximum number of trial to 100 to limit the computation resource.
Results¶
fillrandom’ Benchmark¶
| Model | Best IOPS (Repeat 1) | Best IOPS (Repeat 2) | Best IOPS (Repeat 3) |
|---|---|---|---|
| Random | 449901 | 427620 | 477174 |
| Anneal | 461896 | 467150 | 437528 |
| Evolution | 436755 | 389956 | 389790 |
| TPE | 378346 | 482316 | 468989 |
| SMAC | 491067 | 490472 | 491136 |
| Metis | 444920 | 457060 | 454438 |
Figure:

‘readrandom’ Benchmark¶
| Model | Best IOPS (Repeat 1) | Best IOPS (Repeat 2) | Best IOPS (Repeat 3) |
|---|---|---|---|
| Random | 2276157 | 2285301 | 2275142 |
| Anneal | 2286330 | 2282229 | 2284012 |
| Evolution | 2286524 | 2283673 | 2283558 |
| TPE | 2287366 | 2282865 | 2281891 |
| SMAC | 2270874 | 2284904 | 2282266 |
| Metis | 2287696 | 2283496 | 2277701 |
Figure:

Parallelizing a Sequential Algorithm TPE¶
TPE approaches were actually run asynchronously in order to make use of multiple compute nodes and to avoid wasting time waiting for trial evaluations to complete. For the TPE approach, the so-called constant liar approach was used: each time a candidate point x∗ was proposed, a fake fitness evaluation of the y was assigned temporarily, until the evaluation completed and reported the actual loss f(x∗).
Introduction and Problems¶
Sequential Model-based Global Optimization¶
Sequential Model-Based Global Optimization (SMBO) algorithms have been used in many applications where evaluation of the fitness function is expensive. In an application where the true fitness function f: X → R is costly to evaluate, model-based algorithms approximate f with a surrogate that is cheaper to evaluate. Typically the inner loop in an SMBO algorithm is the numerical optimization of this surrogate, or some transformation of the surrogate. The point x∗ that maximizes the surrogate (or its transformation) becomes the proposal for where the true function f should be evaluated. This active-learning-like algorithm template is summarized in the figure below. SMBO algorithms differ in what criterion they optimize to obtain x∗ given a model (or surrogate) of f, and in they model f via observation history H.

The algorithms in this work optimize the criterion of Expected Improvement (EI). Other criteria have been suggested, such as Probability of Improvement and Expected Improvement, minimizing the Conditional Entropy of the Minimizer, and the bandit-based criterion. We chose to use the EI criterion in TPE because it is intuitive, and has been shown to work well in a variety of settings. Expected improvement is the expectation under some model M of f : X → RN that f(x) will exceed (negatively) some threshold y∗:

Since calculation of p(y|x) is expensive, TPE approach modeled p(y|x) by p(x|y) and p(y).The TPE defines p(x|y) using two such densities:

where l(x) is the density formed by using the observations {x(i)} such that corresponding loss
f(x(i)) was less than y∗ and g(x) is the density formed by using the remaining observations. TPE algorithm depends on a y∗ that is larger than the best observed f(x) so that some points can be used to form l(x). The TPE algorithm chooses y∗ to be some quantile γ of the observed y values, so that p(y<y∗) = γ, but no specific model for p(y) is necessary. The tree-structured form of l and g makes it easy to draw many candidates according to l and evaluate them according to g(x)/l(x). On each iteration, the algorithm returns the candidate x∗ with the greatest EI.
Here is a simulation of the TPE algorithm in a two-dimensional search space. The difference of background color represents different values. It can be seen that TPE combines exploration and exploitation very well. (Black indicates the points of this round samples, and yellow indicates the points has been taken in the history.)

Since EI is a continuous function, the highest x of EI is determined at a certain status. As shown in the figure below, the blue triangle is the point that is most likely to be sampled in this state.

TPE performs well when we use it in sequential, but if we provide a larger concurrency, then there will be a large number of points produced in the same EI state, too concentrated points will reduce the exploration ability of the tuner, resulting in resources waste.
Here is the simulation figure when we set concurrency=60, It can be seen that this phenomenon is obvious.

Research solution¶
Approximated q-EI Maximization¶
The multi-points criterion that we have presented below can potentially be used to deliver an additional design of experiments in one step through the resolution of the optimization problem.

However, the computation of q-EI becomes intensive as q increases. After our research, there are four popular greedy strategies that approach the result of problem while avoiding its numerical cost.
Solution 1: Believing the OK Predictor: The KB(Kriging Believer) Heuristic Strategy¶
The Kriging Believer strategy replaces the conditional knowledge about the responses at the sites chosen within the last iterations by deterministic values equal to the expectation of the Kriging predictor. Keeping the same notations as previously, the strategy can be summed up as follows:

This sequential strategy delivers a q-points design and is computationally affordable since it relies on the analytically known EI, optimized in d dimensions. However, there is a risk of failure, since believing an OK predictor that overshoots the observed data may lead to a sequence that gets trapped in a non-optimal region for many iterations. We now propose a second strategy that reduces this risk.
Solution 2: The CL(Constant Liar) Heuristic Strategy¶
Let us now consider a sequential strategy in which the metamodel is updated (still without hyperparameter re-estimation) at each iteration with a value L exogenously fixed by the user, here called a ”lie”. The strategy referred to as the Constant Liar consists in lying with the same value L at every iteration: maximize EI (i.e. find xn+1), actualize the model as if y(xn+1) = L, and so on always with the same L ∈ R:

L should logically be determined on the basis of the values taken by y at X. Three values, min{Y}, mean{Y}, and max{Y} are considered here. The larger L is, the more explorative the algorithm will be, and vice versa.
We have simulated the method above. The following figure shows the result of using mean value liars to maximize q-EI. We find that the points we have taken have begun to be scattered.

Experiment¶
Branin-Hoo¶
The four optimization strategies presented in the last section are now compared on the Branin-Hoo function which is a classical test-case in global optimization.

The recommended values of a, b, c, r, s and t are: a = 1, b = 5.1 ⁄ (4π2), c = 5 ⁄ π, r = 6, s = 10 and t = 1 ⁄ (8π). This function has three global minimizers(-3.14, 12.27), (3.14, 2.27), (9.42, 2.47).
Next is the comparison of the q-EI associated with the q first points (q ∈ [1,10]) given by the constant liar strategies (min and max), 2000 q-points designs uniformly drawn for every q, and 2000 q-points LHS designs taken at random for every q.

As we can seen on figure, CL[max] and CL[min] offer very good q-EI results compared to random designs, especially for small values of q.
Gaussian Mixed Model function¶
We also compared the case of using parallel optimization and not using parallel optimization. A two-dimensional multimodal Gaussian Mixed distribution is used to simulate, the following is our result:
| concurrency=80 | concurrency=60 | concurrency=40 | concurrency=20 | concurrency=10 | |
|---|---|---|---|---|---|
| Without parallel optimization | avg = 0.4841 var = 0.1953 |
avg = 0.5155 var = 0.2219 |
avg = 0.5773 var = 0.2570 |
avg = 0.4680 var = 0.1994 |
avg = 0.2774 var = 0.1217 |
| With parallel optimization | avg = 0.2132 var = 0.0700 |
avg = 0.2177 var = 0.0796 |
avg = 0.1835 var = 0.0533 |
avg = 0.1671 var = 0.0413 |
avg = 0.1918 var = 0.0697 |
Note: The total number of samples per test is 240 (ensure that the budget is equal). The trials in each form were repeated 1000 times, the value is the average and variance of the best results in 1000 trials.
References¶
[1] James Bergstra, Remi Bardenet, Yoshua Bengio, Balazs Kegl. “Algorithms for Hyper-Parameter Optimization”. Link
[2] Meng-Hiot Lim, Yew-Soon Ong. “Computational Intelligence in Expensive Optimization Problems”. Link
[3] M. Jordan, J. Kleinberg, B. Scho¨lkopf. “Pattern Recognition and Machine Learning”. Link
Automatically tune systems with NNI¶
As computer systems and networking get increasingly complicated, optimizing them manually with explicit rules and heuristics becomes harder than ever before, sometimes impossible. Below are two examples of tuning systems with NNI. Anyone can easily tune their own systems by following them.
Please see this paper for more details:
Mike Liang, Chieh-Jan, et al. “The Case for Learning-and-System Co-design.” ACM SIGOPS Operating Systems Review 53.1 (2019): 68-74.
NNI review article from Zhihu: - By Garvin Li¶
The article is by a NNI user on Zhihu forum. In the article, Garvin had shared his experience on using NNI for Automatic Feature Engineering. We think this article is very useful for users who are interested in using NNI for feature engineering. With author’s permission, we translated the original article into English.
原文(source): 如何看待微软最新发布的AutoML平台NNI?By Garvin Li
01 Overview of AutoML¶
In author’s opinion, AutoML is not only about hyperparameter optimization, but also a process that can target various stages of the machine learning process, including feature engineering, NAS, HPO, etc.
02 Overview of NNI¶
NNI (Neural Network Intelligence) is an open source AutoML toolkit from Microsoft, to help users design and tune machine learning models, neural network architectures, or a complex system’s parameters in an efficient and automatic way.
Link: https://github.com/Microsoft/nni
In general, most of Microsoft tools have one prominent characteristic: the design is highly reasonable (regardless of the technology innovation degree). NNI’s AutoFeatureENG basically meets all user requirements of AutoFeatureENG with a very reasonable underlying framework design.
03 Details of NNI-AutoFeatureENG¶
The article is following the github project: https://github.com/SpongebBob/tabular_automl_NNI.
Each new user could do AutoFeatureENG with NNI easily and efficiently. To exploring the AutoFeatureENG capability, downloads following required files, and then run NNI install through pip.
 NNI treats AutoFeatureENG as a two-steps-task, feature generation exploration and feature selection. Feature generation exploration is mainly about feature derivation and high-order feature combination.
NNI treats AutoFeatureENG as a two-steps-task, feature generation exploration and feature selection. Feature generation exploration is mainly about feature derivation and high-order feature combination.
04 Feature Exploration¶
For feature derivation, NNI offers many operations which could automatically generate new features, which list as following :
count: Count encoding is based on replacing categories with their counts computed on the train set, also named frequency encoding.
target: Target encoding is based on encoding categorical variable values with the mean of target variable per value.
embedding: Regard features as sentences, generate vectors using Word2Vec.
crosscout: Count encoding on more than one-dimension, alike CTR (Click Through Rate).
aggregete: Decide the aggregation functions of the features, including min/max/mean/var.
nunique: Statistics of the number of unique features.
histsta: Statistics of feature buckets, like histogram statistics.
Search space could be defined in a JSON file: to define how specific features intersect, which two columns intersect and how features generate from corresponding columns.
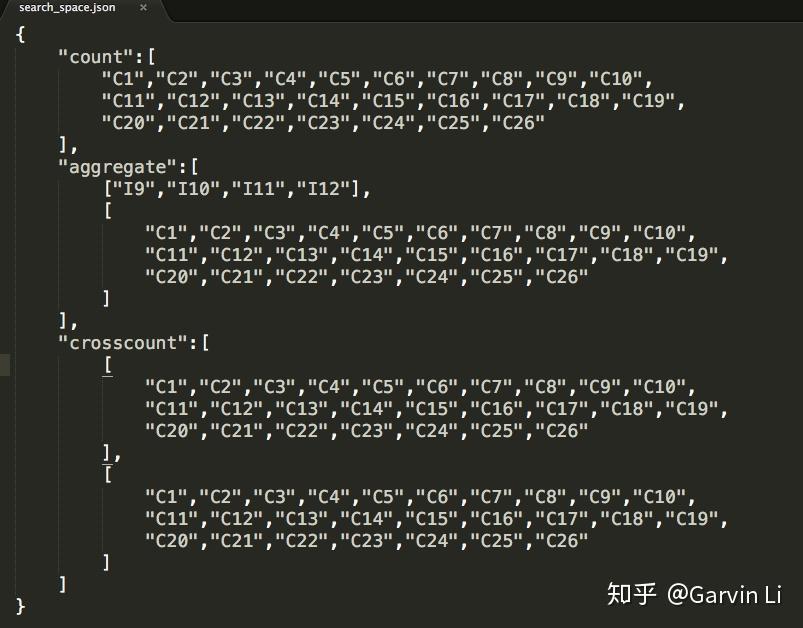
The picture shows us the procedure of defining search space. NNI provides count encoding for 1-order-op, as well as cross count encoding, aggerate statistics (min max var mean median nunique) for 2-order-op.
For example, we want to search the features which are a frequency encoding (valuecount) features on columns name {“C1”, …,” C26”}, in the following way:

we can define a cross frequency encoding (value count on cross dims) method on columns {“C1”,…,”C26”} x {“C1”,…,”C26”} in the following way:

The purpose of Exploration is to generate new features. You can use get_next_parameter function to get received feature candidates of one trial.
RECEIVED_PARAMS = nni.get_next_parameter()
05 Feature selection¶
To avoid feature explosion and overfitting, feature selection is necessary. In the feature selection of NNI-AutoFeatureENG, LightGBM (Light Gradient Boosting Machine), a gradient boosting framework developed by Microsoft, is mainly promoted.
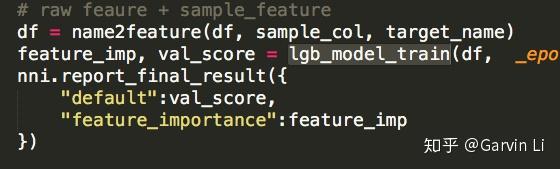
If you have used XGBoost or GBDT, you would know the algorithm based on tree structure can easily calculate the importance of each feature on results. LightGBM is able to make feature selection naturally.
The issue is that selected features might be applicable to GBDT (Gradient Boosting Decision Tree), but not to the linear algorithm like LR (Logistic Regression).

06 Summary¶
NNI’s AutoFeatureEng sets a well-established standard, showing us the operation procedure, available modules, which is highly convenient to use. However, a simple model is probably not enough for good results.
Suggestions to NNI¶
About Exploration: If consider using DNN (like xDeepFM) to extract high-order feature would be better.
About Selection: There could be more intelligent options, such as automatic selection system based on downstream models.
Conclusion: NNI could offer users some inspirations of design and it is a good open source project. I suggest researchers leverage it to accelerate the AI research.
Tips: Because the scripts of open source projects are compiled based on gcc7, Mac system may encounter problems of gcc (GNU Compiler Collection). The solution is as follows:
#brew install libomp
FAQ¶
This page is for frequent asked questions and answers.
tmp folder fulled¶
nnictl will use tmp folder as a temporary folder to copy files under codeDir when executing experimentation creation. When met errors like below, try to clean up tmp folder first.
OSError: [Errno 28] No space left on device
Cannot get trials’ metrics in OpenPAI mode¶
In OpenPAI training mode, we start a rest server which listens on 51189 port in NNI Manager to receive metrcis reported from trials running in OpenPAI cluster. If you didn’t see any metrics from WebUI in OpenPAI mode, check your machine where NNI manager runs on to make sure 51189 port is turned on in the firewall rule.
Segmentation Fault (core dumped) when installing¶
make: *** [install-XXX] Segmentation fault (core dumped)
Please try the following solutions in turn:
- Update or reinstall you current python’s pip like
python3 -m pip install -U pip - Install NNI with
--no-cache-dirflag likepython3 -m pip install nni --no-cache-dir
Job management error: getIPV4Address() failed because os.networkInterfaces().eth0 is undefined.¶
Your machine don’t have eth0 device, please set nniManagerIp in your config file manually.
Exceed the MaxDuration but didn’t stop¶
When the duration of experiment reaches the maximum duration, nniManager will not create new trials, but the existing trials will continue unless user manually stop the experiment.
Could not stop an experiment using nnictl stop¶
If you upgrade your NNI or you delete some config files of NNI when there is an experiment running, this kind of issue may happen because the loss of config file. You could use ps -ef | grep node to find the PID of your experiment, and use kill -9 {pid} to kill it manually.
Could not get default metric in webUI of virtual machines¶
Config the network mode to bridge mode or other mode that could make virtual machine’s host accessible from external machine, and make sure the port of virtual machine is not forbidden by firewall.
Could not open webUI link¶
Unable to open the WebUI may have the following reasons:
http://127.0.0.1,http://172.17.0.1andhttp://10.0.0.15are referred to localhost, if you start your experiment on the server or remote machine. You can replace the IP to your server IP to view the WebUI, likehttp://[your_server_ip]:8080- If you still can’t see the WebUI after you use the server IP, you can check the proxy and the firewall of your machine. Or use the browser on the machine where you start your NNI experiment.
- Another reason may be your experiment is failed and NNI may fail to get the experiment information. You can check the log of NNIManager in the following directory:
~/nni/experiment/[your_experiment_id]/log/nnimanager.log
Restful server start failed¶
Probably it’s a problem with your network config. Here is a checklist.
- You might need to link
127.0.0.1withlocalhost. Add a line127.0.0.1 localhostto/etc/hosts. - It’s also possible that you have set some proxy config. Check your environment for variables like
HTTP_PROXYorHTTPS_PROXYand unset if they are set.
NNI on Windows problems¶
Please refer to NNI on Windows
More FAQ issues¶
Help us improve¶
Please inquiry the problem in https://github.com/Microsoft/nni/issues to see whether there are other people already reported the problem, create a new one if there are no existing issues been created.
Contribute to NNI¶
Setup NNI development environment¶
NNI development environment supports Ubuntu 1604 (or above), and Windows 10 with Python3 64bit.
Installation¶
The installation steps are similar with installing from source code. But the installation links to code directory, so that code changes can be applied to installation as easy as possible.
1. Clone source code¶
git clone https://github.com/Microsoft/nni.git
Note, if you want to contribute code back, it needs to fork your own NNI repo, and clone from there.
2. Install from source code¶
Ubuntu¶
make dev-easy-install
Windows¶
powershell -ExecutionPolicy Bypass -file install.ps1 -Development
3. Check if the environment is ready¶
Now, you can try to start an experiment to check if your environment is ready. For example, run the command
nnictl create --config examples/trials/mnist-tfv1/config.yml
And open WebUI to check if everything is OK
4. Reload changes¶
Python¶
Nothing to do, the code is already linked to package folders.
TypeScript¶
- If
src/nni_manageris changed, runyarn watchunder this folder. It will watch and build code continually. Thennictlneed to be restarted to reload NNI manager. - If
src/webuiorsrc/nasuiare changed, runyarn startunder the corresponding folder. The web UI will refresh automatically if code is changed.
5. Submit Pull Request¶
All changes are merged to master branch from your forked repo. The description of Pull Request must be meaningful, and useful.
We will review the changes as soon as possible. Once it passes review, we will merge it to master branch.
For more contribution guidelines and coding styles, you can refer to the contributing document.
Contributing to Neural Network Intelligence (NNI)¶
Great!! We are always on the lookout for more contributors to our code base.
Firstly, if you are unsure or afraid of anything, just ask or submit the issue or pull request anyways. You won’t be yelled at for giving your best effort. The worst that can happen is that you’ll be politely asked to change something. We appreciate any sort of contributions and don’t want a wall of rules to get in the way of that.
However, for those individuals who want a bit more guidance on the best way to contribute to the project, read on. This document will cover all the points we’re looking for in your contributions, raising your chances of quickly merging or addressing your contributions.
Looking for a quickstart, get acquainted with our Get Started guide.
There are a few simple guidelines that you need to follow before providing your hacks.
Raising Issues¶
When raising issues, please specify the following:
- Setup details needs to be filled as specified in the issue template clearly for the reviewer to check.
- A scenario where the issue occurred (with details on how to reproduce it).
- Errors and log messages that are displayed by the software.
- Any other details that might be useful.
Submit Proposals for New Features¶
- There is always something more that is required, to make it easier to suit your use-cases. Feel free to join the discussion on new features or raise a PR with your proposed change.
- Fork the repository under your own github handle. After cloning the repository. Add, commit, push and sqaush (if necessary) the changes with detailed commit messages to your fork. From where you can proceed to making a pull request.
Contributing to Source Code and Bug Fixes¶
Provide PRs with appropriate tags for bug fixes or enhancements to the source code. Do follow the correct naming conventions and code styles when you work on and do try to implement all code reviews along the way.
If you are looking for How to develop and debug the NNI source code, you can refer to How to set up NNI developer environment doc file in the docs folder.
Similarly for Quick Start. For everything else, refer to NNI Home page.
Solve Existing Issues¶
Head over to issues to find issues where help is needed from contributors. You can find issues tagged with ‘good-first-issue’ or ‘help-wanted’ to contribute in.
A person looking to contribute can take up an issue by claiming it as a comment/assign their Github ID to it. In case there is no PR or update in progress for a week on the said issue, then the issue reopens for anyone to take up again. We need to consider high priority issues/regressions where response time must be a day or so.
Code Styles & Naming Conventions¶
- We follow PEP8 for Python code and naming conventions, do try to adhere to the same when making a pull request or making a change. One can also take the help of linters such as
flake8orpylint - We also follow NumPy Docstring Style for Python Docstring Conventions. During the documentation building, we use sphinx.ext.napoleon to generate Python API documentation from Docstring.
- For docstrings, please refer to numpydoc docstring guide and pandas docstring guide
- For function docstring, description, Parameters, and Returns/Yields are mandatory.
- For class docstring, description, Attributes are mandatory.
- For docstring to describe
dict, which is commonly used in our hyper-param format description, please refer to [RiboKit : Doc Standards
- Internal Guideline on Writing Standards](https://ribokit.github.io/docs/text/)
Documentation¶
Our documentation is built with sphinx, supporting Markdown and reStructuredText format. All our documentations are placed under docs/en_US.
- Before submitting the documentation change, please build homepage locally:
cd docs/en_US && make html, then you can see all the built documentation webpage under the folderdocs/en_US/_build/html. It’s also highly recommended taking care of every WARNING during the build, which is very likely the signal of a deadlink and other annoying issues. - For links, please consider using relative paths first. However, if the documentation is written in Markdown format, and:
- It’s an image link which needs to be formatted with embedded html grammar, please use global URL like
https://user-images.githubusercontent.com/44491713/51381727-e3d0f780-1b4f-11e9-96ab-d26b9198ba65.png, which can be automatically generated by dragging picture onto Github Issue Box. - It cannot be re-formatted by sphinx, such as source code, please use its global URL. For source code that links to our github repo, please use URLs rooted at
https://github.com/Microsoft/nni/tree/master/(mnist.py for example).
- It’s an image link which needs to be formatted with embedded html grammar, please use global URL like
ChangeLog¶
Release 1.7 - 7/8/2020¶
Major Features¶
Training Service¶
- Support AML(Azure Machine Learning) platform as NNI training service.
- OpenPAI job can be reusable. When a trial is completed, the OpenPAI job won’t stop, and wait next trial. refer to reuse flag in OpenPAI config.
- Support ignoring files and folders in code directory with .nniignore when uploading code directory to training service.
Neural Architecture Search (NAS)¶
Model Compression¶
- Improve Model Speedup: track more dependencies among layers and automatically resolve mask conflict, support the speedup of pruned resnet.
- Added new pruners, including three auto model pruning algorithms: NetAdapt Pruner, SimulatedAnnealing Pruner, AutoCompress Pruner, and ADMM Pruner.
- Added model sensitivity analysis tool to help users find the sensitivity of each layer to the pruning.
- Easy flops calculation for model compression and NAS.
- Update lottery ticket pruner to export winning ticket.
Examples¶
- Automatically optimize tensor operators on NNI with a new customized tuner OpEvo.
Built-in tuners/assessors/advisors¶
WebUI¶
- Support visualizing nested search space more friendly.
- Show trial’s dict keys in hyper-parameter graph.
- Enhancements to trial duration display.
Others¶
- Provide utility function to merge parameters received from NNI
- Support setting paiStorageConfigName in pai mode
Documentation¶
- Improve documentation for model compression
- Improve documentation and examples for NAS benchmarks.
- Improve documentation for AzureML training service
- Homepage migration to readthedoc.
Bug Fixes¶
- Fix bug for model graph with shared nn.Module
- Fix nodejs OOM when
make build - Fix NASUI bugs
- Fix duration and intermediate results pictures update issue.
- Fix minor WebUI table style issues.
Release 1.6 - 5/26/2020¶
Major Features¶
New Features and improvement¶
- Improve IPC limitation to 100W
- improve code storage upload logic among trials in non-local platform
- support
__version__for SDK version - support windows dev intall
Web UI¶
- Show trial error message
- finalize homepage layout
- Refactor overview’s best trials module
- Remove multiphase from webui
- add tooltip for trial concurrency in the overview page
- Show top trials for hyper-parameter graph
HPO Updates¶
- Improve PBT on failure handling and support experiment resume for PBT
NAS Updates¶
- NAS support for TensorFlow 2.0 (preview) TF2.0 NAS examples
- Use OrderedDict for LayerChoice
- Prettify the format of export
- Replace layer choice with selected module after applied fixed architecture
Model Compression Updates¶
- Model compression PyTorch 1.4 support
Training Service Updates¶
- update pai yaml merge logic
- support windows as remote machine in remote mode Remote Mode
Bug Fix¶
- fix dev install
- SPOS example crash when the checkpoints do not have state_dict
- Fix table sort issue when experiment had failed trial
- Support multi python env (conda, pyenv etc)
Release 1.5 - 4/13/2020¶
New Features and Documentation¶
Hyper-Parameter Optimizing¶
- New tuner: Population Based Training (PBT)
- Trials can now report infinity and NaN as result
Neural Architecture Search¶
- New NAS algorithm: TextNAS
- ENAS and DARTS now support visualization through web UI.
Model Compression¶
- New Pruner: GradientRankFilterPruner
- Compressors will validate configuration by default
- Refactor: Adding optimizer as an input argument of pruner, for easy support of DataParallel and more efficient iterative pruning. This is a broken change for the usage of iterative pruning algorithms.
- Model compression examples are refactored and improved
- Added documentation for implementing compressing algorithm
Training Service¶
- Kubeflow now supports pytorchjob crd v1 (thanks external contributor @jiapinai)
- Experimental DLTS support
Overall Documentation Improvement¶
- Documentation is significantly improved on grammar, spelling, and wording (thanks external contributor @AHartNtkn)
Fixed Bugs¶
- ENAS cannot have more than one LSTM layers (thanks external contributor @marsggbo)
- NNI manager’s timers will never unsubscribe (thanks external contributor @guilhermehn)
- NNI manager may exhaust head memory (thanks external contributor @Sundrops)
- Batch tuner does not support customized trials (#2075)
- Experiment cannot be killed if it failed on start (#2080)
- Non-number type metrics break web UI (#2278)
- A bug in lottery ticket pruner
- Other minor glitches
Release 1.4 - 2/19/2020¶
Major Features¶
Neural Architecture Search¶
- Support C-DARTS algorithm and add the example using it
- Support a preliminary version of ProxylessNAS and the corresponding example
- Add unit tests for the NAS framework
Model Compression¶
- Support DataParallel for compressing models, and provide an example of using DataParallel
- Support model speedup for compressed models, in Alpha version
Training Service¶
- Support complete PAI configurations by allowing users to specify PAI config file path
- Add example config yaml files for the new PAI mode (i.e., paiK8S)
- Support deleting experiments using sshkey in remote mode (thanks external contributor @tyusr)
WebUI¶
- WebUI refactor: adopt fabric framework
Others¶
- Support running NNI experiment at foreground, i.e.,
--foregroundargument innnictl create/resume/view - Support canceling the trials in UNKNOWN state
- Support large search space whose size could be up to 50mb (thanks external contributor @Sundrops)
Documentation¶
- Improve the index structure of NNI readthedocs
- Improve documentation for NAS
- Improve documentation for the new PAI mode
- Add QuickStart guidance for NAS and model compression
- Improve documentation for the supported EfficientNet
Bug Fixes¶
- Correctly support NaN in metric data, JSON compliant
- Fix the out-of-range bug of
randinttype in search space - Fix the bug of wrong tensor device when exporting onnx model in model compression
- Fix incorrect handling of nnimanagerIP in the new PAI mode (i.e., paiK8S)
Release 1.3 - 12/30/2019¶
Major Features¶
Neural Architecture Search Algorithms Support¶
- Single Path One Shot algorithm and the example using it
Model Compression Algorithms Support¶
- Knowledge Distillation algorithm and the example using itExample
- Pruners
- BNN Quantizer
Training Service¶
NFS Support for PAI
Instead of using HDFS as default storage, since OpenPAI v0.11, OpenPAI can have NFS or AzureBlob or other storage as default storage. In this release, NNI extended the support for this recent change made by OpenPAI, and could integrate with OpenPAI v0.11 or later version with various default storage.
Kubeflow update adoption
Adopted the Kubeflow 0.7’s new supports for tf-operator.
Release 1.2 - 12/02/2019¶
Major Features¶
- Feature Engineering
- New feature engineering interface
- Feature selection algorithms: Gradient feature selector & GBDT selector
- Examples for feature engineering
- Neural Architecture Search (NAS) on NNI
- New NAS interface
- NAS algorithms: ENAS, DARTS, P-DARTS (in PyTorch)
- NAS in classic mode (each trial runs independently)
- Model compression
- New model pruning algorithms: lottery ticket pruning approach, L1Filter pruner, Slim pruner, FPGM pruner
- New model quantization algorithms: QAT quantizer, DoReFa quantizer
- Support the API for exporting compressed model.
- Training Service
- Support OpenPAI token authentication
- Examples:
- Engineering Improvements
- For remote training service, trial jobs require no GPU are now scheduled with round-robin policy instead of random.
- Pylint rules added to check pull requests, new pull requests need to comply with these pylint rules.
- Web Portal & User Experience
- Support user to add customized trial.
- User can zoom out/in in detail graphs, except Hyper-parameter.
- Documentation
- Improved NNI API documentation with more API docstring.
Bug fix¶
- Fix the table sort issue when failed trials haven’t metrics. -Issue #1773
- Maintain selected status(Maximal/Minimal) when the page switched. -PR#1710
- Make hyper-parameters graph’s default metric yAxis more accurate. -PR#1736
- Fix GPU script permission issue. -Issue #1665
Release 1.1 - 10/23/2019¶
Major Features¶
- New tuner: PPO Tuner
- View stopped experiments
- Tuners can now use dedicated GPU resource (see
gpuIndicesin tutorial for details) - Web UI improvements
- Trials detail page can now list hyperparameters of each trial, as well as their start and end time (via “add column”)
- Viewing huge experiment is now less laggy
- More examples
- Model compression toolkit - Alpha release: We are glad to announce the alpha release for model compression toolkit on top of NNI, it’s still in the experiment phase which might evolve based on usage feedback. We’d like to invite you to use, feedback and even contribute
Fixed Bugs¶
- Multiphase job hangs when search space exhuasted (issue #1204)
nnictlfails when log not available (issue #1548)
Release 1.0 - 9/2/2019¶
Major Features¶
- Tuners and Assessors
- Support Auto-Feature generator & selection -Issue#877 -PR #1387
- Provide auto feature interface
- Tuner based on beam search
- Add Pakdd example
- Add a parallel algorithm to improve the performance of TPE with large concurrency. -PR #1052
- Support multiphase for hyperband -PR #1257
- Support Auto-Feature generator & selection -Issue#877 -PR #1387
- Training Service
- Support private docker registry -PR #755
- Engineering Improvements
- Python wrapper for rest api, support retrieve the values of the metrics in a programmatic way PR #1318
- New python API : get_experiment_id(), get_trial_id() -PR #1353 -Issue #1331 & -Issue#1368
- Optimized NAS Searchspace -PR #1393
- Unify NAS search space with _type – “mutable_type”e
- Update random search tuner
- Set gpuNum as optional -Issue #1365
- Remove outputDir and dataDir configuration in PAI mode -Issue #1342
- When creating a trial in Kubeflow mode, codeDir will no longer be copied to logDir -Issue #1224
- Web Portal & User Experience
- Show the best metric curve during search progress in WebUI -Issue #1218
- Show the current number of parameters list in multiphase experiment -Issue1210 -PR #1348
- Add “Intermediate count” option in AddColumn. -Issue #1210
- Support search parameters value in WebUI -Issue #1208
- Enable automatic scaling of axes for metric value in default metric graph -Issue #1360
- Add a detailed documentation link to the nnictl command in the command prompt -Issue #1260
- UX improvement for showing Error log -Issue #1173
- Documentation
- Update the docs structure -Issue #1231
- (deprecated) Multi phase document improvement -Issue #1233 -PR #1242
- Add configuration example
- WebUI description improvement -PR #1419
Bug fix¶
- (Bug fix)Fix the broken links in 0.9 release -Issue #1236
- (Bug fix)Script for auto-complete
- (Bug fix)Fix pipeline issue that it only check exit code of last command in a script. -PR #1417
- (Bug fix)quniform fors tuners -Issue #1377
- (Bug fix)’quniform’ has different meaning beween GridSearch and other tuner. -Issue #1335
- (Bug fix)”nnictl experiment list” give the status of a “RUNNING” experiment as “INITIALIZED” -PR #1388
- (Bug fix)SMAC cannot be installed if nni is installed in dev mode -Issue #1376
- (Bug fix)The filter button of the intermediate result cannot be clicked -Issue #1263
- (Bug fix)API “/api/v1/nni/trial-jobs/xxx” doesn’t show a trial’s all parameters in multiphase experiment -Issue #1258
- (Bug fix)Succeeded trial doesn’t have final result but webui show ×××(FINAL) -Issue #1207
- (Bug fix)IT for nnictl stop -Issue #1298
- (Bug fix)fix security warning
- (Bug fix)Hyper-parameter page broken -Issue #1332
- (Bug fix)Run flake8 tests to find Python syntax errors and undefined names -PR #1217
Release 0.9 - 7/1/2019¶
Major Features¶
- General NAS programming interface
- Add
enas-modeandoneshot-modefor NAS interface: PR #1201
- Add
- Gaussian Process Tuner with Matern kernel
- (deprecated) Multiphase experiment supports
- Added new training service support for multiphase experiment: PAI mode supports multiphase experiment since v0.9.
- Added multiphase capability for the following builtin tuners:
- TPE, Random Search, Anneal, Naïve Evolution, SMAC, Network Morphism, Metis Tuner.
- Web Portal
- Enable trial comparation in Web Portal. For details, refer to View trials status
- Allow users to adjust rendering interval of Web Portal. For details, refer to View Summary Page
- show intermediate results more friendly. For details, refer to View trials status
- Commandline Interface
nnictl experiment delete: delete one or all experiments, it includes log, result, environment information and cache. It uses to delete useless experiment result, or save disk space.nnictl platform clean: It uses to clean up disk on a target platform. The provided YAML file includes the information of target platform, and it follows the same schema as the NNI configuration file.
Bug fix and other changes¶
- Tuner Installation Improvements: add sklearn to nni dependencies.
- (Bug Fix) Failed to connect to PAI http code - Issue #1076
- (Bug Fix) Validate file name for PAI platform - Issue #1164
- (Bug Fix) Update GMM evaluation in Metis Tuner
- (Bug Fix) Negative time number rendering in Web Portal - Issue #1182, Issue #1185
- (Bug Fix) Hyper-parameter not shown correctly in WebUI when there is only one hyper parameter - Issue #1192
Release 0.8 - 6/4/2019¶
Major Features¶
- Support NNI on Windows for OpenPAI/Remote mode
- NNI running on windows for remote mode
- NNI running on windows for OpenPAI mode
- Advanced features for using GPU
- Run multiple trial jobs on the same GPU for local and remote mode
- Run trial jobs on the GPU running non-NNI jobs
- Kubeflow v1beta2 operator
- Support Kubeflow TFJob/PyTorchJob v1beta2
- General NAS programming interface
- Provide NAS programming interface for users to easily express their neural architecture search space through NNI annotation
- Provide a new command
nnictl trial codegenfor debugging the NAS code - Tutorial of NAS programming interface, example of NAS on MNIST, customized random tuner for NAS
- Support resume tuner/advisor’s state for experiment resume
- For experiment resume, tuner/advisor will be resumed by replaying finished trial data
- Web Portal
- Improve the design of copying trial’s parameters
- Support ‘randint’ type in hyper-parameter graph
- Use should ComponentUpdate to avoid unnecessary render
Bug fix and other changes¶
- Bug fix that
nnictl updatehas inconsistent command styles - Support import data for SMAC tuner
- Bug fix that experiment state transition from ERROR back to RUNNING
- Fix bug of table entries
- Nested search space refinement
- Refine ‘randint’ type and support lower bound
- Comparison of different hyper-parameter tuning algorithm
- Comparison of NAS algorithm
- NNI practice on Recommenders
Release 0.7 - 4/29/2018¶
Major Features¶
- Support NNI on Windows
- NNI running on windows for local mode
- New advisor: BOHB
- Support a new advisor BOHB, which is a robust and efficient hyperparameter tuning algorithm, combines the advantages of Bayesian optimization and Hyperband
- Support import and export experiment data through nnictl
- Generate analysis results report after the experiment execution
- Support import data to tuner and advisor for tuning
- Designated gpu devices for NNI trial jobs
- Specify GPU devices for NNI trial jobs by gpuIndices configuration, if gpuIndices is set in experiment configuration file, only the specified GPU devices are used for NNI trial jobs.
- Web Portal enhancement
- Decimal format of metrics other than default on the Web UI
- Hints in WebUI about Multi-phase
- Enable copy/paste for hyperparameters as python dict
- Enable early stopped trials data for tuners.
- NNICTL provide better error message
- nnictl provide more meaningful error message for YAML file format error
Bug fix¶
- Unable to kill all python threads after nnictl stop in async dispatcher mode
- nnictl –version does not work with make dev-install
- All trail jobs status stays on ‘waiting’ for long time on OpenPAI platform
Release 0.6 - 4/2/2019¶
Major Features¶
- Version checking
- check whether the version is consistent between nniManager and trialKeeper
- Report final metrics for early stop job
- If includeIntermediateResults is true, the last intermediate result of the trial that is early stopped by assessor is sent to tuner as final result. The default value of includeIntermediateResults is false.
- Separate Tuner/Assessor
- Adds two pipes to separate message receiving channels for tuner and assessor.
- Make log collection feature configurable
- Add intermediate result graph for all trials
Bug fix¶
- Add shmMB config key for OpenPAI
- Fix the bug that doesn’t show any result if metrics is dict
- Fix the number calculation issue for float types in hyperband
- Fix a bug in the search space conversion in SMAC tuner
- Fix the WebUI issue when parsing experiment.json with illegal format
- Fix cold start issue in Metis Tuner
Release 0.5.2 - 3/4/2019¶
Improvements¶
- Curve fitting assessor performance improvement.
Documentation¶
- Chinese version document: https://nni.readthedocs.io/zh/latest/
- Debuggability/serviceability document: https://nni.readthedocs.io/en/latest/Tutorial/HowToDebug.html
- Tuner assessor reference: https://nni.readthedocs.io/en/latest/sdk_reference.html
Bug Fixes and Other Changes¶
- Fix a race condition bug that does not store trial job cancel status correctly.
- Fix search space parsing error when using SMAC tuner.
- Fix cifar10 example broken pipe issue.
- Add unit test cases for nnimanager and local training service.
- Add integration test azure pipelines for remote machine, OpenPAI and kubeflow training services.
- Support Pylon in OpenPAI webhdfs client.
Release 0.5.1 - 1/31/2018¶
Improvements¶
- Making log directory configurable
- Support different levels of logs, making it easier for debugging
Documentation¶
- Reorganized documentation & New Homepage Released: https://nni.readthedocs.io/en/latest/
Bug Fixes and Other Changes¶
- Fix the bug of installation in python virtualenv, and refactor the installation logic
- Fix the bug of HDFS access failure on OpenPAI mode after OpenPAI is upgraded.
- Fix the bug that sometimes in-place flushed stdout makes experiment crash
Release 0.5.0 - 01/14/2019¶
Major Features¶
New tuner and assessor supports¶
- Support Metis tuner as a new NNI tuner. Metis algorithm has been proofed to be well performed for online hyper-parameter tuning.
- Support ENAS customized tuner, a tuner contributed by github community user, is an algorithm for neural network search, it could learn neural network architecture via reinforcement learning and serve a better performance than NAS.
- Support Curve fitting assessor for early stop policy using learning curve extrapolation.
- Advanced Support of Weight Sharing: Enable weight sharing for NAS tuners, currently through NFS.
Training Service Enhancement¶
- FrameworkController Training service: Support run experiments using frameworkcontroller on kubernetes
- FrameworkController is a Controller on kubernetes that is general enough to run (distributed) jobs with various machine learning frameworks, such as tensorflow, pytorch, MXNet.
- NNI provides unified and simple specification for job definition.
- MNIST example for how to use FrameworkController.
User Experience improvements¶
- A better trial logging support for NNI experiments in OpenPAI, Kubeflow and FrameworkController mode:
- An improved logging architecture to send stdout/stderr of trials to NNI manager via Http post. NNI manager will store trial’s stdout/stderr messages in local log file.
- Show the link for trial log file on WebUI.
- Support to show final result’s all key-value pairs.
Release 0.4.1 - 12/14/2018¶
Major Features¶
New tuner supports¶
- Support network morphism as a new tuner
Training Service improvements¶
- Migrate Kubeflow training service’s dependency from kubectl CLI to Kubernetes API client
- Pytorch-operator support for Kubeflow training service
- Improvement on local code files uploading to OpenPAI HDFS
- Fixed OpenPAI integration WebUI bug: WebUI doesn’t show latest trial job status, which is caused by OpenPAI token expiration
NNICTL improvements¶
- Show version information both in nnictl and WebUI. You can run nnictl -v to show your current installed NNI version
WebUI improvements¶
- Enable modify concurrency number during experiment
- Add feedback link to NNI github ‘create issue’ page
- Enable customize top 10 trials regarding to metric numbers (largest or smallest)
- Enable download logs for dispatcher & nnimanager
- Enable automatic scaling of axes for metric number
- Update annotation to support displaying real choice in searchspace
New examples¶
- FashionMnist, work together with network morphism tuner
- Distributed MNIST example written in PyTorch
Release 0.4 - 12/6/2018¶
Major Features¶
- Kubeflow Training service
- Support tf-operator
- Distributed trial example on Kubeflow
- Grid search tuner
- Hyperband tuner
- Support launch NNI experiment on MAC
- WebUI
- UI support for hyperband tuner
- Remove tensorboard button
- Show experiment error message
- Show line numbers in search space and trial profile
- Support search a specific trial by trial number
- Show trial’s hdfsLogPath
- Download experiment parameters
Others¶
- Asynchronous dispatcher
- Docker file update, add pytorch library
- Refactor ‘nnictl stop’ process, send SIGTERM to nni manager process, rather than calling stop Rest API.
- OpenPAI training service bug fix
- Support NNI Manager IP configuration(nniManagerIp) in OpenPAI cluster config file, to fix the issue that user’s machine has no eth0 device
- File number in codeDir is capped to 1000 now, to avoid user mistakenly fill root dir for codeDir
- Don’t print useless ‘metrics is empty’ log in OpenPAI job’s stdout. Only print useful message once new metrics are recorded, to reduce confusion when user checks OpenPAI trial’s output for debugging purpose
- Add timestamp at the beginning of each log entry in trial keeper.
Release 0.3.0 - 11/2/2018¶
NNICTL new features and updates¶
Support running multiple experiments simultaneously.
Before v0.3, NNI only supports running single experiment once a time. After this release, users are able to run multiple experiments simultaneously. Each experiment will require a unique port, the 1st experiment will be set to the default port as previous versions. You can specify a unique port for the rest experiments as below:
nnictl create --port 8081 --config <config file path>Support updating max trial number. use
nnictl update --helpto learn more. Or refer to NNICTL Spec for the fully usage of NNICTL.
API new features and updates¶
breaking change: nn.get_parameters() is refactored to nni.get_next_parameter. All examples of prior releases can not run on v0.3, please clone nni repo to get new examples. If you had applied NNI to your own codes, please update the API accordingly.
New API nni.get_sequence_id(). Each trial job is allocated a unique sequence number, which can be retrieved by nni.get_sequence_id() API.
git clone -b v0.3 https://github.com/microsoft/nni.git
nni.report_final_result(result) API supports more data types for result parameter.
It can be of following types:
- int
- float
- A python dict containing ‘default’ key, the value of ‘default’ key should be of type int or float. The dict can contain any other key value pairs.
New tuner support¶
- Batch Tuner which iterates all parameter combination, can be used to submit batch trial jobs.
New examples¶
A NNI Docker image for public usage:
docker pull msranni/nni:latest
New trial example: NNI Sklearn Example
New competition example: Kaggle Competition TGS Salt Example
Release 0.2.0 - 9/29/2018¶
Major Features¶
- Support OpenPAI Training Platform (See here for instructions about how to submit NNI job in pai mode)
- Support training services on pai mode. NNI trials will be scheduled to run on OpenPAI cluster
- NNI trial’s output (including logs and model file) will be copied to OpenPAI HDFS for further debugging and checking
- Support SMAC tuner (See here for instructions about how to use SMAC tuner)
- Support NNI installation on conda and python virtual environment
- Others
- Update ga squad example and related documentation
- WebUI UX small enhancement and bug fix
Release 0.1.0 - 9/10/2018 (initial release)¶
Initial release of Neural Network Intelligence (NNI).
Major Features¶
- Installation and Deployment
- Support pip install and source codes install
- Support training services on local mode(including Multi-GPU mode) as well as multi-machines mode
- Tuners, Assessors and Trial
- Support AutoML algorithms including: hyperopt_tpe, hyperopt_annealing, hyperopt_random, and evolution_tuner
- Support assessor(early stop) algorithms including: medianstop algorithm
- Provide Python API for user defined tuners and assessors
- Provide Python API for user to wrap trial code as NNI deployable codes
- Experiments
- Provide a command line toolkit ‘nnictl’ for experiments management
- Provide a WebUI for viewing experiments details and managing experiments
- Continuous Integration
- Support CI by providing out-of-box integration with travis-ci on ubuntu
- Others
- Support simple GPU job scheduling



\ Sort by:\ best rated\ newest\ oldest\
\\
Add a comment\ (markup):
\``code``, \ code blocks:::and an indented block after blank line